Webpack打包流程细节源码解析(P2)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Webpack打包流程细节源码解析(P2)相关的知识,希望对你有一定的参考价值。
参考技术A 此篇博客紧承上一篇,上片讨论了我们的webpack整个处理单个文件的流程,这一节主要说一说webpack的文件打包问题,其实本身是比较简单的,但是有异步块和html-plugin的加入,使这个步骤变得尤为复杂,这里先介绍几个重要的概念:上一节中,我们成功的对每个文件进行了处理,并通过了process的方法对所有入口文件以及他们的依赖文件进行了处理,获得了最初的依赖文件列表,现在我们就可以对资源的依赖进行优化处理,本片的内容将从webpack/lib/Compiler.js:510的断点开始逐步的对源码进行分析
在seal之前,由于一轮compilition已经执行完成,先调用finish方法进行收尾处理与之对应的是我们注册的finish-modules事件,
这里我们首先看到的又是index.ejs这个老朋友,由于他是单独的文件经过了loader处理没有获得额外的处理函数的依赖,所以最终这里看到的module实际上是它的js外壳包起来的ejs文件,此阶段也还没有进行资源hash的注入等等
这里有一个FlagDependencyExportsPlugin进行了操作,听名字可能就听出来了,他是对我们资源中的export使用进行一个标志的作用, 和我们最终做出的tree shaking效果可能是相关的
调用seal事件处理
处理我们的preparedChunk,这个东西是我们刚好在进行addEntry的时候添加上的不知道你们还记不记得,中途就没有添加过新的,所以讲道理,一个entry是只用一个的,但是这里使用了一个数组不知道有什么用意
然后把这个入口模块添加到了block里面,过后打包也是从block里面拿数据,block里面的东西会被打包成为单独的文件,但是还是工作在之前的上下文中,这里可以通过看一下这里的import即是我们之前在路由文件中通过import函数设置引入的动态加载路由资源
进入到processDependenciesBlockForChunk函数,就开始处理我们之前做好准备的block了,这里这是一个不断处理依赖的过程,但是没有使用递归的做法,毕竟文件太多了,不断的进行递归会浪费很多空间,取而代之的是使用queue进行记录,处理过程中不断把新的需要处理的模块放到queue里面等待下一步处理
在每一步的处理中
处理完这一波循环依赖过后,本身的依赖树结构变得扁平化,之前一层一层的模块通过dependency连接起来作为一个树的结构,而现在变成了顶层最终的几个chunk
可以看到我们最终在这个入口(entry)设置中拿到了9个chunk,她们都有_modules属性,我们的所有依赖都是放到这里面的,是用的一个Set进行存储,其中的依赖关系则是通过origins和reason等标识进行模块间关系的连接的
还可以将我们的入口chunk和异步加载的chunk进行一些对比(上面的是入口文件),下面的chunk中出现的origins就是指向我们之前的router那个module
这个图里也可以看到,两个chunk实际上按照自己的路子搜集了所有的依赖,结果导致了_modules的文件数量都达到了一千多个,这就是我们常使用的CommonChunk插件需要处理的地方了,稍后进行讨论
这轮处理我们成功的把主要的入口module和异步加载的模块区分开了,然后开始按照类似的逻辑处理我们的第一个入口模块
这个时候拿到chunkDependencies进行处理,这就是之前那个存储block的东西,但是有个很奇怪的地方,就是这里面居然只有三个chunk,而不是和上面的一样是9个也不是只有一个入口模块,这就让人无从下手了(我异步加载的模块并不是一样的,而且这些模块之间没有没相互依赖)
喜闻乐见进行第二次处理,首先取出一个chunk拿到对应的存储在value中的deps,对每一个项目添加上了他们的parent,但是有个组件就是用来removeParent的
在RemoveParentModulesPlugin这个插件中,针对每个module都做了处理,看看这些模块在哪些chunk之中有被使用到,把他们所存在的chunks按照id记录下来,并改变她们的reason为几种统一的chunk组合数组。这样就做到了每个module知道了自己被哪些chunk使用,但是从之前的单一reason到现在的多reason具体不知道有什么用(恩。。可能是为作用域提升做准备)
然后嘛,移除空的模块,不需要多解释
然后这层处理就算完啦,主要进行了模块的依赖梳理和拆分,并为他们添加上了指向父节点的指针(话说之前不是有origins吗)
对模块进行排序工作,不过只是按照索引进行排序罢了,那个按照出现概率进行排序处理的插件不是在这里工作的
又是那个flag的插件进行了处理,但是只是把所有模块的used设置为了true,还有为一些被依赖的module设置上他们的usedExports为true
ChunkConditions插件用于监视模块上是否有chunkCondition函数,并返回他的执行结果,如果有模块的此函数返回了false,那么将会重写这个模块(重写即是重新添加进入parent的链接以及reason等的设置)并且还会返回true,到至此过程不断执行直至condition全部OK
RemoveParentModulesPlugin这个插件的作用有点玄乎,看样子是对每个chunk进行处理,看对于多个chunk中都有的某一些module,会直接把他们的reason设置为主要的入口chunk,而后把当前chunk中的module移除掉(话说这个事情不是应该Common来做吗)
然后移除所有空的模块,再就是移除重复的模块了(话说一直用set神他妈还会有重复的)
然后进行各种优化,比如出现的概率大的放到前面,这里还是做了module和chunk两种优化,也是有毛病,就像我们的react项目中可以知道react的使用次数最多,那么他就被放到了最钱前面,紧随其后的是echart等
HashedModuleIdsPlugin插件为我们的模块计算出它的id,默认是通过md5进行计算,解出来的是base64的,而且计算的参数也仅仅只是通过模块的libId进行hash,而这个libhash只是相对位置,连绝对的都不是,所以算下来这个东西能够当成单个文件的hash了
applyModuleId,到这里你可能会想,诶之前不是已经设置好每个元素的id了吗,为什么还要搞这么个函数专门处理,我们在上一个生成id的时候实际上得到的id是根据我们的设置进行了截断的,实际上拿到的hash碰撞的概率非常大,我们看看下面这个筛选的处理就可以知道,1885个模块里面竟然又3个重复的id,这种时候就要特殊处理了
执行sortItemsWithModuleIds依据id进行排序,不只是最外面的chunk,就连reason里的id也会被重新排序,也是蛮逗的,这里直接用的是id做比较并没有判断类型,也就是说把数字和字符串会混到一起,就算你是class也会拿valueOf出来比较,想想还是蛮刺激的,不过其实比较完成也没有太特殊的用途就这么随意一点也好
中间一些处理recordId的我忽略掉了
然后开始处理hash了,这里的hash具体使用了哪些参数和长度是多少呢
可以在此阶段添加hashSalt即噪声,给hash值添加一些特征
进入mainTemplate的处理函数中,添加了一些字符串参数和数字参数,并且调用了mainTemplate的hash插件,但是她们的执行过程并不是保证我们最后生成的文件中能够有结果的hash值,便于请求对应的资源文件,而是仅仅在hash的过程中添加了一些干扰的路径参数等
最终一轮hash下来,chunk会得到自己的renderHash,而compilation会得到一个针对编译过程的hash,这个hash就跟我们的所有资源扯上关联啦,所以每次都是新的
创建模块资源咯~
这些文章写的都有点水,相当于是阅读源码时候做的笔记了,看看图个乐子吧
.16-浅析webpack源码之打包无关流程梳理
这节把编译打包后的流程梳理一下,然后集中处理compile。
之前忽略了一个点,如下:
new NodeEnvironmentPlugin().apply(compiler); // 引入插件加载 if (options.plugins && Array.isArray(options.plugins)) { compiler.apply.apply(compiler, options.plugins); } compiler.applyPlugins("environment"); compiler.applyPlugins("after-environment"); compiler.options = new WebpackOptionsApply().process(options, compiler);
在compiler对象的fs模块挂载完后,会对传入的插件进行加载,这个过程在内置插件加载之前。
插件部分单独讲解,所以这个地方先暂时略过。
剩余流程如图:
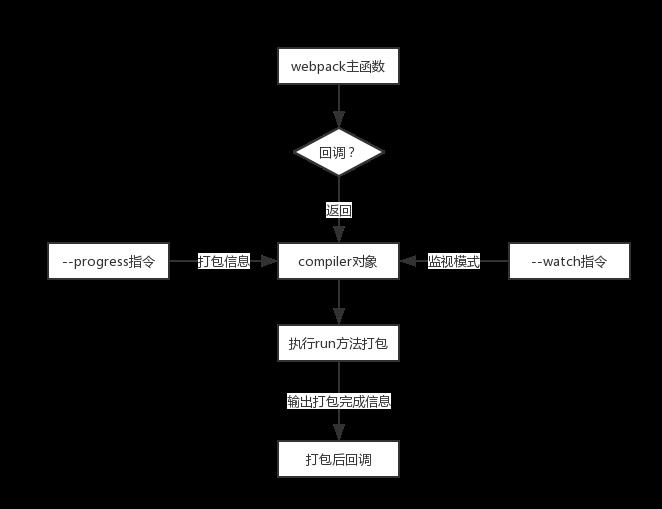
内置插件全部plugin完毕后,会检测编译的回调函数:
if (callback) { if (typeof callback !== "function") throw new Error("Invalid argument: callback"); // 检测是否有watch选项 if (options.watch === true || (Array.isArray(options) && options.some(o => o.watch))) { const watchOptions = Array.isArray(options) ? options.map(o => o.watchOptions || {}) : (options.watchOptions || {}); return compiler.watch(watchOptions, callback); } compiler.run(callback); }
vue-cli的脚手架生产模式的构建文件build.js中就很明显的传了一个回调函数:
webpack(webpackConfig, (err, stats) => { /**/ })
这里的回调函数主要是输出一些打包信息,包括打包文件的状态、打包错误提示、打包完成提示等等。
暂时不管这个回调,因此会直接返回compiler,回到预编译的webpack.js文件中。
又回到了久违的bin/webpack.js,后面的流程简化后源码如下:
try { compiler = webpack(options); } catch (err) { /**/ } // --progress用于输出打包信息 if (argv.progress) { var ProgressPlugin = require("../lib/ProgressPlugin"); compiler.apply(new ProgressPlugin({ profile: argv.profile })); } // 输出打包信息的回调函数 function compilerCallback(err, stats) { /**/ } // 如果有watch则打包后进程持续进行监视 if (firstOptions.watch || options.watch) { /**/ } // 直接编译 else compiler.run(compilerCallback);
在返回compiler对象后,此时还未进行打包操作,只是准备好了一切,剩余的几步如下:
1、检测--progress指令,该指令用于将进度输出到控制台
2、检测--watch指令或者配置文件中的watch参数,如果有,则打包完后持续检测相关文件,发生变动立即调用打包操作
3、没有配置watch则直接进行打包操作,打包完成后调用回调函数
progress这个可以自己去尝试,可以想象成安装程序那个界面。
watch指令作用如图: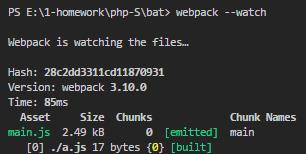
打包完进程并不会退出,当修改入口文件并保存后,会立即打包并刷新提示输出信息。
这里先暂时不管watch。
最后一步就是打包的操作:
compiler.run(compilerCallback);
传入的回调函数只是负责输出打包信息,源码如下:
function compilerCallback(err, stats) { // 非watch模式下清理缓存 if (!options.watch || err) { compiler.purgeInputFileSystem(); } // 错误处理 if (err) { /**/ } // 输出打包信息 if (outputOptions.json) { process.stdout.write(JSON.stringify(stats.toJson(outputOptions), null, 2) + "\\n"); } else if (stats.hash !== lastHash) { lastHash = stats.hash; var statsString = stats.toString(outputOptions); if (statsString) process.stdout.write(statsString + "\\n"); } if (!options.watch && stats.hasErrors()) { process.exitCode = 2; } }
stats是打包后生成的信息,将其格式化后通过prcess,stdout.write输出,这个输出方式底层就是console.log,上面那个图中打包完成信息就是通过这行代码输出的。
至此,所以与打包过程无关的操作都已经完事,剩下的内容都集中在compiler.run这个调用中。
以上是关于Webpack打包流程细节源码解析(P2)的主要内容,如果未能解决你的问题,请参考以下文章