Mysql——索引的深度理解
Posted 努力学习的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql——索引的深度理解相关的知识,希望对你有一定的参考价值。
- 💂 个人主页:努力学习的少年
- 🤟 版权: 本文由【努力学习的少年】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
一. 什么是索引?
索引是创建在数据表上的,是对数据库表中的一列或多列的值进行排序的一种结构。
如果将数据库比作一本书,那么索引就是书的目录,用来提高插叙的速度,通过索引,查询数据时可以不必读完记录的所有信息,而只是查询索引列。否则,数据库系统需要读取每条记录的所有信息进行匹配。
二. 认识mysql的存储
1.理解磁盘
MySQL给用户提供存储服务,而存储的数据都是磁盘这个外设当中,磁盘是计算机的一个机械设备,相比于计算机其它电子元件,磁盘效率是比较低的,在加上IO本身特征,可以知道,如何提高效率,是Mysql重要的一个特征。
因此认识Mysql的存储,我们需要从磁盘开始认识:

接下来我们研究其中一个盘面:
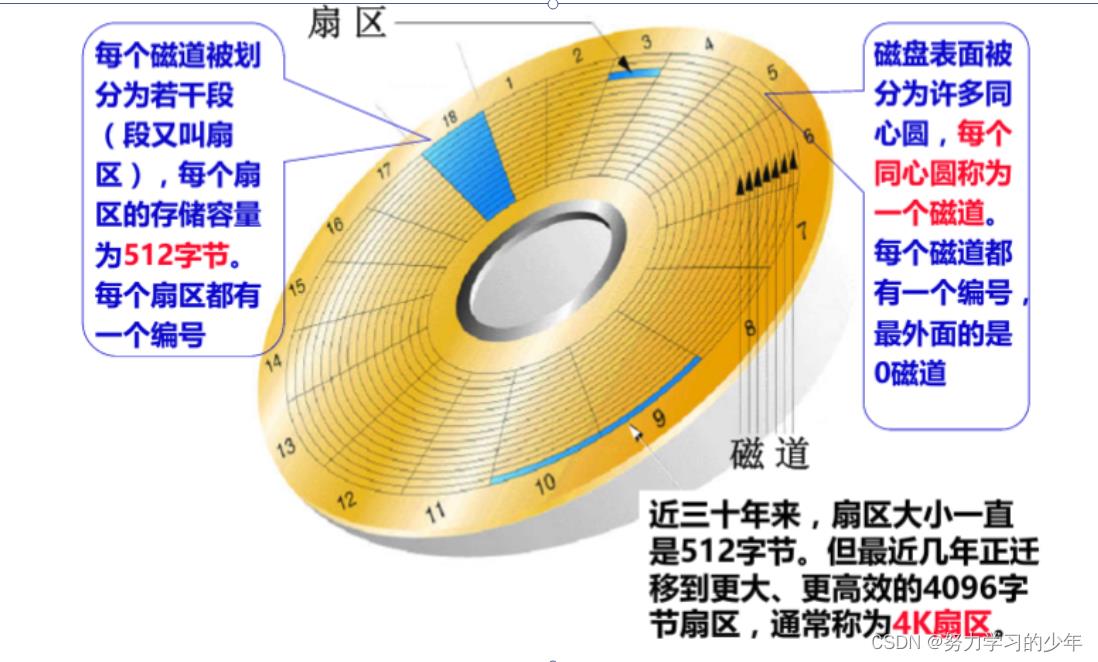
数据库文件是保存在磁盘上的一个一个的扇区,也就是上面的一个一个的小格子,每个扇区大概是512个字节,当数据库文件很大,则会占用多个扇区。
因此,查找一个文件,本质是在磁盘中找到该文件存储的扇区,而我们能够定位任何一个扇区,那么便能找到所有的扇区,因为查找的方式是一样的.那么怎样去定位扇区呢?
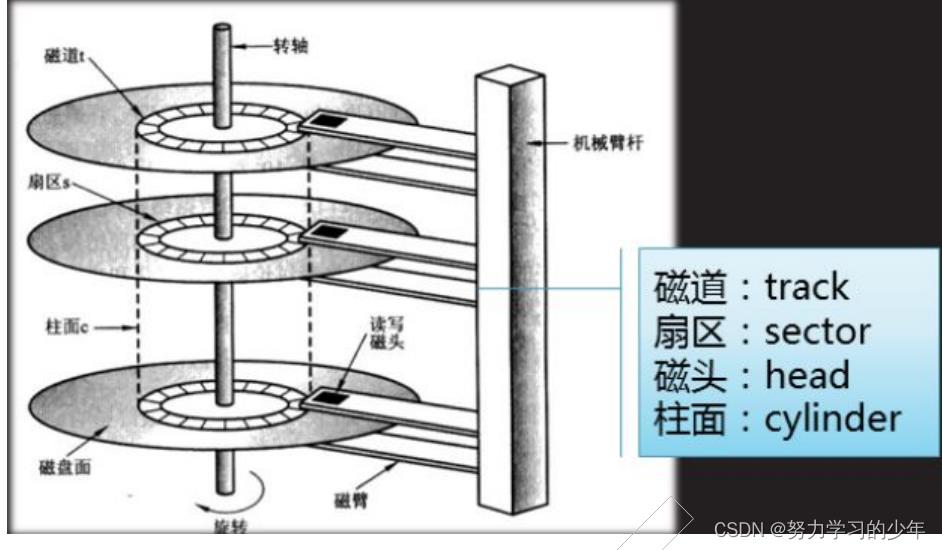
- 柱面(磁道): 多盘磁盘,每盘都是双面,大小完全相等。那么同半径的磁道,整体上便构成了一个柱面
- 每个盘面都有一个磁头,那么磁头和盘面的对应关系便是1对1的。
- 所以,我们只需要知道,磁头(Heads)、柱面(Cylinder)(等价于磁道)、扇区(Sector)对应的编号。即可在磁盘上定位所要访问的扇区
如上所述,如果要在磁盘中将数据加载到内存当中,磁盘需要做一系列查找扇区的动作,这是影响磁盘与内存的I/O效率主要问题。
我们能够在硬件上定位任何一个扇区,但是在系统软件上,是按照扇区的大小(512个字节,少部分4096个字节),进行IO交互吗?
- 不是,系统与磁盘进行IO的交互的大小是数据块,数据块的基本单位是4kb,也就是一次只能拷贝4kb.
- 首先,如果操作系统直接使用硬件提供数据大小进行交互,那么系统的IO代码,就会与硬件强相关,举个例子,如果是以扇区为基本单位,有些磁盘它的扇区是512个字节,有些磁盘的扇区是4096个字节,那么操作系统就不能用一种代码跟这两种磁盘进行IO交互。如果系统与磁盘进行IO统一交互是数据块(4096),则操作系统可以用一套代码与这两种磁盘进行交互。只是操作系统读取512个字节的磁盘,需要读取8块扇区。
- 其次,如果按照扇区大小(512字节)进行I/O交互,则会I/O效率会较低,I/O时间=等的时间+拷贝时间,等的时间就是磁盘需要做一系列查找扇区的动作的时间,拷贝的时间就是系统将磁盘的数据读取到内存的时间,影响I/O效率的主要因素是磁盘查找扇区的时间。
2. MySQL与磁盘交互的基本单位
系统与磁盘进行I/O的基本单位是4kb,但是MySQL作用一款存储软件,它的功能主要是增删查改,所以这就要求它有更高的I/O效率,就需要减少磁盘查找扇区的次数,因此MySQL进行IO的基本单位是16kb,这里叫做page。
当然,MYSQL作为一款应用软件,它是运行在用户区上,它不会直接与磁盘进行数据交互,只能是操作系统将数据读取到内核缓冲区中,然后MySQL在与内核缓冲区进行IO交互。
为什么MySQL的I/O的基本单位是page?
当MySQL查找数据的时候,磁盘就会定位到相应的扇区,连续拷贝4个4kb数据到内核缓冲区中,然后MySQL在从内核缓冲区中读取数据,所以,较大的page为16kb可以减少磁盘定位扇区的次数,提高I/O效率。
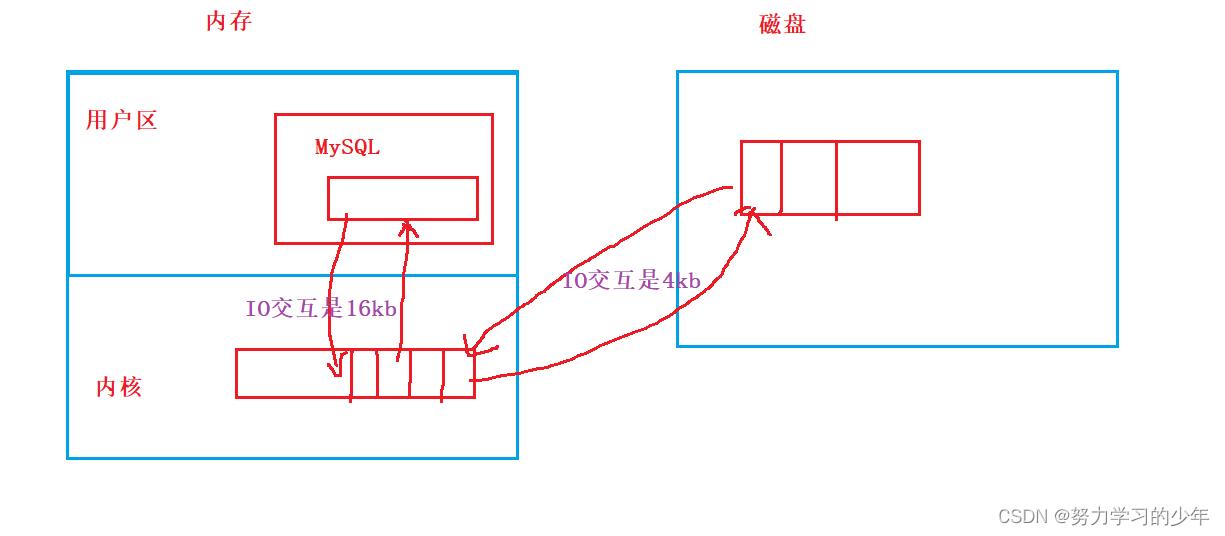
但是我们忽略内核缓冲区与磁盘的IO交互,想象MySQL与磁盘进行IO交互,那么MySQL的数据文件是以page于磁盘进行I/O交互。
总结
- MySQL是以page为单位保存与磁盘进行I/O交互,目的是为了提高I/O效率。
- MySQL中的CRUD操作(增删查改),都需要通过计算,找到相对应的page的位置。
- 只要参与计算,就需要CPU参与,而为了便于CPU,就需要先将数据移动到内存当中。这就涉及到磁盘与内存的IO交互,此时的IO的基本单位就是page。
- 磁盘与内存的I/O时间=等的时间+拷贝的时间,在MySQL与磁盘的IO大部分时间都是在等,因为磁盘需要给你找到一个一个的磁道,在找到对应的扇区。
- 记录是按照行来存储的,但数据库的读取并不以[行]为单位,否则一次读取(也就是一次I/O操作,只能处理一次数据,所以每次读取就需要进行一次I/O,查找效率低下。
- 而数据库的I/O操作最小的单位是page,InnoDB 数据页的默认大小是 16KB,意味着MySQL每次到磁盘中读取的数据最少是16kb,刷新到磁盘上也是16kb。
三. 数据页(page)
1. 理解单个数据页
- 每个数据页中的头部包含page_prev和page_next,分别指向前一个数据页和后一个数据页。
- 每个数据页中包含页目录,方便查找页里面的数据。
- 数据页中的存储数据用了链表的结构,前一条数据指向下一条数据,方便数据的增加和删除。
下面是一个单个数据页的结构
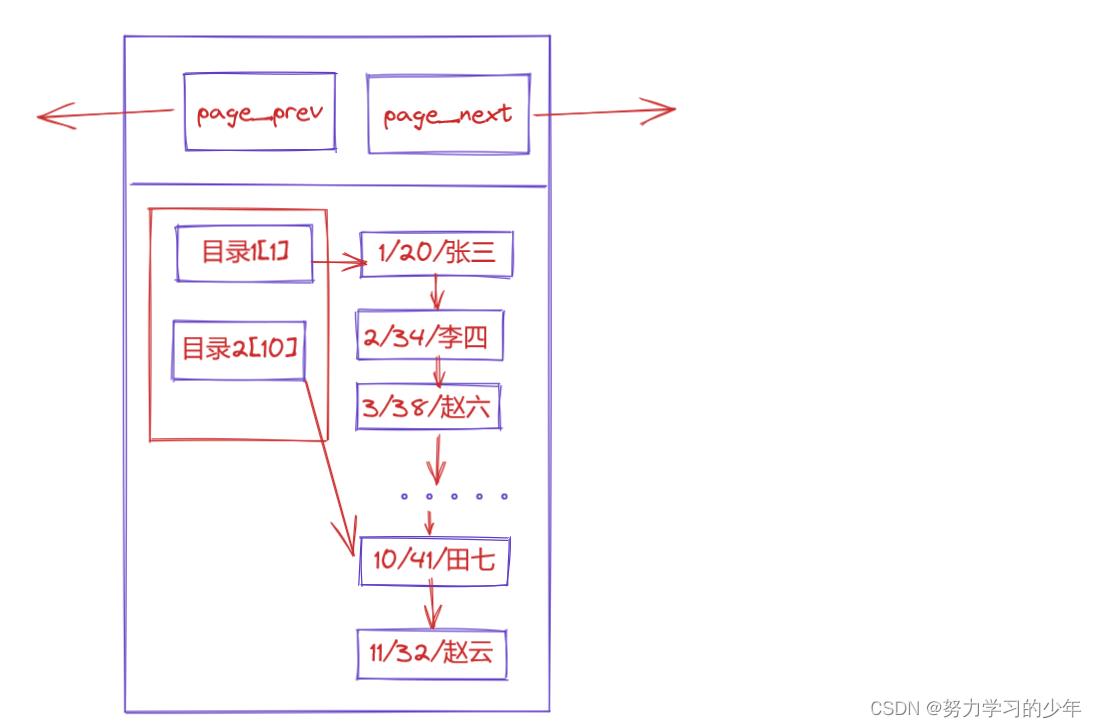
为什么要有页目录?
如果我们要查找赵云这个人,它的id是11,对比有页目录和没有页目录的区别:
- 假设数据页中没有页目录:那么就需要从页里面的id为1从前往后的查找,需要查找11次,才能查到id为11.如果数据页中有页目录.
- 如果有数据页中有页目录,直接到页目录中找到目录2,然后找到id为10的位置,在接下找就找到id为11,总共就需要查找3次。所以只需要找3次即可。
- 因此,页目录就好比我们的书目录一样,可以提高我们查找效率。
2. 理解多个数据页
如果有大量数据,则需要有多个数据页来存储这些数据,如果有多个数据页,同样需要给page带上目录,方便定位到相对应的数据页。
- 使用一个目录项来指向某一页,而这个目录项存放的就是将要指向的页中存放的最小数据的键值。
- 和页内目录不同的地方在于,这种目录管理的级别是页,而页内目录管理的级别是行。
- 其中,每个目录项的构成是:键值+指针。图中没有画全
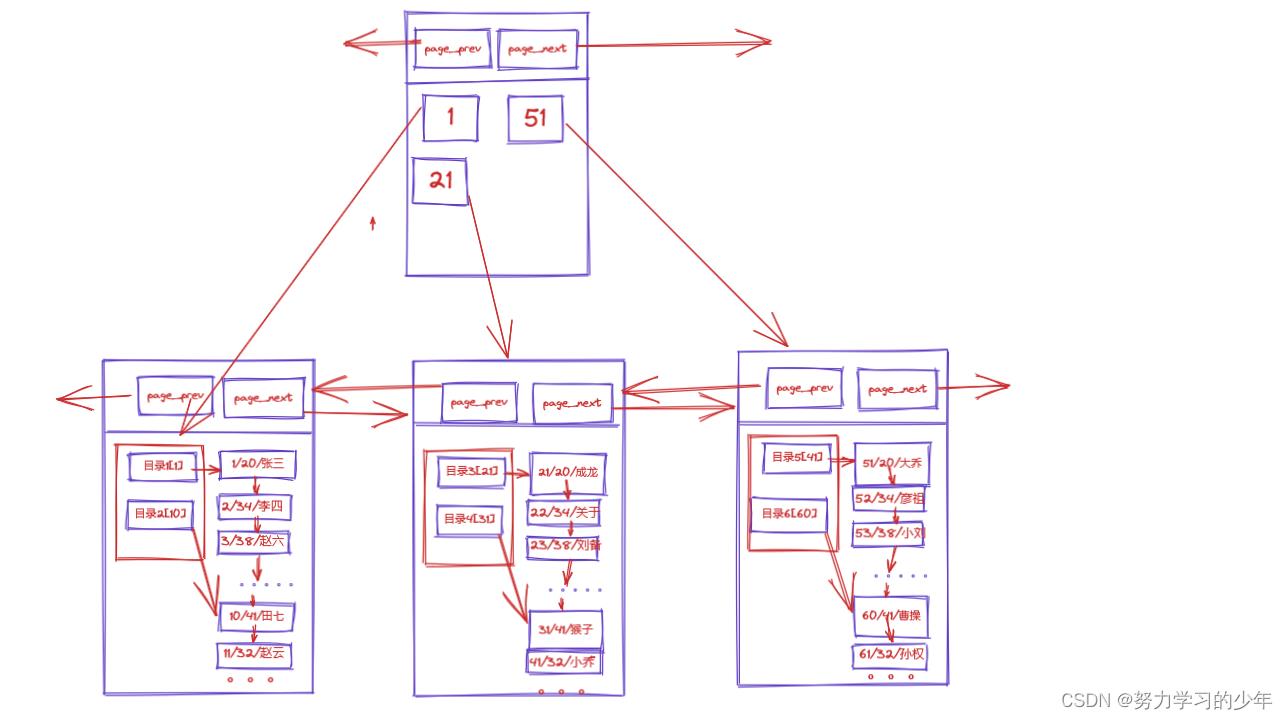
目录页是专门来存放指向page中的最小的数据和page地址,它本身不存放数据,当有多个目录页,如果要查找id为22的所有信息(id是主键),它的搜寻过程如下:
- 通过”id=22“从在目录页中进行比较,发现它的id属于21这一页.
- 通过指针找到21这一页,然后再去该页的目录进去查找,发现在目录三中。
- 通过页目录3找到id为21的值,从id为21往下找,直到与id为22相对应。
- 最后显示id=22的所有信息。
如果有多个目录页,则需要在创建一级目录页去管理这些目录页。
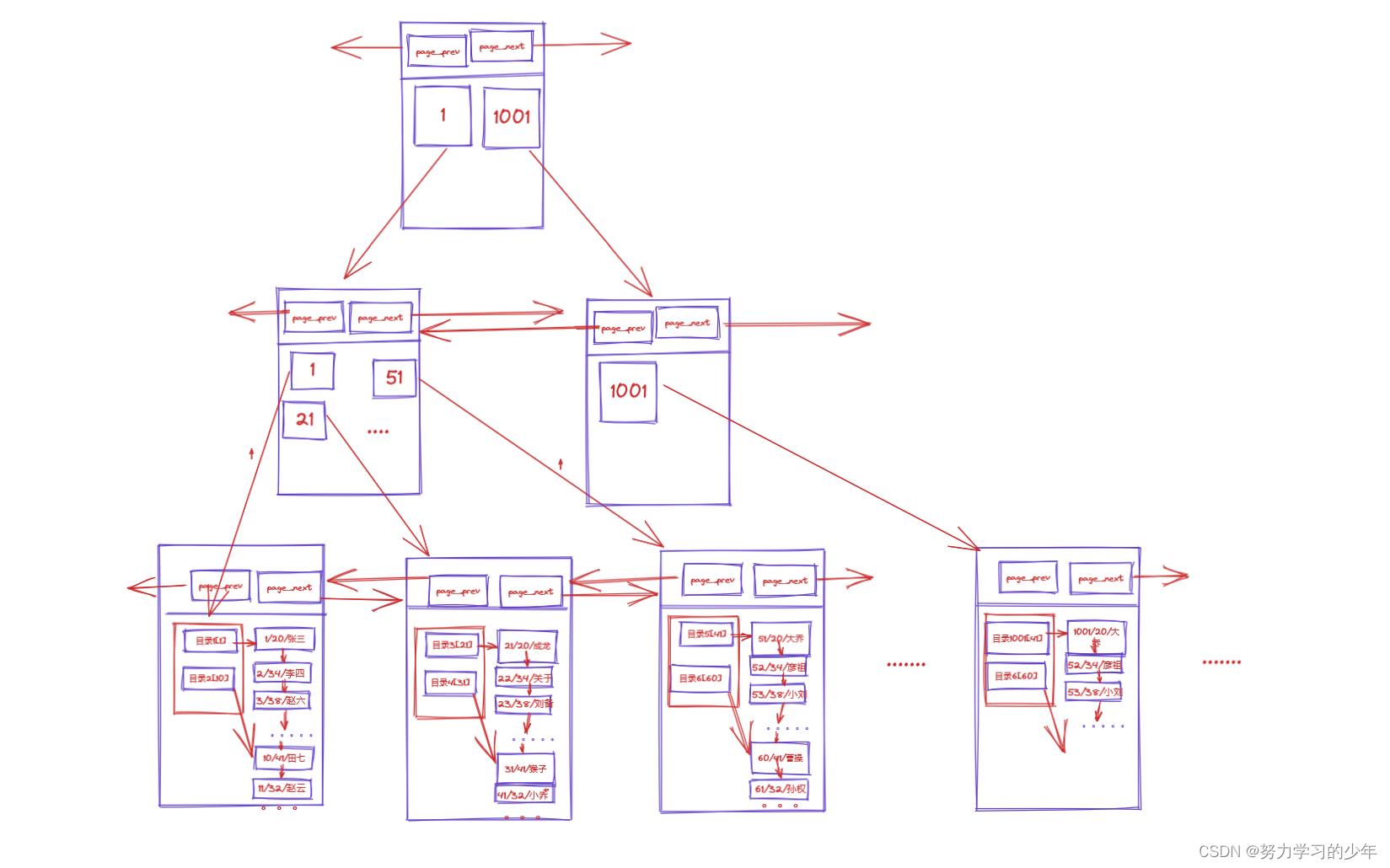
如上是MySQL存储数据的整体结构,整体结构就是我们常说的B+树。
如上树,如果我们刚开始要在MySQL中查找一个id值为1,它的查找过程:
- 那么首先会先将b+树的根节点的目录页加载到内存当中。
- 再通过id=1找到下一级的目录页,并加载到内存当中。
- 再通过目录页找到相对应的数据页,并加载到内存当中,并可以查找到相对应的值。
如上的过程加载了两次页目录,和一次数据页到内存中,一共进行了3次I/O.整个过程的I/O次数相对较少,因此可以提高搜索效率。
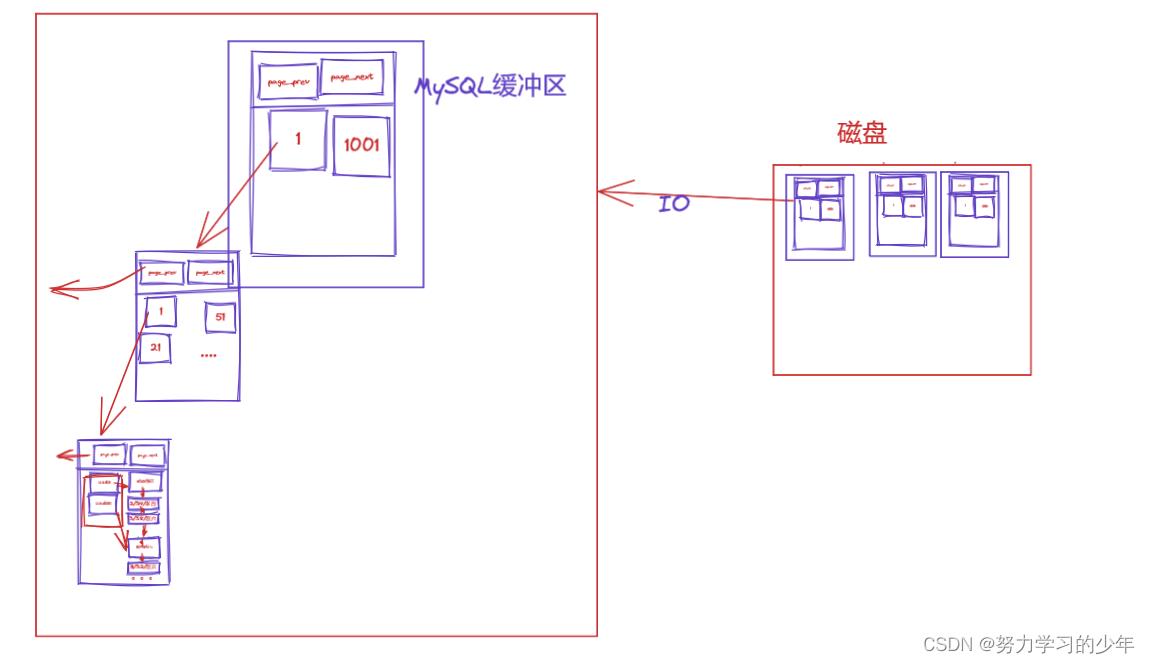
在内存当中是否为一整棵B+树?
不是,因为B+树是按需从磁盘中以页读取到内存当中,它在内存先可能将根节点目录页加载到内存当中,当要查找的时候在根据需求将相对应的页加载到内存当中,在内存当中可能只是b+树的一部分,如下:
InnoDB采用的是B+树来作为索引,B+树它的特点有:
- 只有叶子节点才会存储数据,非叶子节点仅用来存放目录项作为索引。
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量。
- 所有节点按照索引键的大小排序,构成一个双向链表,便于范围查找。
为什么不用B树来作为索引结构:
- 相比于B+树来说,B树的节点里面既有数据,又有指针,由于数据页的大小是固定的,所以节点存储的索引就会减少,那么B树的高度就相对较高,如果结构是B树的话,那么在查找的时候,进行I/O的次数相对来说会比较多。
- B+树的叶子节点全部相连,可以便于范围查找,而B树没有进行相连。
为什么不选用AVL树或者红黑树来作为索引结构?
AVL树和红黑树是二叉搜索树,如果数据过大,那么树的高度必定会更高,树的高度越高,MySQL与磁盘进行I/O的次数就越多,因此,会影响其查找效率。
四. 索引的分类
1.按结构分类
按结构分类有聚簇索引和非聚簇索引。
2.聚簇索引
用户数据和索引数据存放在一颗树上的方案称为聚簇索引。
如上,非叶子节点存放的是索引值,叶子节点存放的是MySQL中的数据。
InnoDB存储引擎采用的采用的就是聚簇索引结构。
3.非聚簇索引
非聚簇索引就是数据与索引分开,叶子节点存放的数据的地址,数据存放在另一张表中。如下:
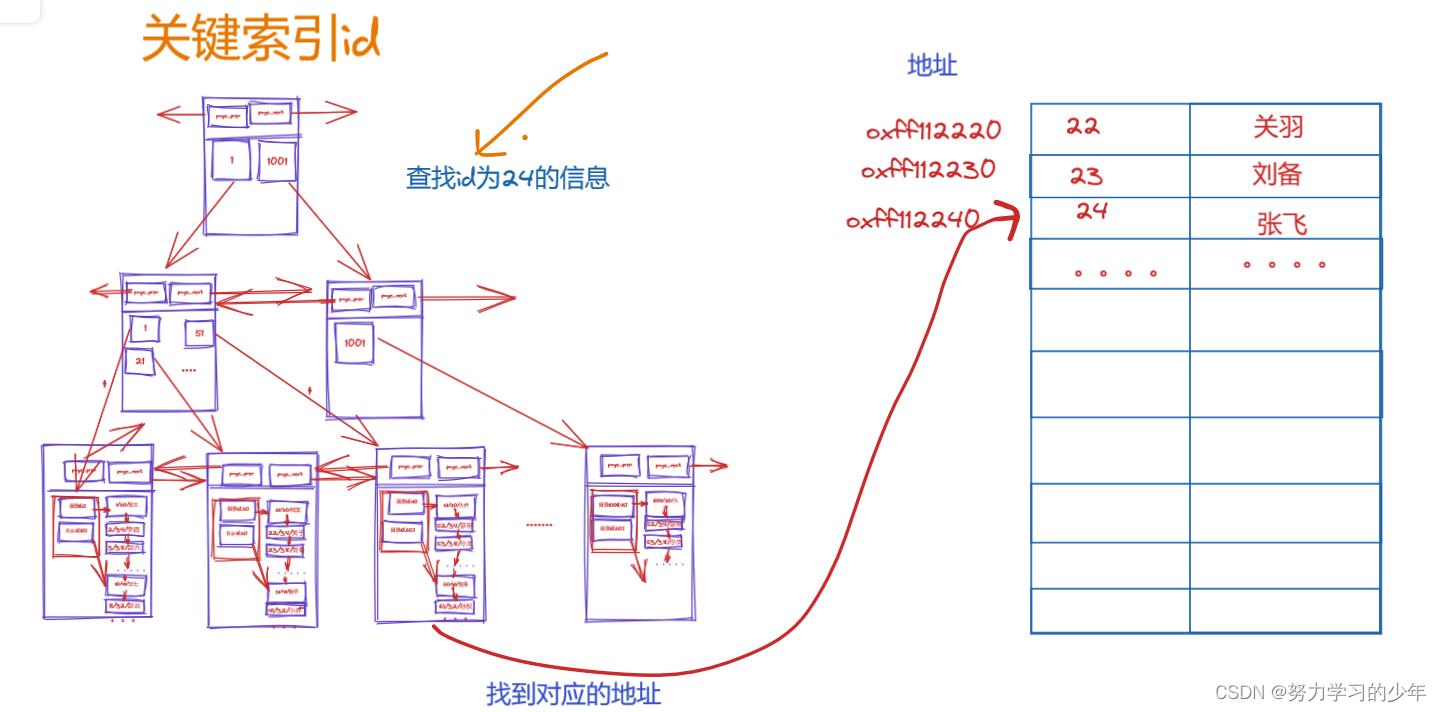
MyISAM存储特点就是非聚簇索引,它的叶子节点只存放数据的地址,通过地址在去另一张表里面找到相对应的数据。
实验
在数据库中创建一个存储引擎为MyISAM的表结构mtest。
mysql> create table mtest
-> ( id int primary key,
-> name varchar(12) not null
-> )engine=MyISAM;
Query OK, 0 rows affected (0.01 sec)
查看Mysql数据库目录路径,进入/etc/my.cnf文件 -> datadir=数据库的路径。
[root@iZwz97d32td9ocseu9tkn4Z mysql]# vim /etc/my.cnf
进入mysql数据库
[root@iZwz97d32td9ocseu9tkn4Z ~]# cd /var/lib/mysql查看mtest文件,MyISAM存储引擎结构为有3个文件进行存储。
ls 数据库名 -al 查看该数据库中包含的表结构

- mtest.frm为表结构。
- mtest.MYD为对应的数据,当前没有数据,所以是0。
- mtest.MYI为对应的主键索引。
创建一个存储引擎为InnoDB的表结构,表名为innodb_test.
 查看 innodb_test表结构
查看 innodb_test表结构
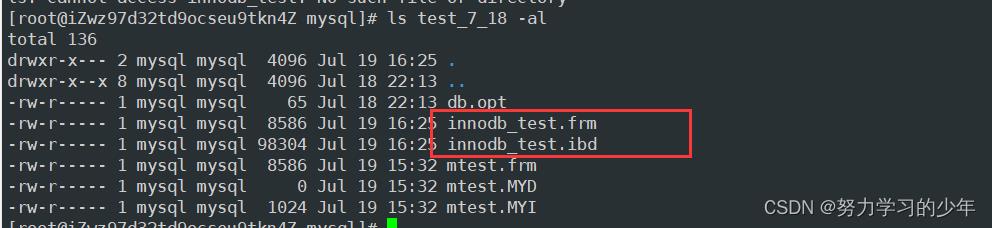
innodb_test.frm 表结构
innodb_test.ibd 索引和用户数据。
4.按字段特性分类
按字段分类,有主键索引,唯一键索引,普通索引。
主键索引
主键索引就是建立在主键字段上的索引,通常在创建表的时候,一张表最多有一个主键索引,索引列不允许为空值。每张表都有一个主键,如果没有主键,则MySQL会默认创建一个隐藏的主键值。
创建主键索引:
在创建表的时候,直接在字段后面加上primary key。
mysql> create table user1
-> ( id int primary key,
-> name varchar(12)
-> );
Query OK, 0 rows affected (0.09 sec)
唯一索引和普通索引(二级索引)
唯一键索引:一张表可以有多个唯一索引,索引列为空,但是允许有空值。
创建唯一索引,将id设置为唯一键索引:
mysql> create table user2(
-> id int unique,
-> name varchar(12)
-> );
Query OK, 0 rows affected (0.02 sec)
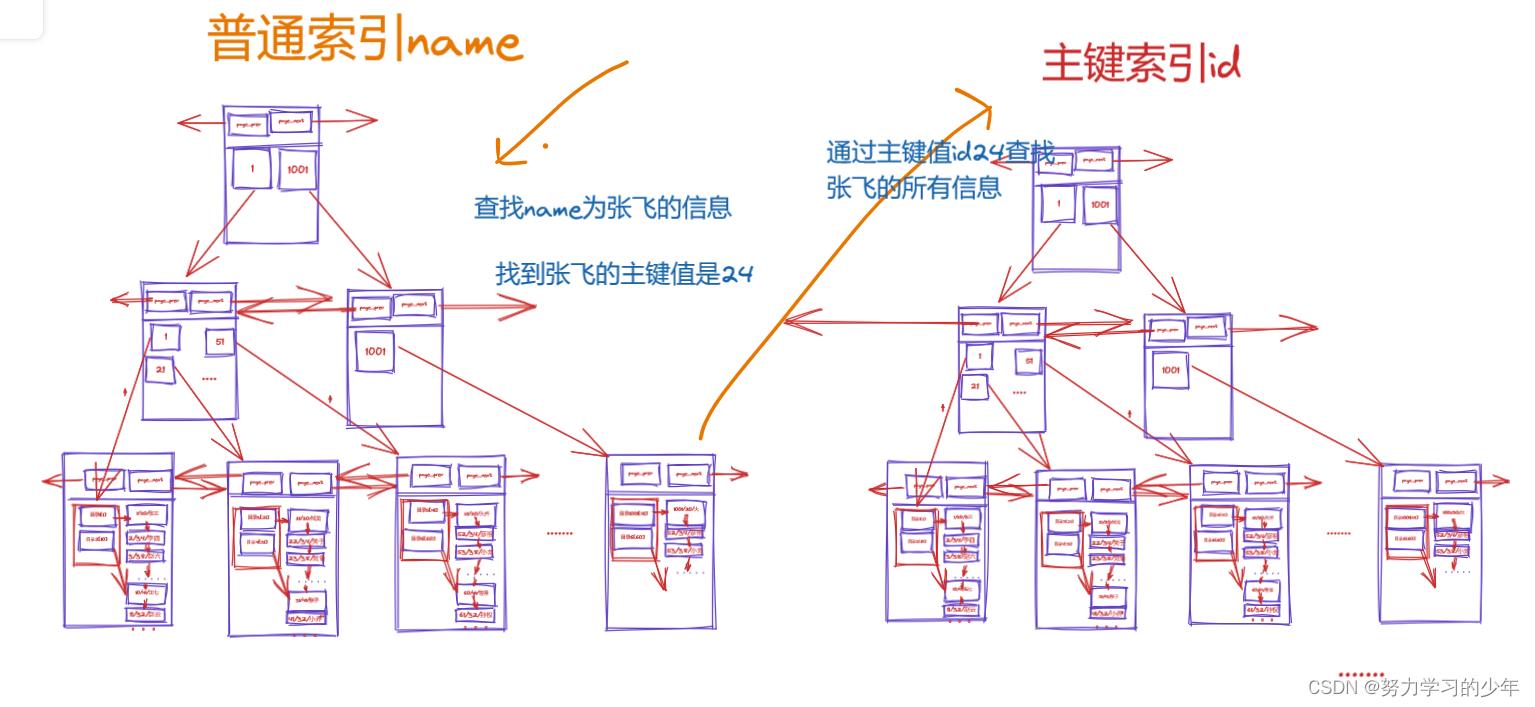
普通索引与主键索引的区别
InnoDB存储结构是聚簇索引,InnDB建立主键索引和普通索引的区别:
- InnoDB的主键索引的B+tree的叶子节点存放的实际数据,所有完整的用户记录都存放在主键索引的B+Tree 的叶子节点里。
- 普通索引的B+tree的叶子节点存放的是主键值,而不是实际数据。
所以,在查询数据使用普通索引查找,如果查询的数据能够在普通索引树里面查询的到,则不需要回表,这个过程就是索引覆盖。如果查询的数据不在普通索引树里面,则会在普通索引中查找它的主键值,然后在通过主键值,再去主键索引树去查找,这就叫做回表查找。
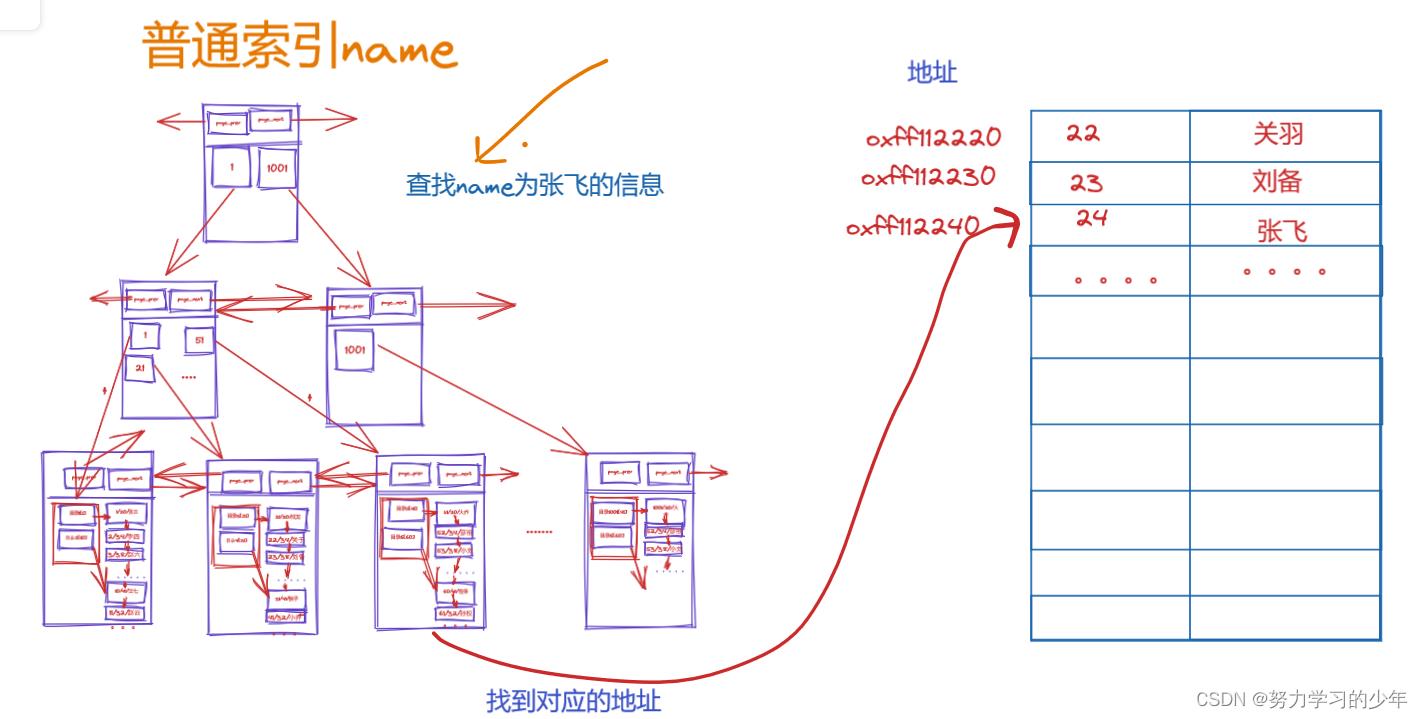
普通索引查找信息的过程:
- 通过name为张飞在普通索引中查找相对应的主键值24,然后通过该主键值24再去主键索引查找张飞的所有信息,如下:
MyISAM的存储结构是非聚簇索引,它的普通索引与主键索引是没有差别。
它们的索引树都是存放存放的是数据的地址,然后通过数据的地址找到相对应的值。
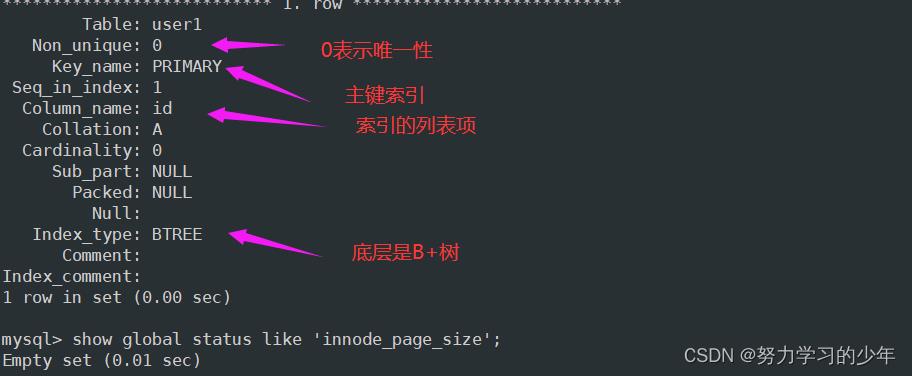
查询索引
show keys from 表名;
索引的创建原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段(增删查改)不适合作创建索引
- 不会出现在where子句中的字段不该创建索引
以上是关于Mysql——索引的深度理解的主要内容,如果未能解决你的问题,请参考以下文章