CycleGAN算法笔记
Posted AI之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CycleGAN算法笔记相关的知识,希望对你有一定的参考价值。
论文:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
论文链接:https://arxiv.org/abs/1703.10593
代码链接:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
CycleGAN是发表在ICCV2017关于将GAN应用在无监督的图像到图像翻译(image-to-image translation)的著名算法,和应用于有监督图像翻译的pix2pix几乎是同一批作者。CycleGAN最大的特点是无监督,也就是不要求训练数据是成对的,只需要提供不同域(domain)的图像就能成功训练不同域之间图像的映射(或者叫翻译),这大大降低了图像翻译的门槛,毕竟某些类型的成对数据并不容易获取,比如同一个场景的夏天照片和冬天照片、同样造型的斑马和马等,因此CycleGAN是非常棒的一个作品。
关于成对和非成对数据的对比可以看Figure2,左边是成对的数据,也就是pix2pix算法所使用的训练数据;右边是非成对的数据,X和Y是不同域的数据,不同域的例子比如夏天和冬天、斑马和马、苹果和橘子等。
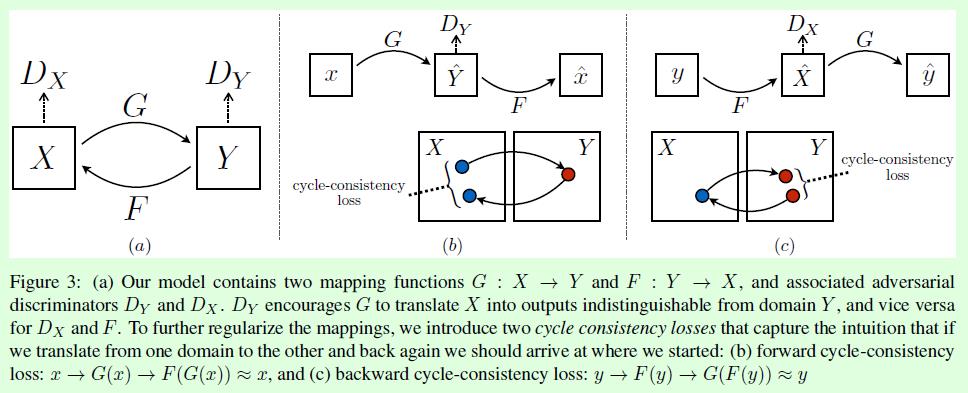
CycleGAN算法的整体示意图如Figure3所示,整体上包含2个GAN网络。
假设现在有X和Y两个域,可以简单理解为X为斑马,Y为马。在CycleGAN中有2个生成器,分别用G和F表示,如Figure3(a)所示,生成器G用来基于X域的图像生成Y域的图像(斑马->马);生成器F用来基于Y域的图像生成X域的图像(马->斑马),这2个生成器的定位是相反的过程,通过(b)和©中的cycle-consistency loss进行约束。同时CycleGAN中有2个判别器,分别用DX和DY表示,用来判断输入的X域或Y域图像是真还是假。因此CycleGAN可以看做是2个GAN的融合,一个GAN由生成器G和判别器DY构成,实现从X域到Y域的图像生成和判别;另一个GAN由生成器F和判别器DX构成,实现从Y域到X域的图像生成和判别,两个网络构成循环(cycle)的过程。
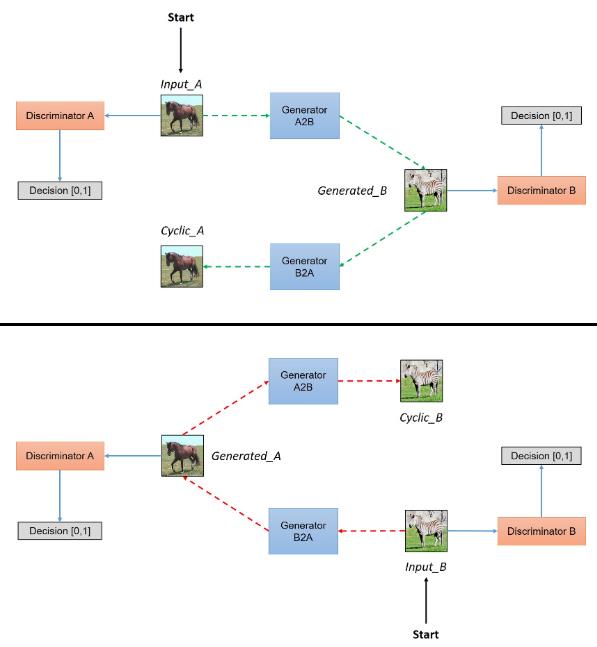
CycleGAN的整个过程可以用如下示意图表示,截取自:https://hardikbansal.github.io/CycleGANBlog/。这个图对CycleGAN的描述非常清晰,该图总共分为上下2部分,分别表示从X域到Y域的图像生成和从Y域到X域的图像生成。
CycleGAN的整体优化目标如公式3所示,一共包含3个部分,第一部分LGAN(G,DY,X,Y)表示生成器G和判别器DY的优化目标;第二部分LGAN(F,DX,Y,X)表示生成器F和判别器DX的优化目标,这2部分是GAN算法本身的优化目标。第三部分Lcyc(G,F)表示cycle consistency loss,用于约束从变换域再变换到原域时图像的一致。
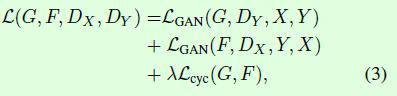
LGAN(G,DY,X,Y)如公式1所示,是常规GAN的优化目标,判别器DY要最大化这个优化目标,生成器G要最小化公式1中的后半部分。LGAN(F,DX,Y,X)也是同理。
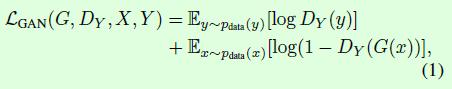
另外作者在论文中提到,为了训练过程更加稳定,实际训练中采用的是基于最小二乘损失,以LGAN(G,D,X,Y)为例,判别器D的优化目标变成最小化
E
x
→
p
d
a
t
a
(
y
)
[
(
D
(
y
)
−
1
)
2
]
+
E
x
→
p
d
a
t
a
(
x
)
[
D
(
G
(
x
)
)
2
]
Ex \\rightarrow pdata(y)[(D(y)-1)^2]+Ex \\rightarrow pdata(x)[D(G(x))^2]
Ex→pdata(y)[(D(y)−1)2]+Ex→pdata(x)[D(G(x))2],这个优化目标的第一部分是希望D(y)尽可能接近1,也就是说在输入真实图像y时,判别器D认为输入是真实的概率尽可能高,第二部分是希望D(G(x))尽可能接近0,也就是说在输入生成的假图像G(x)时,判别器D认为输入是真实的概率尽可能低。生成器G的优化目标变成最小化
E
→
p
d
a
t
a
(
x
)
[
(
D
(
G
(
x
)
)
−
1
)
2
]
E \\rightarrow pdata(x)[(D(G(x))-1)^2]
E→pdata(x)[(D(G(x))−1)2],这个优化目标是希望D(G(x))尽可能接近1,而D(G(x))越接近1表示判别器D越相信生成器G生成的图像G(x)是真实图像。
Lcyc(G,F)如公式2所示,其中G(x)表示从X域到Y域的变化,F(G(X))表示再从Y域变换到X域,模型训练的目标当然是希望F(G(X))尽可能和X接近,因此用L1距离来约束,也就是x->G(x)->F(G(x))≈x,作者将这个称之为forward cycle consistency;同理对于y->F(y)->G(F(y))≈y称之为backward cycle consistency。在Figure3(b)和©中也给出了这个损失的示意图。
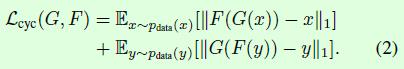
实验结果:
在CycleGAN中对于损失函数的设定是模型训练成功的关键,因此在这篇论文中也对损失函数做了对比实验,如Table4和Table5所示,分别表示从标签到图像(Table4)和从图像到标签(Table5)的转换任务。
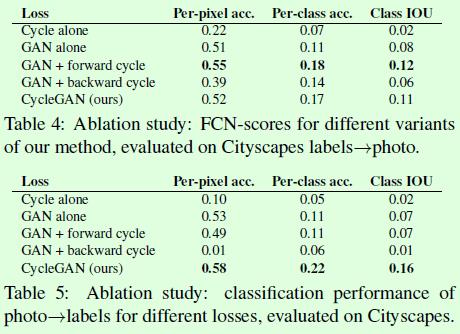
Figure7是Table4和Table5实验的效果图,可以看到Cycle alone和GAN+backward基本上都无法得到指定域的图像;GAN alone和GAN+forward在从图像生成标签任务中对于不同的输入图像,得到的标签基本上都是一样的,这是训练过程中遇到模式崩塌(mode collapse)的原因;CycleGAN在2种转换任务中都能得到理想的生成效果。

Figure13是CycleGAN的生成图样例。

Figure15是CycleGAN和其他图像风格迁移算法的对比。

以上是关于CycleGAN算法笔记的主要内容,如果未能解决你的问题,请参考以下文章