Java基准测试工具JMH使用
Posted 流子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基准测试工具JMH使用相关的知识,希望对你有一定的参考价值。
JMH,即Java Microbenchmark Harness,这是专门用于进行代码的微基准测试的一套工具API。
JMH 由 OpenJDK/Oracle 里面那群开发了 Java 编译器的大牛们所开发 。何谓 Micro Benchmark 呢? 简单地说就是在 方法层面上的 benchmark,精度可以精确到微秒级。
本文主要介绍了性能基准测试工具 JMH,它可以通过一些功能来规避由 JVM 中的 JIT 或者其他优化对性能测试造成的影响。
Java的基准测试需要注意的几个点:
- 测试前需要预热。
- 防止无用代码进入测试方法中
- 并发测试
- 测试结果呈现
,如果我们要通过JMH进行基准测试的话,直接在我们的pom文件中引入JMH的依赖即可:
dependencies
jmhCompile project
jmhCompile 'org.openjdk.jmh:jmh-core:1.24'
jmhAnnotationProcessor 'org.openjdk.jmh:jmh-generator-annprocess:1.24'
@Fork:
进行 fork 的次数,可用于类或者方法上。如果 fork 数是 2 的话,则 JMH 会 fork 出两个进程来进行测试。
@Threads:
每个测试进程的测试线程数量。
@OutputTimeUnit:
测试结果的时间单位。
@Param
指定某项参数的多种情况,特别适合用来测试一个函数在不同的参数输入的情况下的性能,只能作用在字段上,使用该注解必须定义 @State 注解。
@Setup
必须标示在@State注解的类内部,表示初始化操作
@TearDown
必须表示在@State注解的类内部,表示销毁操作
Level.Trial
只会在个基础测试的前后执行。包括Warmup和Measurement阶段,一共只会执行一次。
Level.Iteration
每次执行记住测试方法的时候都会执行,如果Warmup和Measurement都配置了2次执行的话,那么@Setup和@TearDown配置的方法的执行次数就4次。
Level.Invocation
每个方法执行的前后执行(一般不推荐这么用)
@Benchmark
@Benchmark标签是用来标记测试方法的,只有被这个注解标记的话,该方法才会参与基准测试,但是有一个基本的原则就是被@Benchmark标记的方法必须是public的。
@Warmup
@Warmup用来配置预热的内容,可用于类或者方法上,越靠近执行方法的地方越准确。一般配置warmup的参数有这些:
iterations:预热的次数。
time:每次预热的时间。
timeUnit:时间单位,默认是s。
batchSize:批处理大小,每次操作调用几次方法。
@Measurement
用来控制实际执行的内容
iterations:执行的次数。
time:每次执行的时间。
timeUnit:时间单位,默认是s。
batchSize:批处理大小,每次操作调用几次方法。
@BenchmarkMode
@BenchmarkMode主要是表示测量的纬度,有以下这些纬度可供选择:
Mode.Throughput 整体吞吐量,每秒执行了多少次调用,单位为 ops/time
Mode.AverageTime 用的平均时间,每次操作的平均时间,单位为 time/op
Mode.SampleTime 随机取样,最后输出取样结果的分布
Mode.SingleShotTime 只运行一次,往往同时把 Warmup 次数设为 0,用于测试冷启动时的性能
Mode.All:上面的所有模式都执行一次
Mode.All 运用所有的检测模式 在方法级别指定@BenchmarkMode的时候可以一定指定多个纬度,例如:@BenchmarkMode(Mode.Throughput, Mode.AverageTime, Mode.SampleTime, Mode.SingleShotTime),代表同时在多个纬度对目标方法进行测量。
@OutputTimeUnit
@OutputTimeUnit代表测量的单位,比如秒级别,毫秒级别,微妙级别等等。一般都使用微妙和毫秒级别的稍微多一点。该注解可以用在方法级别和类级别,当用在类级别的时候会被更加精确的方法级别的注解覆盖,原则就是离目标更近的注解更容易生效。
@State
在很多时候我们需要维护一些状态内容,比如在多线程的时候我们会维护一个共享的状态,这个状态值可能会在每隔线程中都一样,也有可能是每个线程都有自己的状态,JMH为我们提供了状态的支持。该注解只能用来标注在类上,因为类作为一个属性的载体。@State的状态值主要有以下几种:
Scope.Benchmark 该状态的意思是会在所有的Benchmark的工作线程中共享变量内容。
Scope.Group 同一个Group的线程可以享有同样的变量
Scope.Thread 每个线程都享有一份变量的副本,线程之间对于变量的修改不会相互影响
@State(Scope.Benchmark)
@Fork(value = 1)
public class ParseEngineBenchmark
@Param("128", "256", "512","1024", "2048", "4096")
private int length;
private byte[] content;
private byte[] zlibEncode;
private byte[] zstdEncode;
@Setup(Level.Trial)
public void prepare() throws IOException
content = RandomStringUtils.randomAlphanumeric(length).getBytes();
zlibEncode=ZipUtils.compress(content);
zstdEncode=Zstd.compress(content);
@TearDown(Level.Trial)
public void destroy()
@Benchmark
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 10, time = 1)
public byte[] handleZlibCompress() throws IOException
return ZipUtils.compress(content);
public static void main(String[] args)
Options opt = new OptionsBuilder(
)
.include(ParseEngineBenchmark.class.getSimpleName()).result("result.json")//数据json的跑分结果
.resultFormat(ResultFormatType.JSON).output("run.log")//输出打印日志
.build();
try
new Runner(opt).run();
catch (RunnerException e)
e.printStackTrace();
JMH 可视化除此以外,如果你想将测试结果以图表的形式可视化,可以试下这些网站:
Benchmark (length) Mode Cnt Score Error Units
ParseEngineBenchmark.handleCrypto 256 thrpt 10 13042155.579 ± 112897.883 ops/s
ParseEngineBenchmark.handleUnCrypto 256 thrpt 10 11870482.143 ± 41689.274 ops/s
ParseEngineBenchmark.handleZlibCompress 256 thrpt 10 105607.717 ± 7477.906 ops/s
ParseEngineBenchmark.handleZlibUnCompress 256 thrpt 10 298697.795 ± 67420.169 ops/s
ParseEngineBenchmark.handleZstdCompress 256 thrpt 10 304541.271 ± 2214.547 ops/s
ParseEngineBenchmark.handleZstdUnCompress 256 thrpt 10 669493.645 ± 4759.451 ops/s
其中:
Mode:
thrpt:吞吐量,也可以理解为tps、ops
avgt:每次请求的平均耗时
sample:请求样本数量,这次压测一共发了多少个请求
ss:SingleShot除去冷启动,一共执行了多少轮
Cnt、执行次数
Score:得分
Units 单位
Error 误差或者偏差
如果你配置了输出文件,比如我上面的 resul.json ,但是你打开是看不懂的,可以借助两个网站把文件上传进行分析:
JMH Visual Chart,这个项目目前处在实验状态,并没有对所有可能的基准测试结果进行验证,目前它能够比较不同参数下不同方法的性能,未来可以无限的扩展JSON to Chart的转化方法从而支持更多的图表
JMH Visualizer:它是一个功能齐全的可视化项目,只是少了我想要的图表罢了。
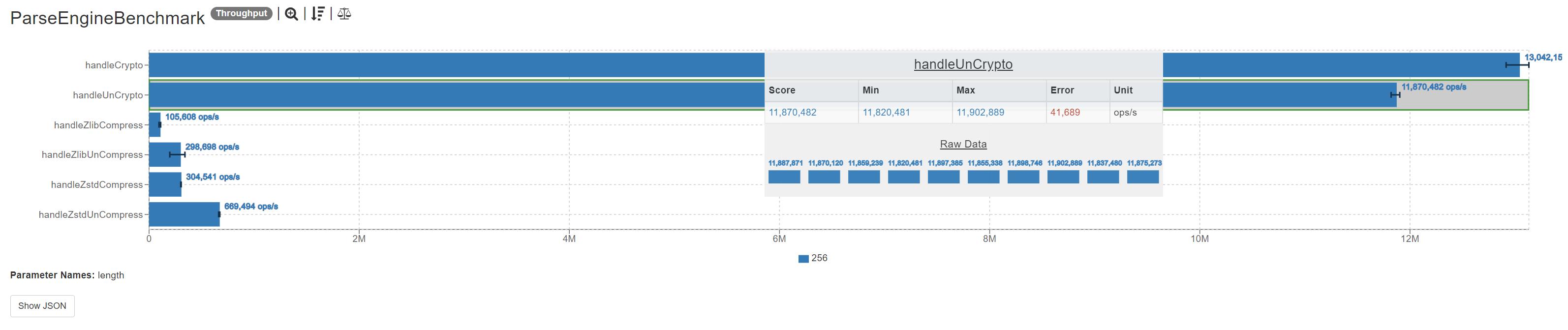
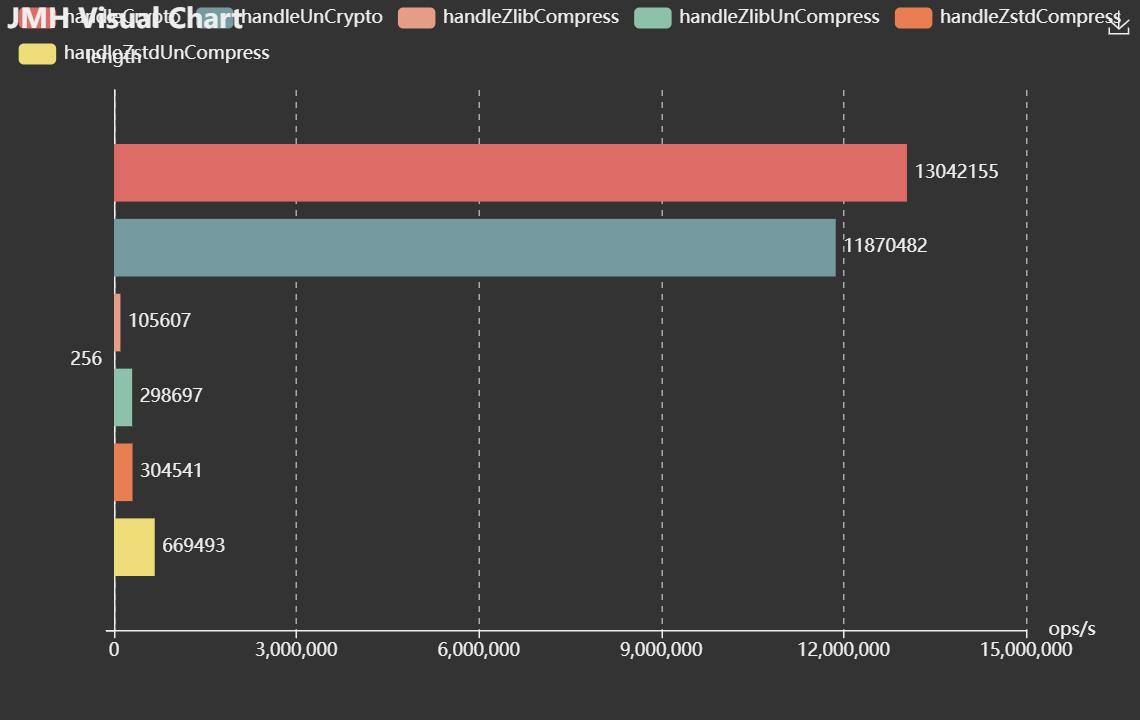
进阶:
JMH 陷阱在使用 JMH 的过程中,一定要避免一些陷阱。比如 JIT 优化中的死码消除,比如以下代码:@Benchmark
public void testStringAdd(Blackhole blackhole)
String a = “”;
for (int i = 0; i < length; i++)
a += i;
JVM 可能会认为变量 a 从来没有使用过,从而进行优化把整个方法内部代码移除掉,这就会影响测试结果。JMH 提供了两种方式避免这种问题,一种是将这个变量作为方法返回值 return a,一种是通过 Blackhole 的 consume 来避免 JIT 的优化消除。其他陷阱还有常量折叠与常量传播、永远不要在测试中写循环、使用 Fork 隔离多个测试方法、方法内联、伪共享与缓存行、分支预测、多线程测试等,感兴趣的可以阅读 https://github.com/lexburner/JMH-samples 了解全部的陷阱。
Q1: gradle Unable to find the resource: /META-INF/BenchmarkList
可能是导入的jar包方式不正常,
jmhCompile project
compile 'org.openjdk.jmh:jmh-core:1.24'
compile 'org.openjdk.jmh:jmh-generator-annprocess:1.24'
改成
jmhCompile project
jmhCompile 'org.openjdk.jmh:jmh-core:1.24'
jmhAnnotationProcessor 'org.openjdk.jmh:jmh-generator-annprocess:1.24'
Q2: 不能用调试模式,否则会报以下异常:
# Run progress: 0.00% complete, ETA 00:00:24
# Fork: 1 of 1
ERROR: transport error 202: connect failed: Connection refused
ERROR: JDWP Transport dt_socket failed to initialize, TRANSPORT_INIT(510)
JDWP exit error AGENT_ERROR_TRANSPORT_INIT(197): No transports initialized [debugInit.c:750]
<forked VM failed with exit code 2>
<stdout last='20 lines'>
</stdout>
<stderr last='20 lines'>
ERROR: transport error 202: connect failed: Connection refused
ERROR: JDWP Transport dt_socket failed to initialize, TRANSPORT_INIT(510)
JDWP exit error AGENT_ERROR_TRANSPORT_INIT(197): No transports initialized [debugInit.c:750]
</stderr>
以上是关于Java基准测试工具JMH使用的主要内容,如果未能解决你的问题,请参考以下文章