Spark算子执行流程详解之三
Posted 亮亮-AC米兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark算子执行流程详解之三相关的知识,希望对你有一定的参考价值。
10.aggregate
用与聚合RDD中的元素,先使用seqOp将RDD中每个分区中的T类型元素聚合成U类型,再使用combOp将之前每个分区聚合后的U类型聚合成U类型,特别注意seqOp和combOp都会使用zeroValue的值,zeroValue的类型为U,
| def aggregate[U: ClassTag](zeroValue:U)(seqOp: (U,T) => U, combOp: (U,U) => U): U = withScope // zeroValue即初始值,aggregatePartition是在excutor上执行的 val aggregatePartition = (it:Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp) // jobResult即初始值,其合并每个分区的结果是在driver端执行的 sc.runJob(this, aggregatePartition, mergeResult) |
例如:
| var rdd1 = sc.makeRDD(1 to 10,2) ##第一个分区中包含5,4,3,2,1 ##第二个分区中包含10,9,8,7,6 scala> rdd1.aggregate(1)( | (x : Int,y : Int) => x + y, | (a : Int,b : Int) => a + b | ) res17: Int = 58 |
为什么是58呢?且看下面的执行流程:
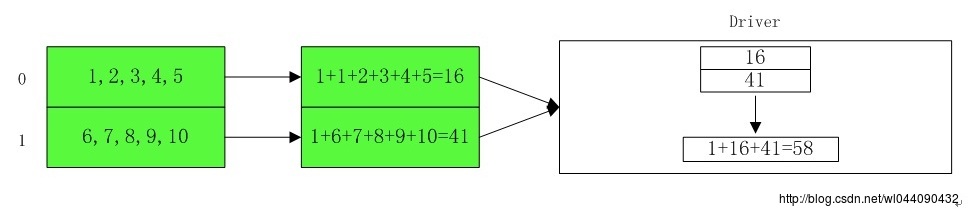
11.fold
简化的aggregate,将aggregate中的seqOp和combOp使用同一个函数op。
| /** //先在excutor上针对分区进行一次fold操作 //然后在driver端合并每个分区上的结果 |
例如可以将aggregate小节里面的例子操作转化为fold操作:
| scala>var rdd1 = sc.makeRDD(1 to 10,2) ##第一个分区中包含5,4,3,2,1 ##第二个分区中包含10,9,8,7,6 scala> rdd1.fold(1)( | (x,y) => x + y | ) res19: Int = 58 ##结果同上面使用aggregate的第一个例子一样,即: scala> rdd1.aggregate(1)( | (x,y) => x + y, | (a,b) => a + b | ) res20: Int = 58 |
12.treeAggregate
分层进行aggregate,由于aggregate的时候其分区的结算结果是传输到driver端再进行合并的,如果分区比较多,计算结果返回的数据量比较大的话,那么driver端需要缓存大量的中间结果,这样就会加大driver端的计算能力,因此treeAggregate把分区计算结果的合并仍旧放在excutor端进行,将结果在excutor端不断合并缩小返回driver的数据量,最后再driver端进行最后一次合并。
| /** //针对初始分区的聚合函数 //针对初始的各分区先进行部分聚合 //根据传入的depth计算出需要迭代计算的程度 //减少分区个数,合并部分分区的结果 //执行最后一次reduce,返回最终结果 |
例如:
| scala> def seq(a:Int,b:Int):Int= | a+b seq: (a: Int, b: Int)Int scala> def comb(a:Int,b:Int):Int= | a+b comb: (a: Int, b: Int)Int val z =sc.parallelize(List(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18),9) scala> z.treeAggregate(0)(seq,comb,2) res1: Int = 171 |
其具体的执行过程如下:

13.reduce
RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
| /** //定义一个遍历partition的函数,这是在excutor端执行的 //reduceLeft从左往后遍历 //定义一个driver端处理分区计算结果的函数,这是在driver端执行的 //将结果返回 |
例如:
| val c = sc.parallelize(1 to 10 , 2) c.reduce((x, y) => x + y)//结果55 |
具体执行流程如下:

14.max
返回最大值,其排序方法对象默认的排序方法
| /** |
其本质就是定义个排序的方法,然后调用reduce操作,实例如下:
| scala>var rdd1 = sc.makeRDD(1 to 10,2) ##第一个分区中包含5,4,3,2,1 ##第二个分区中包含10,9,8,7,6 scala> rdd1.max() res19: Int = 10 |
其执行流程如下:

15.min
返回最小值,其排序方法对象默认的排序方法
| /** |
其本质就是定义个排序的方法,然后调用reduce操作,实例如下:
| scala>var rdd1 = sc.makeRDD(1 to 10,2) ##第一个分区中包含5,4,3,2,1 ##第二个分区中包含10,9,8,7,6 scala> rdd1.min() res19: Int = 1 |
其执行流程如下:

16.treeReduce
类似于treeAggregate,利用在excutor端进行多次aggregate来缩小driver的计算开销
| /** //针对初始分区的reduce函数 //针对初始的各分区先进行部分reduce //最终调用的还是treeAggregate方法 |
treeReduce函数先是针对每个分区利用scala的reduceLeft函数进行计算;最后,在将局部合并的RDD进行treeAggregate计算,这里的seqOp和combOp一样,初值为空。在实际应用中,可以用treeReduce来代替reduce,主要是用于单个reduce操作开销比较大,而treeReduce可以通过调整深度来控制每次reduce的规模。其具体的执行流程不再详细叙述,可以参考treeAggregate方法。
以上是关于Spark算子执行流程详解之三的主要内容,如果未能解决你的问题,请参考以下文章