进程地址空间——学习笔记
Posted 正义的伙伴啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进程地址空间——学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
进程地址空间的划分
我们在学习C/C++的时候一直会涉及一个概念——地址,以前一直以为地址和物理内存是一一对应的
现在才知道我们以前在语言层面所理解的地址,实际上是虚拟地址,与真正的物理的内存是独立的,并且学习完进程的概念之后,对于一个多进程的程序,他们的进程地址空间是相互独立的
用一段代码来证明:
#include<stdio.h>
#include<unistd.h>
int main()
int g_val=1;
int ret=fork();
if(ret==0) //子进程
int count=5;
while(count--)
printf("子进程:g_val == %d &g_val==%p\\n",g_val,&g_val);
sleep(1);
g_val=2;
while(1)
printf("子进程:g_val == %d &g_val==%p\\n",g_val,&g_val);
sleep(1);
else
while(1)
printf("父进程:g_val == %d &g_val==%p\\n",g_val,&g_val);
sleep(1);

子进程在对g_val修改前后分别打印,而父进程一直打印,我们发现虽然g_val的值别修改了,但是他们的地址并没有改变,如果该地址对应的是物理内存上的地址,那是完全不可能出现地址相同,值不同的情况,所以在物理内存和进程之间应该还有一层地址空间——进程地址空间
进程地址空间示意图
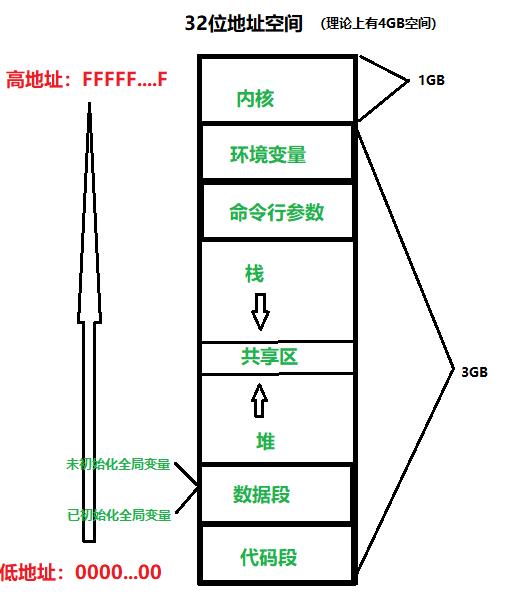
虚拟地址就是我们在语言层面看到的16进制的编码,这些编码是连续递增的,那么这些编码(地址)所组成的集合叫做 线性地址空间,在操作系统中又叫做虚拟地址空间
我们用这些递增的线性地址空间的最大地址所需要的位数来描述一个 进程地址空间的大小 32位或者64位的地址空间分别对应的地址的最大值为 2^32 、2^64
虚拟地址 在我们学习语言的时候,按照地址从低到高会被分成许多个区块(以64位为例)
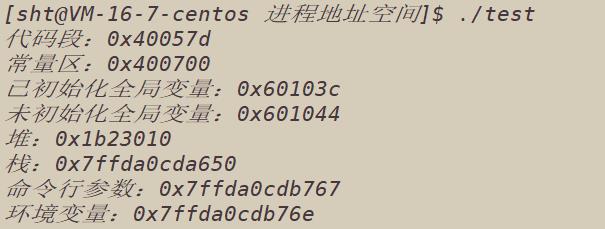
下面用代码来证明一下,虚拟内存中不同区域的地址大小关系:
1 #include<stdio.h>
2 #include<stdlib.h>
3 int val2; //未初始化全局变量
4 int val1=2; //已初始化全局变量
5 int main(int argc,char *argv[],char *env[])
6
7 printf("代码段:%p\\n",main);
8 const char *p="hello world";
9 printf("常量区:%p\\n",p);
10 printf("已初始化全局变量:%p\\n",&val1);
11
12 printf("未初始化全局变量:%p\\n",&val2);
13
14 int *t=(int *)malloc(4);
15
16 printf("堆:%p\\n",t);
17 printf("栈:%p\\n",&t);
18
19 printf("命令行参数:%p\\n",argv[0]);
20
21 printf("环境变量:%p\\n",env[0]);
22
23
运行结果如图:
那么内核中是如何维护一个像上面一样内核空间,内核创建了一个专门的结构体mm_struct来维护,其中各个分区是是将线性地址空间划分成一个一个的area[start,end] ,所以只要表示该分区的start和end就可以维护分区。
截取内核中一段关于分区的定义
struct mm_strucrt
//..............................
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
//start_code:代码段的起始地址
//end_code:代码段的结束地址
//start_data:数据段起始地址
//end_data:数据段结束地址
unsigned long start_code, end_code, start_data, end_data;
//start_brk:堆的起始地址
//brk:堆的结束地址
//start_stack:栈的起始地址
unsigned long start_brk, brk, start_stack;
//arg_start,arg_end:参数段的起始和结束地址
//env_start,env_end:环境段的起始和结束地址
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
// ...................................
可以把进程地址空间比喻成一把尺子,每一个刻度是一个地址,而分区是尺子上一段区间。尺子的总长度是确定的,只要一个进程被创建就会发一把这样的尺子,进程存储数据时只要记住存放的尺子的刻度,然后操作系统根据尺子的刻度经过一系列操作存储到磁盘上。那么每个尺子的长度一样长的话理论上每个进程都要独占内存4GB(32位的进程地址空间是4GB),那么一个物理内存为4GB的硬盘就只能运行一个进程吗?
实际上并不是,这就是进程地址空间设计的巧妙之处,他是操作系统看待内存的一种方式,以一种统一的方式(尺子)看待每个进程的存储,同时也让每个进程认为自己独占内存。你在尺子的刻度上存储数据实际上还是要os去物理内存上申请空间,即使你尺子长4GB但是你存放数据时os到物理内存上发现没有空间了,你就无法存放数据了,但你自始至终认为自己有4GB的存储空间,你的分区也是按照尺子刻度划分的。
进程地址空间 & 物理内存
物理内存和进程地址空间又有上面联系呢?
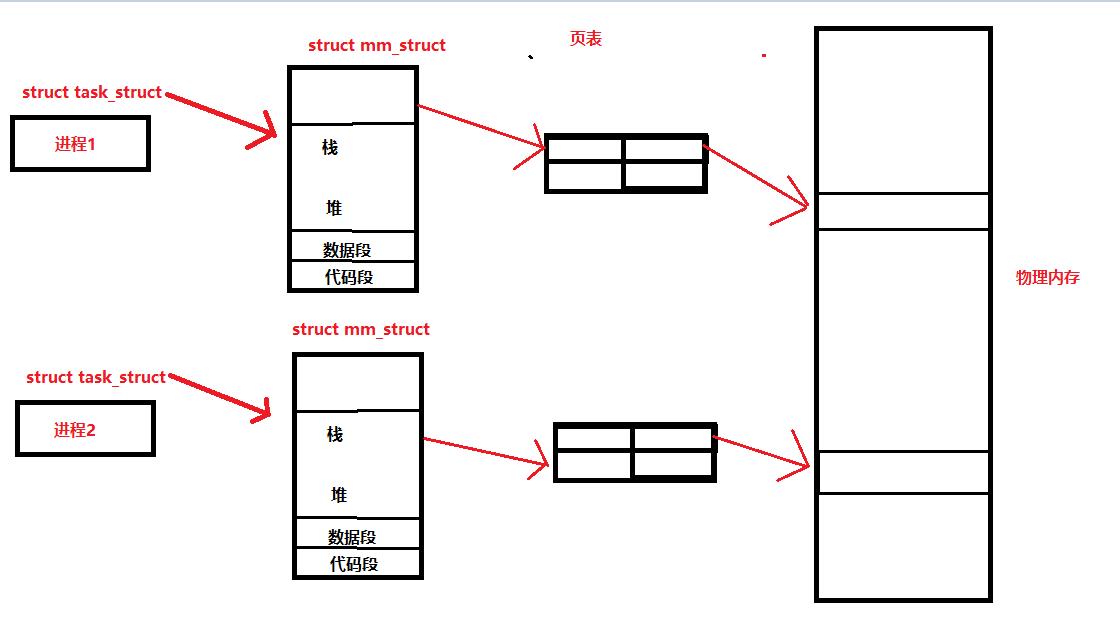
页表是虚拟地址到物理地址的转换,由操作系统完成这部分操作。
分页
如果页表中虚拟内存和物理内存一一对应的话,那么一个页表就需要32gb的存储空间(4GB个32位地址->4GB个32位地址 每个地址占4字节),显然页表不可能按照这种划分关系,所以就引入了分页的概念:
- 在虚拟内存上按照4kb进行划分,每一个4kb叫做一页
- 在物理内存上按照4kb进行划分,每一个4kb叫做页框
按照32位进程地址空间,一个地址有32位,我们把这32位分为两个部分
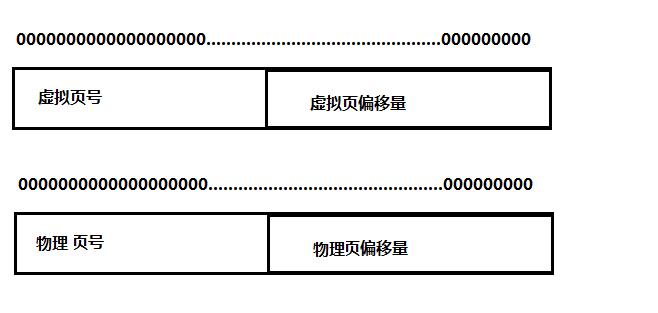
偏移量是由页的大小所决定的! 如果页或页框为4kb也就是二进制的12个位作为偏移量,因为物理和虚拟页面都是P字节的, 所以物理页面偏移和虚拟页面偏移是相同的 ,剩下来的20位就是页表项的数量(大概有1mb),所以映射关系就可以建立出来了:
页表

页表就是一个页表条目(上图每一行)数组,虚拟地址空间中的每个页的每个偏移量都与页表中一行相对应,也就是说虚拟地址是页表的索引。页表中含有的数据信息包含:有效位、物理页号。
所以我们要通过一个虚拟地址找到物理地址流程如下:
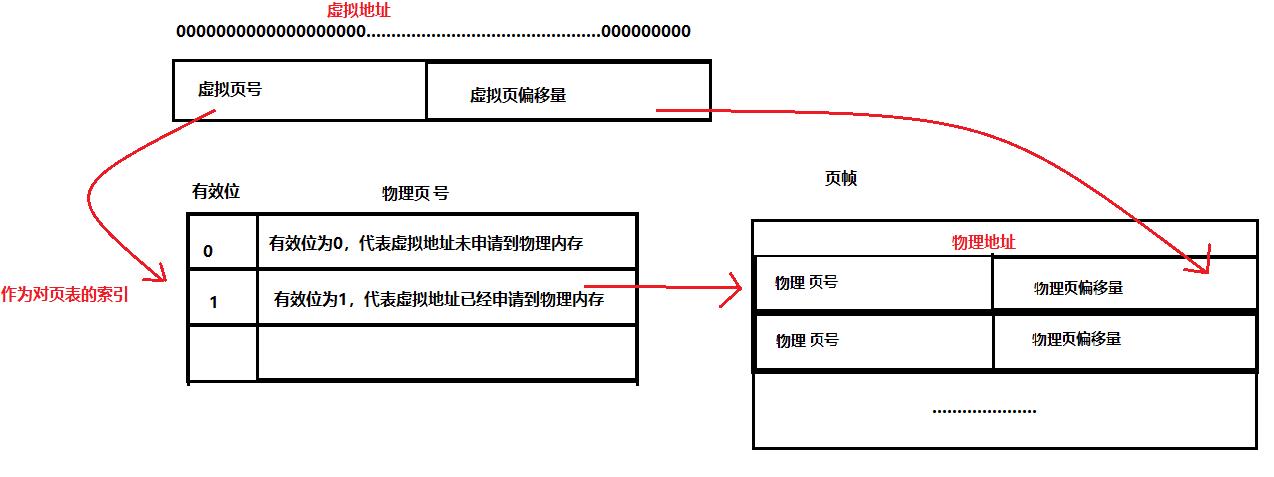
页表的设计是为了大大降低映射关系的存储空间,上面是一级页表,其实还有多级页表,例如二级页表:
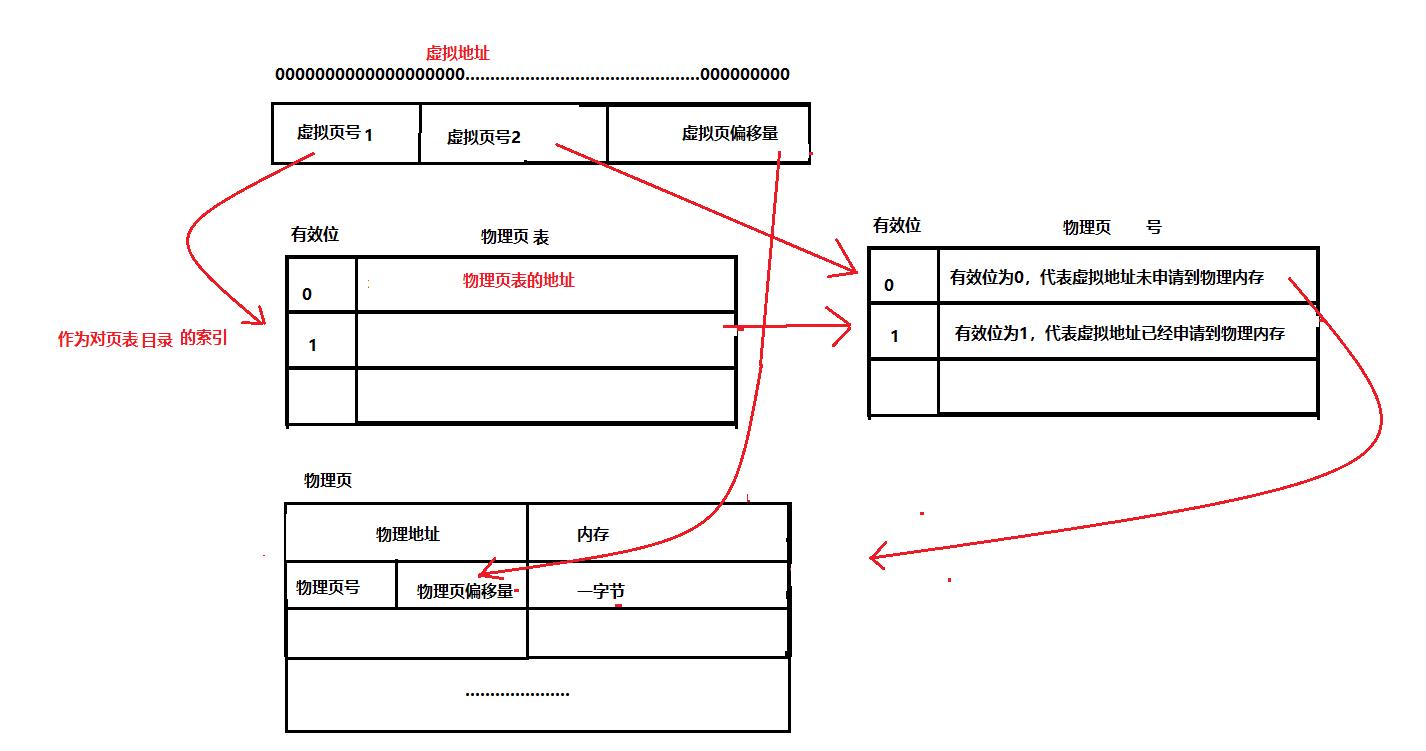
如果是一个二级页表的话,虚拟地址是按照 10(虚拟页号1) + 10(虚拟页号2) + 12(页偏移量)
前十位是页表目录的索引,页表目录索引的内容是页表的地址,得到页表的地址,接下来用虚拟页号2作为索引,找到的内容是物理页,最后由于虚拟页偏移量和物理页偏移量是相通的,于是就可以写出物理地址->找到对应的内存空间
为什么需要进程地址空间
进程地址空间一直伴随着进程的产生到结束,在进程的整个生命周期内一直存在,那为什么要创建一个进程地址空间的概念?不能直接访问物理内存吗?
- 保持进程的独立性:例如我们在学习语言时遇到的指针越界问题,实际上是对其他不属于我们空间进行了修改,如果是一个进程可以直接访问物理地址的话,那么内存就会被随意篡改
- 将内存管理和进程管理进行独立管理:内存管理MMU只需要关心页表上的问题,进程管理只需要管理进程的状态,存储方面就可以交给MMU判断
- 让每个进程以同样的方式看待代码和数据,同时也让进程认为自己独占了内存!
以上是关于进程地址空间——学习笔记的主要内容,如果未能解决你的问题,请参考以下文章