Lucene+nutch搜索引擎开发的目录 内核揭秘篇
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene+nutch搜索引擎开发的目录 内核揭秘篇相关的知识,希望对你有一定的参考价值。
参考技术A 4.1 网络蜘蛛原理
4.1.1 体系结构设计
4.1.2 访问策略与算法
4.1.3 效率优化与更新
4.1.4 蜘蛛访问规范
4.1.5 开源蜘蛛简介
4.2 Nutch网络蜘蛛
4.2.1 Nutch网络蜘蛛概述
4.2.2 Nutch抓取模式分类
4.2.3 抓取测试站点建立
4.3 Nutch局域网抓取
4.3.1 本地下载准备
4.3.2 启动下载过程
4.3.3 下载过程解析
4.3.4 下载多个网站
4.4 Nutch互联网抓取
4.4.1 下载列表获取
4.4.2 下载大量网站
4.5 Nutch抓取比较
4.6 Nutch结果检测
4.6.1 网页内容检索
4.6.2 使用Readdb获取摘要
4.6.3 使用SegRead读取分段
4.6.4 Luke工具使用
4.7 Nutch配置文件解析
4.8 Heritrix网络蜘蛛
4.8.1 Heritrix概述
4.8.2 Heritrix体系结构
4.8.3 Heritrix安装与使用
4.9 小结 5.1 文档索引原理
5.1.1 索引概述
5.1.2 索引基本结构
5.1.3 倒排索引原理
5.1.4 索引分类
5.1.5 高性能索引
5.2 Lucene索引器
5.2.1 Lucene索引介绍
5.2.2 Lucene索引结构
5.2.3 多文件索引结构
5.2.4 复合索引结构
5.3 Lucene索引实例
5.3.1 索引创建代码解析
5.3.2 索引创建器(IndexWriter)
5.3.3 索引管理器(IndexReader)
5.3.4 索引修改器(IndexModifier)
5.3.5 索引分析器(Analyzer)
5.4 Lucene索引操作
5.4.1 添加文本文件索引
5.4.2 创建Lucene增量索引
5.4.3 使用索引项删除文档
5.4.4 使用编号删除文档
5.4.5 压缩文档编号
5.4.6 索引文档更新
5.5 Lucene索引高级特性
5.5.1 选择索引域类型
5.5.2 索引参数优化
5.5.3 使用磁盘索引
5.5.4 使用内存索引
5.5.5 同步与锁机制
5.6 Lucene高级应用实例
5.6.1 创建本地搜索的索引
5.6.2 索引数据库记录
5.6.3 索引优化与合并
5.7 Nutch中的Lucene索引
5.8 小结 6.1 信息查询原理
6.1.1 信息查询概述
6.1.2 查询基本流程
6.1.3 查询结果显示
6.1.4 高性能查询
6.2 Lucene查询概述
6.2.1 Lucene查询操作基础
6.2.2 Lucene查询实例入门
6.2.3 查询工具IndexSearcher类
6.2.4 查询封装Query类
6.2.5 查询分析器QueryParser类
6.2.6 查询结果集Hits类
6.3 Lucene基本查询
6.3.1 Lucene查询Query对象
6.3.2 最小项查询TermQuery
6.3.3 区间范围搜索RangeQuery
6.3.4 逻1/4组合搜索BooleanQuery
6.3.5 字串前缀搜索PrefixQuery
6.3.6 短语搜索PhraseQuery
6.3.7 模糊搜索FuzzyQuery
6.3.8 通配符搜索WildcardQuery
6.3.9 位置跨度搜索SpanQuery
6.4 Lucene高级查询
6.4.1 索引内存检索
6.4.2 多关键字跨域检索
6.4.3 多检索器跨索引检索
6.5 Nutch中的Lucene查询
6.6 小结 7.1 搜索引擎文档排序原理
7.1.1 传统检索排序技术
7.1.2 向量模型排序局限
7.1.3 搜索引擎相关性排序
7.1.4 链接分析PageRank原理
7.1.5 搜索引擎排序流程
7.2 Lucene检索排序
7.2.1 Lucene相关性因素
7.2.2 Lucene相关排序流程
7.2.3 Lucene排序计算体系
7.2.4 Lucene排序控制方法
7.3 文档Boost加权排序
7.3.1 Lucene中Boost介绍
7.3.2 Boost值全文档排序
7.3.3 Boost值文档域排序
7.3.4 BoostingTermQuery排序
7.4 Sort对象检索排序
7.4.1 Sort对象概述
7.4.2 Sort对象相关性排序
7.4.3 Sort对象文档编号排序
7.4.4 Sort对象独立域排序
7.4.5 Sort对象联合域排序
7.4.6 Sort对象逆向排序
7.5 Lucene相关性公式
7.5.1 Lucene评分结果分析
7.5.2 Lucene排序公式
7.5.3 其他动态排序因子
7.6 Lucene自定义排序
7.6.1 自定义排序比较接口
7.6.2 自定义排序接口类实例
7.6.3 自定义排序结果测试实例
7.6.4 自定义排序测试结果
7.7 Nutch中的结果排序
7.7.1 Nutch排序因素
7.7.2 Nutch链接分析
7.7.3 Nutch相关度计算
7.8 小结 8.1 文档分析与中文分词原理
8.1.1 文档分析预处理概述
8.1.2 文档分析基本流程
8.1.3 中文分析处理中的分词
8.2 Lucene分析器内核原理
8.2.1 Lucene分析器原理
8.2.2 Analysis包简介
8.2.3 Analyzer类的组合结构
8.2.4 JavaCC构造分析器
8.2.5 StopAnalyzer内核代码分析
8.2.6 StandardAnalyzer内核代码分析
8.3 Lucene分析器应用模式
8.3.1 使用默认分析器建立索引
8.3.2 使用多种分析器建立索引
8.3.3 使用分析器检索查询
8.4 Lucene主要分析器应用实例
8.4.1 停用词分析器StopAnalyzer
8.4.2 标准分析器StandardAnalyzer
8.4.3 简单分析器SimpleAnalyzer
8.4.4 空格分析器WhitespaceAnalyzer
8.4.5 关键字分析器KeywordAnalyzer
8.5 TokenStream分词器内核分析
8.5.1 Tokenizer分词器
8.5.2 标准分词器StandardTokenizer
8.5.3 字符分词器CharTokenizer
8.5.4 空格分词器WhiteSpaceTokenizer
8.5.5 字母分词器LetterTokenizer
8.5.6 小写分词器LowerCaseTokenizer
8.6 TokenStream过滤器内核分析
8.6.1 TokenFilter过滤器
8.6.2 标准过滤器StandardFilter
8.6.3 停用词过滤器StopFilter
8.6.4 小写过滤器LowerCaseFilter
8.6.5 长度过滤器LengthFilter
8.6.6 词干过滤器PorterStemFilter
8.7 Lucene中文分词
8.7.1 中文分词基本原理方法
8.7.2 StandardAnalyzer分析器中文处理
8.7.3 CJKAnalyzer中文分析器
8.7.4 ChineseAnalyzer中文分析器
8.7.5 IK_CAnalyzer中文分析器
8.7.6 中科院ICTCLAS中文分词
8.7.7 JE中文分词
8.7.8 中文分词问题
8.8 Nutch分词和预处理
8.8.1 Nutch分析器
8.8.2 Nutch中文分词
8.9 小结 9.1 非结构化文本简介
9.1.1 非结构化文本概述
9.1.2 非结构化文本检索
9.2 html文档分析
9.2.1 主流HTML文档分析器
9.2.2 HTMLParser安装配置
9.2.3 HTMLParser的框架结构
9.3 HTMLParser应用实例
9.3.1 HTMLParser功能模式
9.3.2 HTMLParser内容解析方式
9.3.3 Visitor模式正文解析
9.3.4 Filter模式简单链接提取
9.3.5 Filter模式搜索链接提取
9.3.6 Lexer模式遍历文档
9.4 PDF文档分析
9.4.1 常用的PDF处理包
9.4.2 PDFBox安装配置
9.5 PDFBox应用实例
9.5.1 PDFBox提取文档内容
9.5.2 PDFBox文档内容索引
9.6 Office文档分析
9.6.1 常用Office文档处理包
9.6.2 使用POI安装与配置
9.6.3 POI原理与接口介绍
9.7 POI分析Office文档实例
9.7.1 POI处理Excel文档
9.7.2 POI处理Word文档
9.8 XML文档分析
9.8.1 主流XML文档分析器
9.8.2 JDOM分析器安装配置
9.8.3 xerces分析器安装配置
9.9 XML解析应用实例
9.9.1 使用JDOM分析XML 文档
9.9.2 使用xerces分析XML 文档
9.10 Nutch文档处理
9.11 小结 10.1 分布式检索与缓存
10.1.1 分布式搜索引擎现状
10.1.2 分布式搜索引擎原理
10.1.3 搜索引擎缓存现状
10.1.4 搜索引擎缓存原理
10.2 Nutch与分布式检索
10.2.1 Google分布式文件系统
10.2.2 MapReduce系统介绍
10.2.3 Hadoop分布式文件系统
10.2.4 Nutch分布式文件系统
10.2.5 Nutch分布式检索概述
10.2.6 Nutch分布式检索器
10.3 Lucene分布式检索
10.3.1 Socket通信基础
10.3.2 Lucene索引服务器
10.4 Nutch与搜索缓存
10.5 开源系统缓存系统
10.6 小结
nutch和solr建立搜索引擎基础(单机版)
Nutch[1] 是一个开源Java实现的搜索引擎,它提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。
Solr[2] 是一个基于Lucene的全文搜索服务器,它对外提供类似于Web-service的API查询接口,是一款非常优秀的全文搜索引擎。
为什么要整合nutch和solr?
简单地讲,nutch重在提供数据源采集(Web爬虫)能力,轻全文搜索(lucene)能力;solr是lucene的扩展,亦是nutch的全文搜索的扩展。重在将nutch的爬取结果,通过其对外提供检索服务。
版本选择
1. nutch-1.13
支持hadoop,可以通过hadoop,获得分布式爬虫的能力。本文重点介绍nutch的原力,关于分布式爬虫,将在后续章节中介绍。另外,nutch-2.x系列支持hbase,可以根据自身的需要灵活选择。需要说明的是两版的用法是不同的,nutch-2.x要更为复杂。在使用nutch-2.x之前,最好具备nutch-1.x的基础。
2. Solr-6.6.0
截止发稿时是最新版本,可参考官网的解释,这里没什么要说的。
安装环境准备
1. 系统环境
Ubuntu14.04x64 或 Centos6.5x64, 应用程序采用二进制安装,不要求编译环境
2. java环境
vim /etc/profile
# set for java
export JAVA_HOME=/opt/jdk1.8.0_111 #二进制包已经解压安装到该路径
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export _JAVA_OPTIONS="Xmx2048m XX:MaxPermSize=512m Djava.awt.headless=true"注:java的安装方法选择二进制包即可,本文不再赘述
3. nutch+solr环境
vim /etc/profile
export NUTCH_RUNTIME_HOME='/opt/apache-nutch-1.13'
export PATH=$NUTCH_RUNTIME_HOME/bin:$PATH
export APACHE_SOLR_HOME='/opt/solr-6.6.0' #单引号不能少
export PATH=$APACHE_SOLR_HOME/bin:$PATH
export CLASSPATH=.:$CLASSPATH:$APACHE_SOLR_HOME/server/libsource /etc/profile #加载到环境
nutch的安装(二进制包)
wget http://mirrors.hust.edu.cn/apache/nutch/1.13/apache-nutch-1.13-bin.tar.gz
cat apache-nutch-1.13-bin.tar.gz |(cd /opt; tar xzfp -)
nutch -help #注:如果执行结果不正常,执行`source /etc/profile`和检查该文件的内容solr的安装
wget http://mirror.bit.edu.cn/apache/lucene/solr/6.6.0/solr-6.6.0.tgz
cat solr-6.6.0.tgz |(cd /opt; tar xzfp -)
solr status #注:如果执行结果不正常,执行`source /etc/profile`和检查该文件的内容
No Solr nodes are running.
#启动solr服务
solr start -force #-force:强制以root身份执行,生产环境请勿使用该参数
#停止solr服务
solr stopsolr的配置
cd ${APACHE_SOLR_HOME}
cp -r server/solr/configsets/basic_configs server/solr/configsets/nutch
cp conf/schema.xml server/solr/configsets/nutch/conf
mv server/solr/configsets/nutch/conf/managed-schema server/solr/configsets/nutch/conf/managed-schema.backup
#启动solr服务solr start
#创建nutch coresolr create -c nutch -d server/solr/configsets/nutch/conf/ -force #-force:强制以root身份执行,生产环境请勿使用该参数
创建过程并非一帆风顺,整个过程充满了各种bug,从这个角度考虑,生产环境中有必要更换到solr的稳定版,好在这些坑已经趟过:
问题1:Caused by: Unknown parameters: {enablePositionInc rements=true}
具体信息:
Copying configuration to new core instance directory:
/opt/solr-6.6.0/server/solr/nutch
Creating new core 'nutch' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=nutch&instanceDir=nutch
ERROR: Error CREATEing SolrCore 'nutch': Unable to create core [nutch] Caused by: Unknown parameters: {enablePositionIncrements=true}
解决办法:
vim server/solr/configsets/nutch/conf/schema.xml 找到并去掉enablePositionIncrements=true
问题2:ERROR: Error CREATEing SolrCore 'nutch': Unable to create core [nutch] Caused by: defaultSearchField has been deprecated and is incompatible with configs with luceneMatchVersion >= 6.6.0. Use 'df' on requests instead.
解决办法:
vim server/solr/configsets/nutch/conf/solrconfig.xml 将luceneMatchVersion版本修改为6.2.0
问题3:org.apache.solr.common.SolrException: fieldType 'booleans' not found in the schema
解决办法:
vim /opt/solr-6.6.0/server/solr/configsets/nutch/conf/solrconfig.xml
找到booleans,替换成boolean,如下:
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">boolean</str>
</lst>
Then it will work..
问题3以后,会发生多起类似事件,如下:
ERROR: Error CREATEing SolrCore 'nutch': Unable to create core [nutch] Caused by: fieldType 'tdates' not found in the schema
ERROR: Error CREATEing SolrCore 'nutch': Unable to create core [nutch] Caused by: fieldType 'tlongs' not found in the schema
ERROR: Error CREATEing SolrCore 'nutch': Unable to create core [nutch] Caused by: fieldType 'tdoubles' not f ound in the schema
参照问题3的方法,一次性去掉''中关键字的复数形式即可。
问题4:ERROR:
Core 'nutch' already exists!
Checked core existence using Core API command:
http://localhost:8983/solr/admin/cores?action=STATUS&core=nutch
解决办法:
solr delete -c nutch #删除core 'nutch'
如果删除完,还提示这个错误,这是由于每次修改完配置文件,需要重启下solr服务,更新下状态。
最终的执行结果:
solr create -c nutch -d server/solr/configsets/nutch/conf/ -force
Copying configuration to new core instance directory:
/opt/solr-6.6.0/server/solr/nutch
Creating new core 'nutch' using command:
http://localhost:8983/solr/admin/cores?action=CREATE&name=nutch&instanceDir=nutch
{ "responseHeader":{ "status":0, "QTime":3408}, "core":"nutch"}
执行成功!
在浏览器中访问
http://localhost:8983/solr/#/可以看到名称为nutch的coresolr的安全设置
1. realm.properties
cd /opt/solr-6.6.0/server
cat etc/realm.properties
## 这个文件定义用户名,密码和角色
## 格式如下
# <username>: <password>[,<rolename> ...]
##userName: password,role
yourname: yourpass,admin2. solr-jetty-context.xml
cat contexts/solr-jetty-context.xml
<?xml version="1.0"?><!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"><Configure class="org.eclipse.jetty.webapp.WebAppContext"> <Set name="contextPath"><Property name="hostContext" default="/solr"/></Set> <Set name="war"><Property name="jetty.base"/>/solr-webapp/webapp</Set> <Set name="defaultsDescriptor"><Property name="jetty.base"/>/etc/webdefault.xml</Set> <Set name="extractWAR">false</Set> <Get name="securityHandler"> <Set name="loginService"> <New class="org.eclipse.jetty.security.HashLoginService"> <Set name="name">Solr Admin Access</Set> <Set name="config"><SystemProperty name="jetty.home" default="."/>/etc/realm.properties</Set> </New> </Set> </Get></Configure>3. WEB-INF/web.xml
vim solr-webapp/webapp/WEB-INF/web.xml <!-- Get rid of error message --> <security-constraint> ... </security-constraint> <security-constraint> <web-resource-collection> <web-resource-name>Solr auth enticated application</web-resource-name> <!--描述--> <url-pattern>/</url-pattern> <!-- 验证的网页的位置--> </web-resource-collection> <auth-constraint> <role-name>admin</role-name> <!-- 验证的角色,别写成用户名,如有多个角色可以写多个role-name 标签--> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <!-- 关键--> <realm-name>Solr Admin Access</realm-name> </login-config></web-app>
重启solr服务 solr stop && solr start -force 在浏览器中访问solr http://localhost:8983/solr/nutch/ 可以看到要求登录的界面nutch的配置
以爬取http://nutch.apache.org站点为例,配置如下:
1. 配置nutch-site.xml
vim $NUTCH_RUNTIME_HOME/conf/nutch-site.xml<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value></property>#配置indexer-solr插件
#我的方法是替换indexer-elastic为indexer-solr插件
sed -i 's/indexer-elastic/indexer-solr/g' $NUTCH_RUNTIME_HOME/conf/nutch-site.xml
#注意:官方文档不是像我这样做的,请按照我的方法配置,或者注释掉indexer-elastic,否则会深受其害,踩坑过程后面会说2. 建立URL列表
#为方便修改配置文件,选择conf文件夹作为数据的存储路径
cd $NUTCH_RUNTIME_HOME/conf
mkdir -p urls #存储要爬取的URLS列表,每行只写一个url,可以多行
cd urls && echo 'http://nutch.apache.org/' > seed.txt #地址可以是静态的链接,也可以是动态的链接3. 设置url的正则匹配规则
vim regex-urlfilter.txt
将光标移到文件末尾,将下列内容:# accept anything else
+.
替换为:# accept anything else+^http://([a-z0-9]*\.)*nutch.apache.org/ #这将包含带有域名前缀的url,比如,http://3w.nutch.apache.org4. 允许抓取动态内容
替换:
# skip URLs ### 3. containing certain characters as probable queries, etc.
-[?*!@=]
为:
# accept URLs containing certain characters as probable queries, etc.
+[?=&]注: conf下有各种配置文件,涉及各种爬取规则和正则过滤器。将在后续的文章中详细说明
爬取和检索的过程
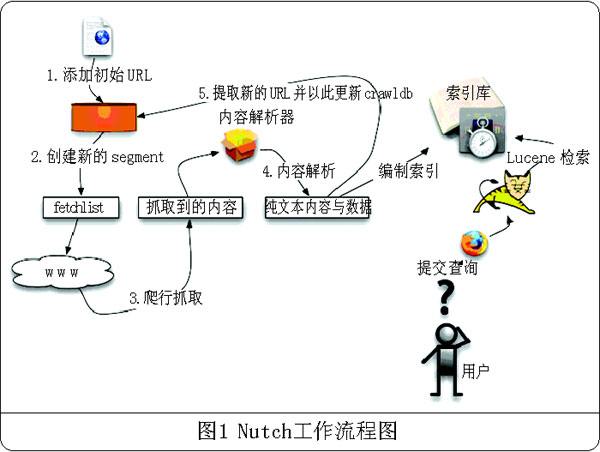
1. nutch爬取程序的概念组成
抓取程序自动在用户指定目录下面建立爬取目录,其目录下可以看到crawldb,segments,linkdb子目录
1. crawldb(爬虫数据库)
crawldb目录下面存放下载的URL,以及下载的日期、过期时间
2. linkdb-链接数据库
linkdb目录存放URL的关联关系,是下载完成后分析时创建的,通过这个关联关系可以实现类似google的pagerank功能
3. segments-一组分片
segments目录存储抓取的页面,这些页面是根据层级关系分片的。既segments下面子目录的个数与获取页面的层数有关系,如果指定“-depth”参数是10层,这个目录下就有10层,结构清晰并防止文件过大。
segments目录里面有6个子目录,分别是:
“crawl_generate” 生成要获取的一组URL的名字,既生成待下载的URL的集合
“crawl_fetch” 包含获取每个UR L的状态
”content“ 包含从每个URL检索的原始内容
“parse_text” 包含每个URL的解析文本(存放每个解析过的URL的文本内容)
“parse_data” 包含从每个URL分析的外部链接和元数据
“crawl_parse” 包含用于更新crawldb的outlink URL(外部链接库)2. nutch的爬取流程说明
爬取过程包括
injector -> generator -> fetcher -> parseSegment -> updateCrawleDB -> Invert links -> Index -> DeleteDuplicates -> IndexMerger
1. 根据之前建好的URL列表文件,将URL集注入crawldb数据库---inject
2. 根据crawldb数据库创建抓取列表---generate
3. 执行抓取,获取网页信息---fetch
4. 执行解析,解析网页信息---parse
5. 更新数据库,把获取到的页面信息存入数据库中---updatedb
6. 重复进行2~4的步骤,直到预先设定的抓取深度。---这个循环过程被称为“产生/抓取/更新”循环
7. 根据sengments的内容更新linkdb数据库---invertlinks
8. 建立索引---index3. solr查询流程包括
用户通过用户接口进行查询操作
将用户查询转化为solr查询
从索引库中提取满足用户检索需求的结果集
爬取和检索的实例
1. Inject
nutch inject crawl/crawldb urls
2. Generate
nutch generate crawl/crawldb crawl/segments
3. Fetching
s1=`ls -d crawl/segments/2* | tail -1`
echo $s1
nutch fetch $s14. Parse
nutch parse $s1
5. updatedb
nutch updatedb crawl/crawldb $s1
6. 重复2-4的过程,抓取下一层页面
演示过程中,为了节约时间,我们约定一个参数,只抓取前 top 1000 的页面
nutch generate crawl/crawldb crawl/segments -topN 1000
s2=`ls -d crawl/segments/2* | tail -1`
echo $s2
nutch fetch $s2
nutch parse $s2
nutch updatedb crawl/crawldb $s27. 重复2-4的过程,抓取下下层的页面
同样只取前1000个页面进行抓取
s3=`ls -d crawl/segments/2* | tail -1`
echo $s3
nutch fetch $s3
nutch parse $s3
nutch updatedb crawl/crawldb $s3 这样我们总共抓取了三个层级深度的页面,
ls crawl/segments/
20170816191100 20170816191415 201708161921008. Invertlinks
nutch invertlinks crawl/linkdb -dir crawl/segments
9. Indexing into Apache Solr
nutch index -Dsolr.server.url=http://用户名:密码@localhost:8983/solr/nutch crawl/crawldb/ -linkdb crawl/linkdb/ crawl/segments/20170816191100/ -filter -normalize -deleteGone
#这里的“用户名:密码”是solr的jetty下的
值得一提的是,如果按照官方标准语法,上面命令会变为:
nutch index -Dsolr.auth.username="yourname" -Dsolr.auth.password="yourpassword" -Dsolr.server.url=http://localhost:8983/solr/nutch crawl/crawldb/ -linkdb crawl/linkdb/ crawl/segments/20170816191100/ -filter -normalize -deleteGone
这里会提示语法错误,在官网和google上还没有更好的解决办法。我已经把上面的方法更新到http://lucene.472066.n3.nabble.com/Nutch-authentication-problem-to-solr-td4251336.html#a4351038
可能其她版本没有这个问题10. 推送solr index
nutch index -Dsolr.server.url=http://localhost:8983/solr/nutch crawl/crawldb/ -linkdb crawl/linkdb/ crawl/segments/20170816191100/ -filter -normalize -deleteGone
Segment dir is co mplete: crawl/segments/20170816191100.Indexer: starting at 2017-08-17 18:22:26Indexer: deleting gone documents: trueIndexer: URL filtering: trueIndexer: URL normalizing: trueActive IndexWriters :SOLRIndexWriter
solr.server.url : URL of the SOLR instance
solr.zookeeper.hosts : URL of the Zookeeper quorum
solr.commit.size : buffer size when sending to SOLR (default 1000)
solr.mapping.file : name of the mapping file for fields (default solrindex-mapping.xml)
solr.auth : use authentication (default false)
solr.auth.username : username for authentication
solr.auth.password : password for authentication
Indexing 1/1 documents
Deleting 0 documentsIndexer: number of documents indexed, deleted, or skipped:Indexer: 1 indexed (add/update)Indexer: finished at 2017-08-17 18:22:32, elapsed: 00:00:0511. 在solr上查询
在浏览器中访问solr
http://localhost:8983/solr/
12. 通过脚本自动完成1-10
crawl -i -D solr.server.url=http://用户名:密码@localhost:8983/solr/ urls/ crawl/ 2
参考
https://wiki.apache.org/nutch/
https://wiki.apache.org/nutch/NutchTutorial#Install_Nutch
https://wiki.apache.org/solr/
以上是关于Lucene+nutch搜索引擎开发的目录 内核揭秘篇的主要内容,如果未能解决你的问题,请参考以下文章