为什么不能使用 datax 直接读写 hive acid 事务表?
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么不能使用 datax 直接读写 hive acid 事务表?相关的知识,希望对你有一定的参考价值。
为什么不能使用 datax 直接读写 hive acid 事务表?
1. 前言
从技术发展趋势的角度来看,ACID事务表提供了多种新特性新功能,是 HIVE社区推荐的HIVE表格式,且在 CDH/CDP/TDH 等大数据平台的主流版本中均已经提供了支持。 在次背景下,目前我司大数据相关产品和项目,已经在部分场景下开始了探索使用 HIVE ACID事务表。 在此跟大家分享一个 HIVE ACID 事务表的相关问题,希望对大家有所帮助。
2. 从一个 HIVE SQL 报错聊起
某线上 HIVE SQL 应用,关联查询多个事务表时报错,报错信息如下:
ERROR : FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed due to task failures: [Error 30022]: Must use HiveInputFormat to read ACID tables (set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat)
INFO : Completed executing command(queryId=hive_20220606152200_54458918-d42c-445e-8e87-96f75eaeb22f); Time taken: 27.143 seconds
Error: Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed due to task failures: [Error 30022]: Must use HiveInputFormat to read ACID tables (set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat) (state=42000,code=3)
3. “Must use HiveInputFormat to read ACID tables” 报错的底层原因
经排查发现,上述事务表底层的ORC 文件是使用 datax 直接同步过来的,而事务表对表底层在存储系统中的文件目录层次结构,文件名,以及文件格式,都有一套自己的规范,使用datax直接同步文件一般肯定会违反该规范,在后续查询使用时就会出现各种奇怪的问题,所以不能使用 datax 直接同步数据到事务表对应的hdfs目录下。
4. HIVE ACID 事务表的技术细节
为了在 HDFS 文件系统特性的基础上提供事务表的 ACID 语义(HDFS不支持对文件的原地更新,在APPEND追加写入文件时也不支持对该文件并发读取时的数据一致性),HIVE 对 ACID 事务表(或表分区)底层的文件,做了类似 deltalake/hudi/iceberg 一样的精细化管理,对底层文件的目录结构,文件名,和文件格式,都有一套自己的规范。
4.1 首先是文件目录层次结构规范
-
每个表或表分区对应一个 HDFS 目录; -
表或表分区目录底层又包含两类子目录,一类是 base 子目录,一类是 delta 子目录; -
表或表分区的大部分数据,都以文件形式存储在 base 子目录下; -
每次对表或表分区的增删改操作,都对应一个事务,都会创建一个对应的 delta 子目录,并将这些增量操作产生的数据,以文件形式存储在该 delta 子目录下; -
读取表或表分区数据时,会合并 base 子目录和 delta子目录下的所有文件,以呈现完整的数据;
4.2 其次是文件名规范
-
表底层BASE子目录名称类似 base_0000003_v0011148,其中中间部分对应创建该子目录的事务操作的TransactionId; -
表底层DELTA 子目录名称类似(对应 insert/update操作): delta_0000001_0000003_ v0011147,其中中间两部分对应创建该子目录的事务操作的最小和最大TransactionId;(insert/update操作生成的delta文件的最小和最大TransactionId是一致的,compaction操作生成的 delta文件的最小和最大TransactionId分别对应 compaction的一系列 delta文件的最小和最大TransactionId); -
表底层DELTA 子目录名称类似(对应 delete操作):delete_delta_0000001_0000003_ v0011147,其中中间两部分对应创建该子目录的事务操作的最小和最大TransactionId;(delete操作生成的delete_delta文件的最小和最大TransactionId是一致的,compaction操作生成的 delta文件的最小和最大TransactionId分别对应 compaction的一系列 delete_delta文件的最小和最大TransactionId); -
子目录底层的文件名,类似bucket_00000或bucket_00000_0;(不管表是否分桶,文件名都是该格式;hive2.x和hive3.x新旧版本文件名格式略有不同)
4.3 最后是文件格式规范
-
ACID事务表底层的文件,都是以 orc 格式存储的; -
ORC 文件包含的字段,除了ACID事务表中正常的业务字段,还包含5个元数据字段:operation:int,originalTransaction:bigint,bucket:int,rowId:bigint,currentTransaction:bigint 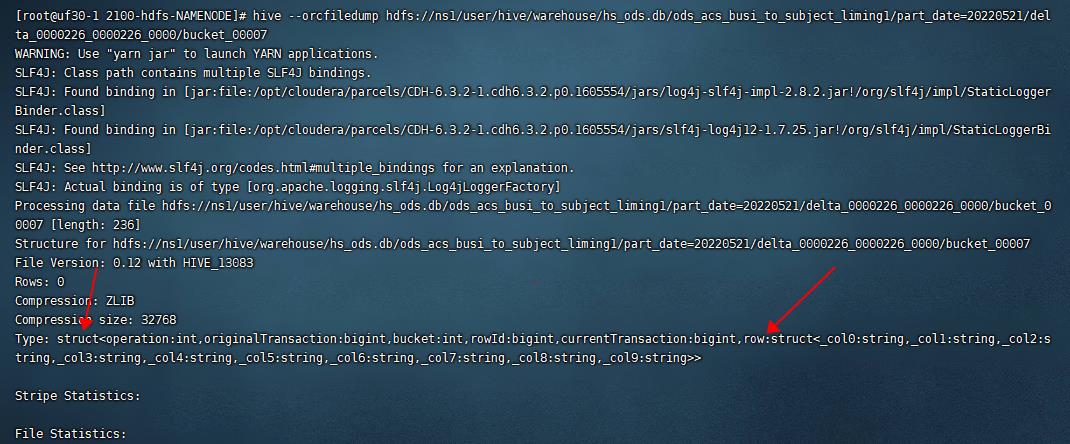
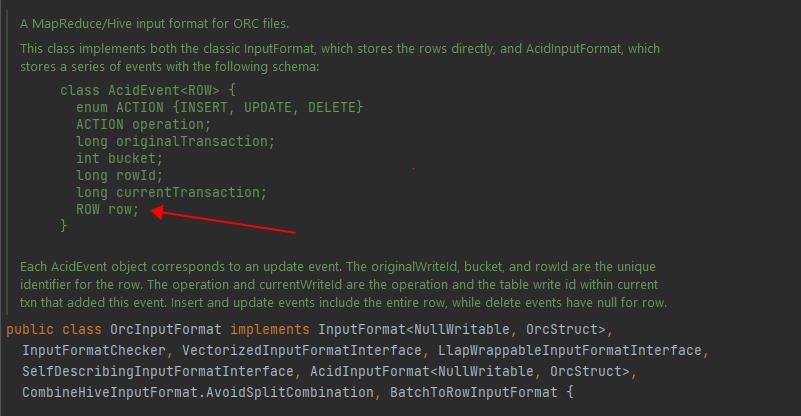
5 总结
正是因为 HIVE 对 ACID 事务表(或表分区)底层文件的目录结构,文件名,和文件格式的上述规范,所以我们不能直接读写操作 ACID 事务表底层的文件,正如我们不能绕过 mysql/ORACLE服务,直接读写 MYSQL/ORACLE表在底层本地文件系统中的文件一样。
所以周边生态工具,如 spark, datax 等,都不能像以往操作普通 ORC表一样,直接读取 HIVE ACID事务表了。
目前spark 访问 acid 事务表,社区推荐的方案是通过 hwc (hive warehouse connector) 这一插件来实现对 hive acid表的读写操作,而 datax 目前还没有成熟的方案。
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

以上是关于为什么不能使用 datax 直接读写 hive acid 事务表?的主要内容,如果未能解决你的问题,请参考以下文章