推荐学Java——数据表高级操作
Posted code小生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐学Java——数据表高级操作相关的知识,希望对你有一定的参考价值。
本文目录
前言
上一节内容学习了关于数据表的基本操作,也就是针对单表的增删改查以及创建和删除,而在实际开发中,往往是多表联合操作,尤其是插入和查询用的最多,而这两步都要经过一个“筛选”的过程,这个过程要根据具体业务逻辑,综合不同的表,查询后决定是否满足插入或其他条件。
本节内容涉及的广泛一些,我们需要创建多个表,进行复杂一点的操作,数据库管理工具这里使用的是 Navicat 12 ,还有很多类似的软件,比如:sqlyog、SQL-Front等等。
Navicat 12 安装
官网:https://www.navicat.com.cn/download/navicat-premium
解决 Navicat12 链接MySQL的错误:2059 - authentication plugin 'caching_sha2_password’
解决方案:https://jingyan.baidu.com/article/0aa22375e7966ac8cc0d64b3.html
这里特别注意最后一句命令:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root';BY后面的字符串就是你的 mysql 密码,如果你没有正确输入,那么测试链接数据库的时候会提示这个错误:1045 Access denied for user 'root'@'localhost' (using password: YES)其实就相当于修改了 root 账户的密码。
本节涉及到表结构
部门表
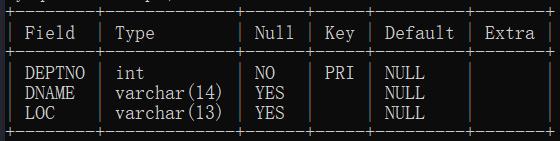
字段分别是:部门编号、部门名称、部门所在地址位置。
员工表
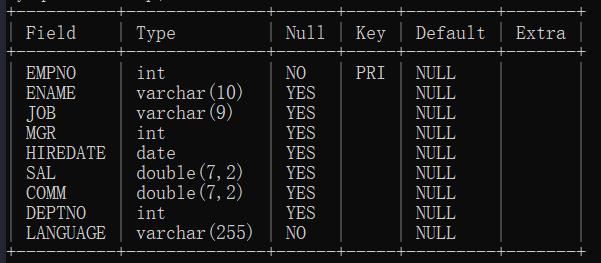
字段分别是:员工编号、员工名称、职位、上级、入职日期、薪资、补贴、所属部门编号、所使用的语言。
薪资等级表
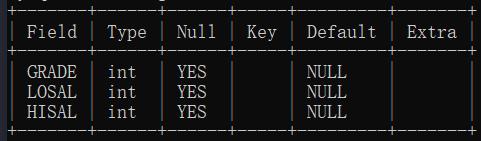
字段分别是:等级、最低工资、最高工资。
- 以上表中的数据大家可以自己修改和填充
- 工具和
sql文件在公众号推荐学java回复navicat获取。

常见的 MySQL 内置函数
与之对应,还有多行处理函数,前者是说有一条输入,对应一条输出结果;后者则是多行输入,对应一条输出结果,比如:求和函数sum() 。
-
LOWER():转小写字母
select lower(列名) from 表名; // 也可以带表名 select lower(列名) as l_Name from 表名; -
UPPER():转大写字母
-
LENGTH(列名):字符数量,就是字段的长度
-
CONCAT(string1,string2):字符串拼接,不能使用
+.// 将列 LANGUAGE 首字母转大写 select concat(upper(substr(language,1,1)),substr(language,2,length(language)-1)) as '语言' from emp; -
INSTR():字符出现的位置
-
INSERT():插入/替换字符
-
REPLACE():替换字符
-
SUBSTR(字符串,开始截取的位置,结束的位置):截取字符串。下标是从1开始的
select substr(ename,1,1) from emp; select ename from emp where substr(ename,1,1) like '老%'; -
SUBSTRING(字符串,开始截取的位置,偏移量):截取字符串
-
LPAD(字符串,填充后字符串总长度,要填充的字符串):在字符串的左侧填充给定字符串。
-
RPAD(字符串,填充后字符串总长度,要填充的字符串):在字符串的右侧填充给定字符串。
-
TRIM():去掉字符串的首位空格
-
ROUND(列名,保留位数) :四舍五入,根据指定位数来保留小数位。
// 十位四舍五入,没有小数位 select round(sal,-1) as '薪资' from emp; // 去尾,只保留整数部分 select round(sal,0) as '薪资' from emp; // 四舍五入,保留一位小数(如果本来只有一位小数,则会直接保留) select round(sal,1) as '薪资' from emp; // 四舍五入,保留两位小数 select round(sal,2) as '薪资' from emp; -
ifnull(值1, 值2):空处理函数,可以将 null 转换成一个具体值。 如果值1为null,那么会取值2参与运算。select (sal + IFNULL(comm,0)) *12 as '年薪' from emp; -
format(列名,'格式'):数字格式化,例如显式千分位:select e.ename,format(e.sal,'$999,999') as sal from emp e;
连接查询
上一节内容涉及的都是但张表操作和基本的sql关键词的使用,下面的内容涉及多张表之间的查询操作,以及相关SQL专业知识。
SQL查询分类
根据SQL语法年代
- SQL92:1992年出现的语法
- SQL99:1999年出现的语法
根据表连接的方式
- 内连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接(左连接)
- 右外连接(右链接)
- 全连接(基本不用,可不了解)
笛卡尔积现象
当多张表关联查询时,如果不加任何约束条件,那么查询结果是多张表记录的乘机。
内连接之等值连接案例
需求:
查询每个员工所在的部门名称,要求显示员工姓名、部门名称。
分析:
员工表中只有部门编号,部门名称是在部门表中,所以就需要两张表关联查询。
SQL语句:
select e.ename, d.dname from emp e join dept d on e.deptno = d.deptno; // on 后的条件是等值的,叫做等值连接
内连接之非等值连接案例
需求:
找出每个员工的薪资等级,要求显示员工姓名、薪资、薪资等级。
分析:
薪资等级是一张单独的表,员工姓名和薪资在员工表中,同样需要两张表联合查询。
SQL语句:
// on 后的条件不是等值的,叫做非等值连接
select e.ename, e.sal, s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
内连接之自连接案例
需求:
找出每个员工的领导的姓名,显示员工姓名、领导姓名。
分析:
员工表中有员工姓名和员工的上级领导编号,领导同样也是员工,也存在员工表中,所以需要将一张表(员工表)看做两张表来查询,故称作这种情况为自连接查询。
SQL语句:
select e.ename as '员工姓名',em.ename as '领导姓名' from emp e join emp em on e.mgr = em.empno;
外连接案例
需求:
找出每个员工所在的部门,显示员工姓名、部门名称。
分析:
员工在员工表中,存在部门编号,部门名称是在部门表中。
SQL语句:
select e.ename, d.dname from emp e right join dept d on e.deptno = d.deptno;
带有
right的是右外连接,又称右链接,此时查询会以right右边的表作为主表来查询,任何一个右链接查询都可以写出对应的左连接查询,反之亦然。
对应左连接查询SQL:
select e.ename, d.dname from dept d left join emp e on e.deptno = d.deptno;
总结:
- 外连接的查询结果一定是 >= 内连接的查询结果。
- 一条SQL中可以同时出现内连接和外连接,混合使用没有问题。
多张表关联查询
语法格式:
select a.xxx,b.xxx,c.xxx from a表 a join b表 b on a和b的链接条件 join c表 c on a和c的链接条件
**案例1:**三张表关联查询
找出每个员工的部门名称以及工资等级,显示员工姓名、薪资、部门名称、薪资等级。
SQL语句:
select e.ename,e.sal,d.dname,s.grade from emp e join dept d on e.deptno = d.deptno join salgrade s on e.sal between s.losal and s.hisal;
案例2: 三张表链接+左连接查询
找出每个员工的部门名称以及工资等级,显示员工姓名、薪资、领导名、部门名称、薪资等级。
SQL语句:
select e.ename, em.ename as '上级领导', e.sal, d.dname, s.grade from emp e join dept d on e.deptno = d.deptno join salgrade s on e.sal between s.losal and hisal left join emp em on e.mgr = em.empno;
子查询
什么是子查询?
select语句中嵌套select语句,那么被嵌套的select语句称为子查询。
子查询出现位置
select
...(select)
from
...(select)
where
...(select)
where 子句中的子查询
案例:
找出比最低工资(员工的工资,不是工资登记表中的最低工资)高的员工姓名和工资。
SQL语句:
select e.ename,e.sal from emp e where e.sal > (select min(sal) from emp);
from 子句中的子查询
from子句中的子查询结果可以当做一张临时表来使用,因为from后面本身就是表名
案例:
找出每个工作岗位的平均薪资的工资等级。
SQL语句:
select s.job,s.avg,sal.grade from (select job, avg(sal) avg from emp group by job) s join salgrade sal on s.avg between sal.losal and sal.hisal ;
select 子句中的子查询(了解即可)
案例:
找出每个员工的部门名称,显示员工姓名、部门名称。
SQL语句:
select e.ename, (select d.dname from dept d where d.deptno = e.deptno) d from emp e;
union用法
将查询结果集进行合并,比如:两条select语句的结果拼接在一起。
案例:
将
job为四绝之一和Java全栈工程师的员工查出来,显示员工名、职位名。
SQL语法:
select e.ename, e.job from emp e where e.job = '四绝之一'
union
select e.ename,e.job from emp e where e.job ='Java全栈工程师';
就这个需求而言,SQL查询可以用之前学的 or 或者 in(值1,值2) 都可以实现结果,但在多表链接查询时 union 效率更高。
union注意事项:
- 在进行结果集合并的时候,要求结果集的列数相同
limit用法(必须掌握)
将查询结果集的一部分取出来,通常多用于分页查询中。
用法示例:
-- 将所有职位查询来降序排列,只显示前5条
select * from emp order by job desc limit 5;
-- 将查询结果 从第四条开始,向后取5条数据出来
select e.ename, e.sal from emp e order by sal desc limit 3,5;
limit注意事项:
- limit startIndex,length. startIndex如果不写,默认从第一条开始
- mySQL当中,
limit在order by之后执行。
通用分页公式:
limit (pageNo-1)*pageSize, pageSize;
存储引擎(了解即可)
这个名词是MySQL特有的,Oracle中也有类似技术,但不叫这个名字。存储引擎就是一张表存储/组织数据的方式。
-
MySQL默认的存储引擎是
InnoDB -
MySQL默认的字符编码是
utf8 -
创建引擎语法格式:
create table t_studying ( id int primary key auto_increment, name varchar(255) not null, grade int not null ) engine = InnoDB default charset=utf8; -
查看MySQL支持的存储引擎,命令:
show engines \\G
这道理,查询相关高级知识已经完结了,下面内容是偏理论性的,但也很重要,属于高级操作,请结合知识导图查看。
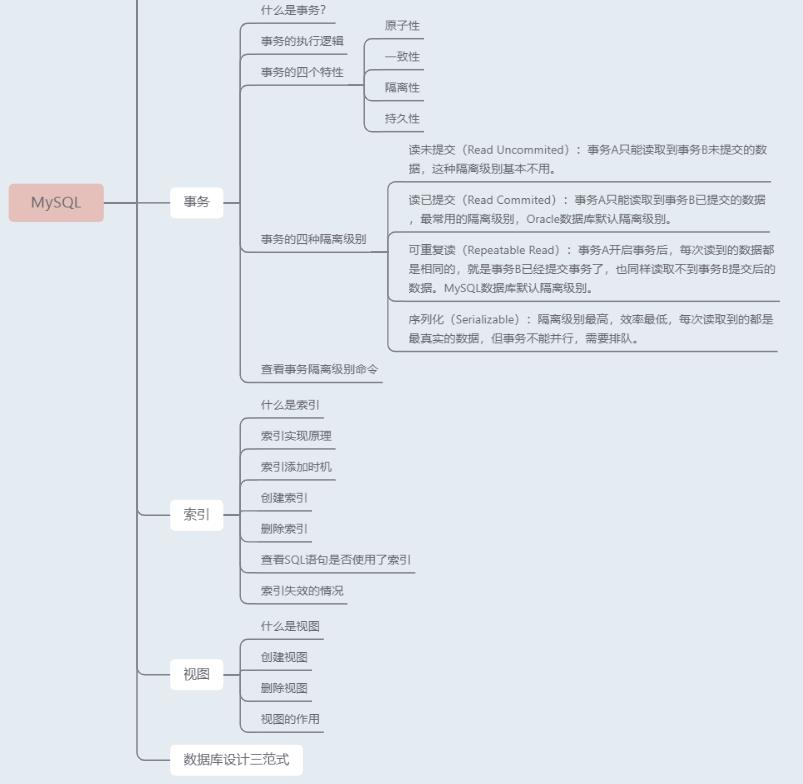
事务(重点)
什么是事务?
一个事务就是一个完整的业务逻辑。
只有增、删、改才会有事务一说。
事务的执行逻辑
这和存储引擎有关系,MySQL使用 InnoDB ,而 InnoDB 对没次操作的DML语句都会有日志记录文件,事务的执行结果要么多条语句全部失败,要么全部成功,无论是什么结果都会清空日志文件,所以事务支持回滚。
事务的四个特性
- 原子性
- 一致性
- 隔离性
- 持久性
事务的四种隔离级别
- 读未提交(Read Uncommited):事务A只能读取到事务B未提交的数据,这种隔离级别基本不用。
- 读已提交(Read Commited):事务A只能读取到事务B已提交的数据,最常用的隔离级别,Oracle数据库默认隔离级别。
- 可重复读(Repeatable Read):事务A开启事务后,每次读到的数据都是相同的,就是事务B已经提交事务了,也同样读取不到事务B提交后的数据。MySQL数据库默认隔离级别。
- 序列化(Serializable):隔离级别最高,效率最低,每次读取到的都是最真实的数据,但事务不能并行,需要排队。
查看事务隔离级别命令
select @@tx_isolation
索引
什么是索引?
索引是在数据库表的字段上添加的,是为了提高查询效率提供的一种机制。一个字段可以添加一个索引,当然也可以多个字段联合起来添加索引。
索引实现原理
- 在任何数据库中,主键都会自动添加索引
- 在MySQL中,如果一个字段有
unique约束的话,也会自动添加索引 - 在任何数据库中,任意一条记录在硬盘上都有对应的物理存储编号
- 不同的存储引擎索引以不同的形式存在。在 InnoDB 中,索引存储在一个逻辑名叫
tablespace中,是一种二叉树(B-Tree)结构。
索引添加时机
- 数据量庞大
- 该字段经常出现在
where后面,一条件的形式存在,也就是经常被扫描 - 该字段很少的MDL(insert delete update)操作(因为DML之后,索引需要重新排序)
创建索引
语法:
create index 索引名 on 表名(字段名);
删除索引
语法:
drop index 索引名 on 表名;
查看 SQL 语句是否使用了索引
语法:
explain sql查询语句;
说明: 通过查看结果中的 type 和 rows 值来做判断,前者如果是 ref 则说明是通过索引来扫描的。
索引失效的情况
- 模糊匹配当中以
%开头了 - 使用
or的时候,要能使用索引,那么要求or两边的字段都要有索引,如果只要一边有索引,那么索引会失效 - 使用复合索引(两个或多个字段联合起来添加一个索引)的时候,没有使用左侧的列查找,索引失效
- 在
where当中,索引列参加了运算,索引失效 - 在
where当中,索引列使用了函数,索引失效
视图
什么是视图
不同角度看待同一份数据。
只有
DQL语句才能以view的形式创建。
创建视图对象
create view 视图名称 as select语句;
删除视图对象
drop view 视图名称;
视图作用
我们可以面向视图对象进行增删改查,这将会导致原表数据被操作。方便、简化开发、利于维护
数据库设计三范式
第一范式
要求所有表都必须有主键,每一个字段都是原子性不可再分。
第二范式
在第一范式的基础上,要求每个非主键字段完全依赖主键,不要产生部分依赖。
第三范式
在第二范式的基础上,要求所有非主键字段完全依赖主键,不要产生传递依赖。
总结
关于多表的操作,最常用的就是查询,且是最重要的内容,本章节内容会影响到我们后面的进阶内容,需要加强练习。这里建议大家在学习的过程中写 SQL 语句在相应的工具中进行,本文开始介绍了工具,还没下载的可以去公众号获取。
小编特意创建了一个公众号:
推荐学java,分享java内容,并且以原创为主,欢迎大家搜索关注(关注即送精品视频教程),一起学Java,下次见!
以上是关于推荐学Java——数据表高级操作的主要内容,如果未能解决你的问题,请参考以下文章