Lucene初探之索引文件的基本类型与基本规则
Posted Derrick_gu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene初探之索引文件的基本类型与基本规则相关的知识,希望对你有一定的参考价值。
Lucene初探之索引文件的基本类型与基本规则
之前我们说过,索引文件是类似数据库一般,它是将分布在不同地方的数据按照一定的规则抽取出来,加以重新组织,使其成为结构化的数据,最终按照一定的特殊规则存储起来以方便查询的。既然是类似数据库一般的存储数据,那么就像数据库有一定的数据类型一般,Lucene索引文件它也有自己的特定的存储类型。
- Byte:最基本的类型,所占空间为8个bit;
- UInt32:由4个Byte组成;
- UInt64:由8个Byte组成;
VInt:
- 可变的整形,它包含N个比特,对于每一个Byte,其后七位用来存储数值,第一位表示是否还有其他的Byte,0为没有,1为有;
- 在前面的Byte表示的是低位数值,后面的byte表示高位数值;
Chars:UTF8编码的系列Byte组成的字符;
- String:字符串,由VInt类型和Chars共同组成,首先是用VInt来表示此字符串,然后是一系列的Chars字符;
| Value | FirstByte | SecondByte | ThirdByte |
|---|---|---|---|
| 0 | 00000000 | ||
| 1 | 00000001 | ||
| 2 | 00000002 | ||
| …… | |||
| 127 | 01111111 | ||
| 128 | 10000000 | 00000001 | |
| 129 | 10000001 | 00000001 | |
| …… | |||
| 16.383 | 11111111 | 01111111 | |
| 16.384 | 10000000 | 10000000 | 0000001 |
| 16.385 | 10000001 | 10000000 | 0000001 |
有了基本的存储类型之后,Lucene索引文件下面要做的就是如何去高效地存储相关索引数据,使得其占用空间小,访问速度快速等,而要做到这些,需要在存储方式上使用一些特殊的技巧。
这些技巧概况起来大概有四种:
- 前缀后缀规则
- Lucene在保存词典信息的时候是按照词典顺序排列的,而词典的特性想必大家都清楚,这导致许多前缀相同的词被相邻存储,前缀后缀就是当数个相邻的词有共同的前缀或者后缀时,后面的词只保存前缀在最前面一个词的位置偏移和除了相同前缀之后的字符串。
- 差值规则
- 在反向索引中,Lucene索引文件中保存了大量的整型数据,例如词的ID和所属文档位置,而整型数值是以VInt类型存储的,它的存储规则如上方的表格所示,所以,当存在大量的整型数值的时候,每个整型数值所占的Byte会越来越多;结合上一个前缀后缀的规则,这里可以以这样一种规则来减少不必要的存储空间浪费:当存在两个及以上的连续整型数值相邻存储时,后一个整型数值只保存和前一个数值的差值;
- 或然跟随规则
- Lucene中存在许多这种情况:某个值后面可能存在B,也可能不存在,这需要一个标记位来表示,为了不让这些标记位白白地占据一个8个bit的1Byte空间,Lucene采取使用一个Bit空间来代替直接使用一个Byte空间;VInt就是最典型的例子;
- 跳跃表规则
- 为了更快速地查询定位到文档的存储位置,Lucene采用了跳跃表的数据结构,这种数据结构的特征是:
- 按顺序排列元素,比如按字典顺序排序或者按照数值大小排序;
- 有预先配置好的间隔;
- 层次分明,不同层次的元素配合相应的间隔数构成的元素列表组成了它的上一个层级;
- 为了更快速地查询定位到文档的存储位置,Lucene采用了跳跃表的数据结构,这种数据结构的特征是:
通过采用跳跃表数据结构,Lucene的查询效率得到了极大地提高,举个例子:
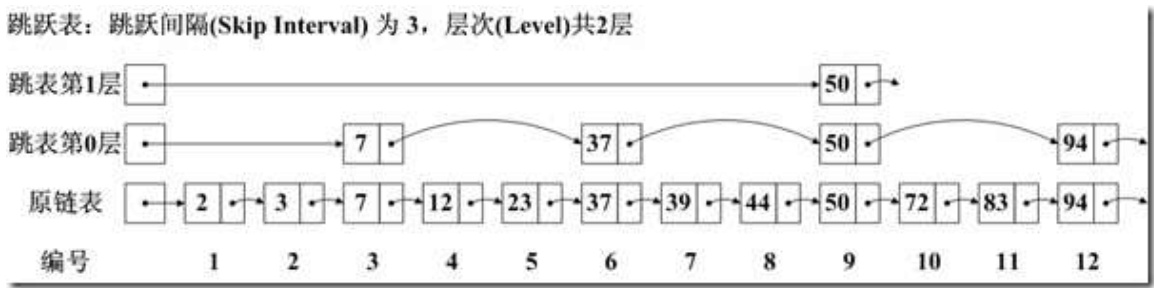
假设我们要查询数值72,如果按顺序查询的话,我们要遍历2、3、7、12、23、37、39、44、50、72一共10个元素,但是采用跳跃表数据结构之后,我们只要首先查询第一次50,发现72大于50,然后再访问第二层的94,发现94比72大,于是我们再访问底层数据的50后面一个元素,也就是72,总共访问了3个数值,访问速度大大加快。这种方法如果扩展开的话,其实就是类似二分法,都是采用两面夹逼的思想来快速地查询元素。
下一篇我们将正式去剖析Lucene内部存储的具体实现。
以上是关于Lucene初探之索引文件的基本类型与基本规则的主要内容,如果未能解决你的问题,请参考以下文章