Python爬虫常用的几种数据提取方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫常用的几种数据提取方式相关的知识,希望对你有一定的参考价值。
参考技术A 数据解析方式- 正则
- xpath
- bs4
数据解析的原理:
标签的定位
提取标签中存储的文本数据或者标签属性中存储的数据 参考技术B re
BeautifulSoup
xpath
css
Python爬虫——数据解析
 从获取到的数据中筛选出我们需要的数据,这一步是非常重要的。数据筛选的方式有多种,在这里我只列举了我个人比较常用的几种。
从获取到的数据中筛选出我们需要的数据,这一步是非常重要的。数据筛选的方式有多种,在这里我只列举了我个人比较常用的几种。
1. re模块
之前我们在python基础中介绍过正则表达式,而re模块可以使用正则表达式对字符串进行很好的筛选。re模块的使用可以分为两种:第一种是对象式的方式,第二种是函数式的方式。之前已经介绍过正则模块的简单使用,我们在这里就直接进行案例操作。
案例:表情包爬取
将此页面下的前十页图片全部获取下来:https://fabiaoqing.com/biaoqing

通过网页分析发现每一个图片的地址都被放在了该标签下。
在浏览器地址栏中输入该图片的地址就可以找到这个图片。现在图片已经找到了,下一步就是对图片进行下载。那么如何通过代码去实现呢?
url=\'https://fabiaoqing.com/biaoqing/lists/page/6.html\'
resp=requests.get(url).text
print(resp)
通过刚开始打印的控制台的内容发现浏览器中的代码结构与控制台打印的并不太一样。因此我们在网页源代码中查看
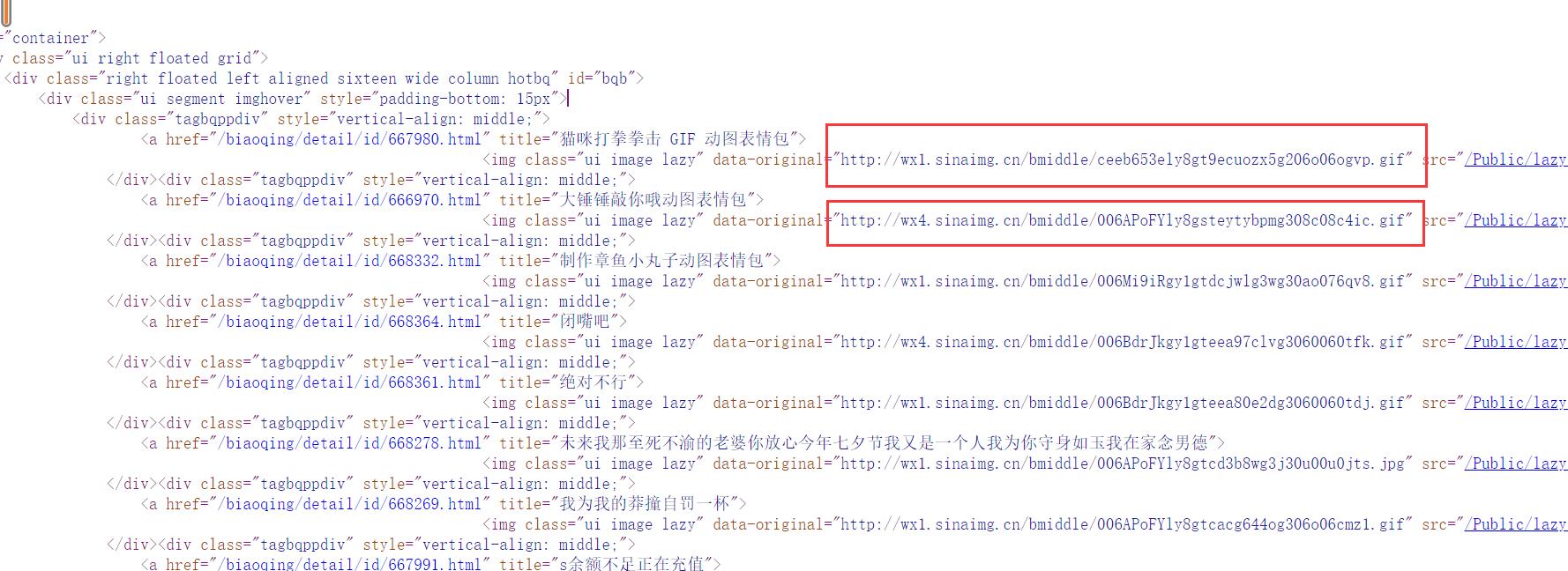
我们会发现每个图片的 URL 地址都在 data-original这个标签中,因此我们对该属性中的内容进行正则匹配,正则匹配规则为<img class="ui image lazy" data-original="(.*?)" 通过re.findall()来获得匹配到的内容,括号内的参数主要有三个,第一个是正则表达式,第二个是需要匹配的内容,第三个是匹配规则,在这里我们一般只需要记住第一个和第二个就可以了。
resp=requests.get(url)
img_src=re.findall(\'<img class="ui image lazy" data-original="(.*?)"\',resp.text,re.S)
匹配到的内容是一个列表,再遍历这个列表,依次对列表中的图片地址发送请求,因为是图片,所以它是二进制的形式,因此我们以二进制的形式进行保存,具体的完整代码请看文末附录一:
for src in img_src:
src_filename=src.rsplit(\'/\')[-1]
img_content=requests.get(src)
with open(f\'表情包\\\\第{page}页\\\\{src_filename}\',mode=\'wb\') as f:
f.write(img_content.content)
re模块对于新手来说,我们只需要记住表达式 .* ? 就可以了,将需要匹配的内容以 .* ?的形式,re模块就会进行贪婪匹配。如果对于re模块想要深入了解的话大家可以对正则表达式那一部分的知识点进行深一步的了解。
2. css选择器
在学习css选择器之前还需要安装一个对应的库 parsel。这个库内置了很多的数据解析方式,比如常见的css解析、xpath解析以及re模块都是内置的,使用起来十分方便。
pip install parsel
如果学过前端三件套的话,那么对于css选择器的理解与使用应该是非常容易的。所谓css选择器,其实就是当我们在写css样式时需要对某一个具体的标签进行的定位。在使用css选择器之前需要先创建一个selector对象,所有的内容都以selector的形式来读取,如果想要获取具体的标签内容或者是属性内容,则需要特定的语法。
2.1 标签选择器
标签选择器就类似于js中的 getElementbyTagName()一样,通过直接对标签定位来对同一类型的标签加样式。常见的标签有 < div > 、< span >、< p > 、< a > 等。通过直接绑定标签名称来获取标签。
import parsel
selector = parsel .selector(html)
span = selector.css( \' span \' ).getall()
print(span)
2.2 类选择器
类选择器就是通过标签中设定的class类来进行定位,定位到具有该类属性的标签,之后在进行获取。类的方式与css中的方式相同。
import parsel
selector = parsel .selector(html)
top = selector.css( \'.top\' ).getall()
print(top)
2.3 ID选择器
ID选择器在平时的使用中使用的比较多,因为同一个html文件中,id属性是唯一的,每一个id都对应一个标签,因此如果当获取的对象是唯一的,那么就可以使用id选择器。
import parse1
selector = parsel.selector(html)
p = selector.css ( \' #content \' ).geta11()
print(p)
2.4 组合选择器
在css进行样式修改时,如果权重不够,可以多个组合进行权重的增加,以此来让样式起到效果。
import parse1
selector = parsel.selector(html)
content = selector.css ( \'div .top\' ).geta11()
print(content)
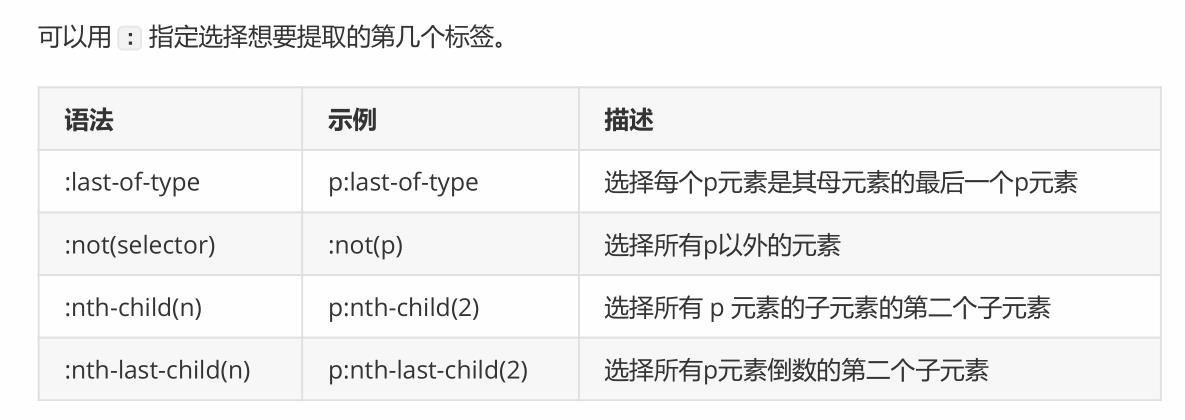
2.5 伪类选择器
伪类选择器在css样式的时候可能会多一点,但在爬虫中使用的很少,几乎没有,所以我们只作为了解内容即可。
import parsel
selector = parse1.selector(htm1)
p = selector.css( \'p:nth-child(2) \').getall()
print(p)
2.6 属性提取器
大多数情况我们在使用css选择器的时候需要提取的是文本内容,比如标签中包含的文本或者是属性的内容,比如src属性中的url地址。而且属性提取器的使用也非常的方便与简洁。其中获取标签中包含的文本内容的语法是" p: :text ",使用两个冒号来作为区分,而获取标签的属性内容则为" p: :attr(href)" 括号中是需要获取的标签的属性。
import parse1
selector = parse1.selector(htm1)
# p::text是获取p标签的文本内容
p = selector.css( \'p: :text\' ).geta11()
print(p)
# a::attr(href)是获取a标签的href属性
a = selector.css( \'a: :attr(href) \' ).getall()
print(a)
2.7 案例
上面已经介绍过css选择器的具体用法,下面让我们来给大家布置一个小任务:
使用 css 选择器将豆瓣 250 的全部电影信息全部提取出来。
title(电影名)、 info(导演、主演、出版时间)、 score(评分)、follow(评价人数)
目标网址:https://movie.douban.com/top250
进行操作之前我们还是要对网站进行分析,先要确定所要获取的内容是否直接在网页上,然后再确定它的请求方式。之后才正式开始进行数据获取。通过分析发现,索要获取的内容都在网页上,那我们直接获取就可以了。
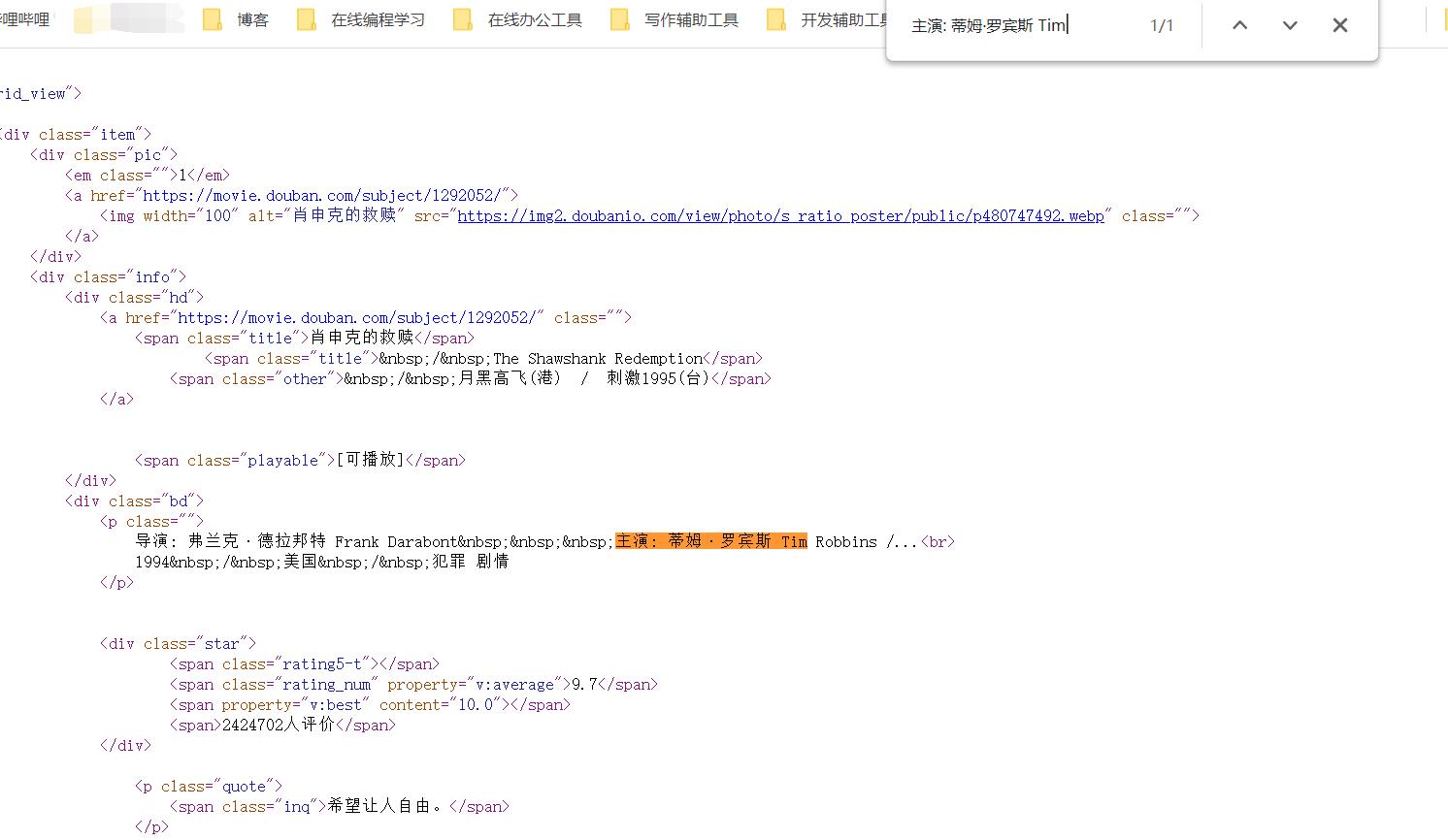
因为豆瓣网站有相对的反扒机制,所以需要我们添加一些请求参数,需要将headers以及cookies都添加上才能获取到数据
url = f\'https://movie.douban.com/top250?start={page}&filter=\'
headers = {
\'Cookie\': \'bid=nJ5mbBL3XUQ; __gads=ID=d4e33a95e1a5dad6-\',
\'Host\': \'movie.douban.com\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36\',
}
# 2. 发送请求
response = requests.get(url=url, headers=headers)
html_data = response.text
print(html_data)
通过控制台打印的内容比对发现我们需要获取的内容确实就在里面,因此从获取到的内容中进行筛选,使用css选择器进行选择。
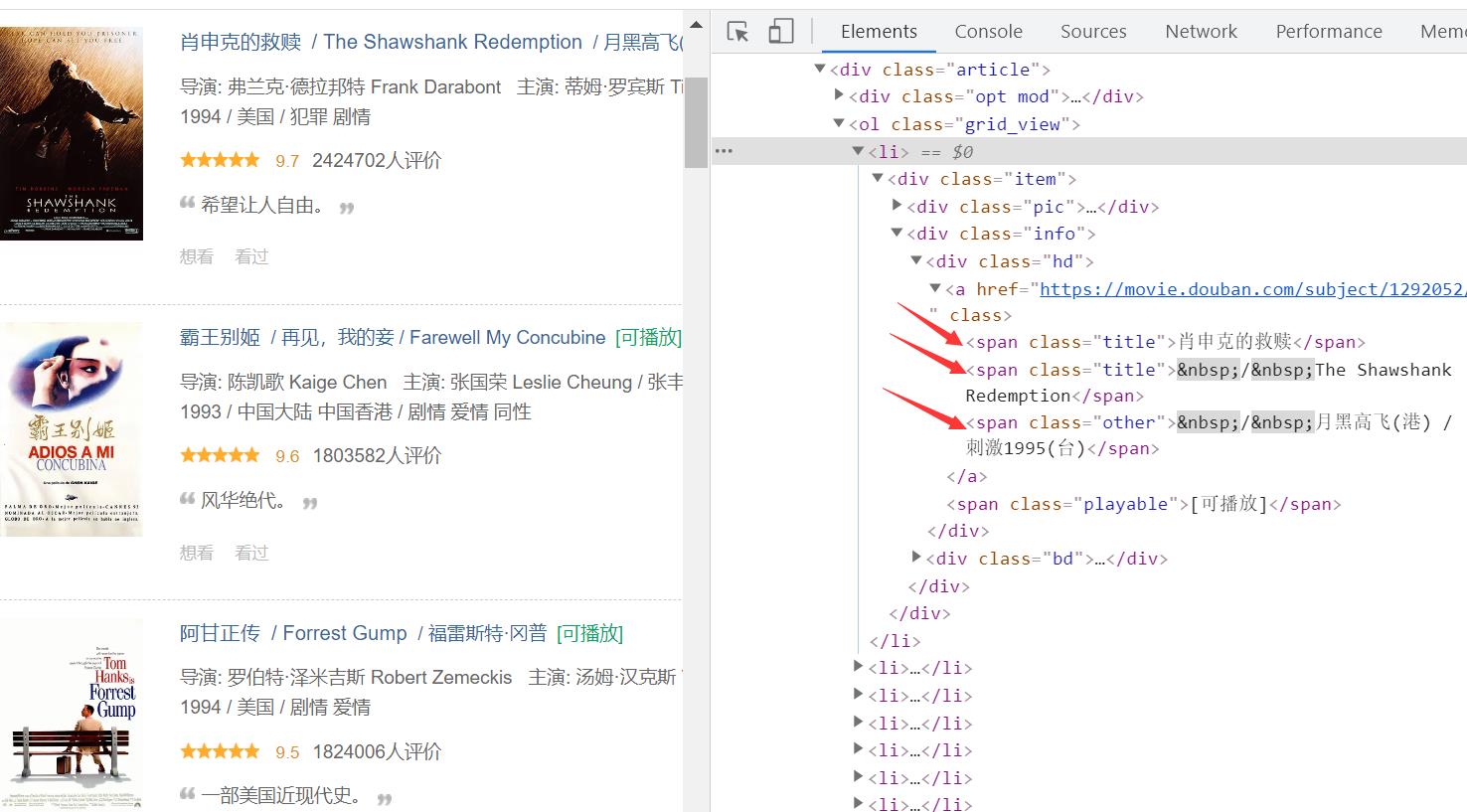
我们可以先获取所有的 li 标签,然后再遍历每个li标签,从中获取我们想要的相关信息。
selector = parsel.Selector(html_data)
lis = selector.css(\'.grid_view li\') # 所有li标签
for li in lis:
title = li.css(\'.title::text\').get() //获取title文本
info = li.css(\'.bd p:nth-child(1)::text\').getall()
score = li.css(\'.rating_num::text\').get()
follow = li.css(\'.star span:nth-child(4)::text\').get()
print(title, info, score, follow)
通过运行代码就可以发现我们已经将数据获取到了,对于获取的数据只需要做一些处理就是我们需要的数据。需要完整代码请直接到文末附录二。

3. xpath数据解析
3.1 认识xpath
XPath是一门再HTML\\XML文档中查找信息的语言,可用在HTML\\XML文档中对元素和属性进行遍历
对于一些xml文件的内容和节点的遍历,我们可以使用xpath来获取。xml文件被用来传输和存储数据,也是由成对的标签组成,但标签是自定义的。xml主体呈现树状结构,跟html类似,也是有父子关系的标签,而节点与节点之间的关系就类似于我们人类生活中的族谱,有亲兄弟关系、父子关系、同级关系等。
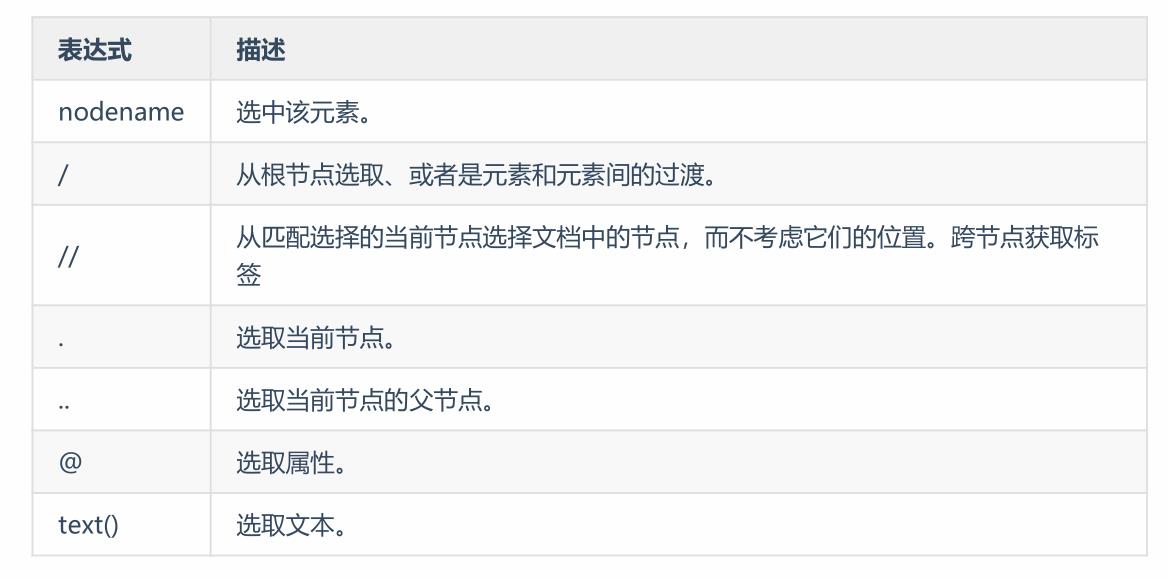
3.2 xpath的语法
xpath中的常用语法主要就如下这些,掌握了这些对我们日常爬虫也是足够了。在使用时与主要理清节点与节点之间的层级关系就可以了。
3.3 案例
目标网址: https://nba.hupu.com/stats/players/pts
需求:
1、用xpath采集 nba 球员数据
2、采集以下信息
rank # 排名
player # 球员
team # 球队
score # 得分
hit_shot # 命中-出手
hit_rate # 命中率
hit_three # 命中-三分
three_rate # 三分命中率
hit_penalty # 命中-罚球
penalty_rate # 罚球命中率
session # 场次
playing_time # 上场时间
做完准备工作后我们开始对该网站的数据进行获取。每一个球员的数据都放在一个< tr >标签里面,因此我们可以先获取所有的 < tr > 标签,然后再遍历每一个标签,并从中获取相关的内容。
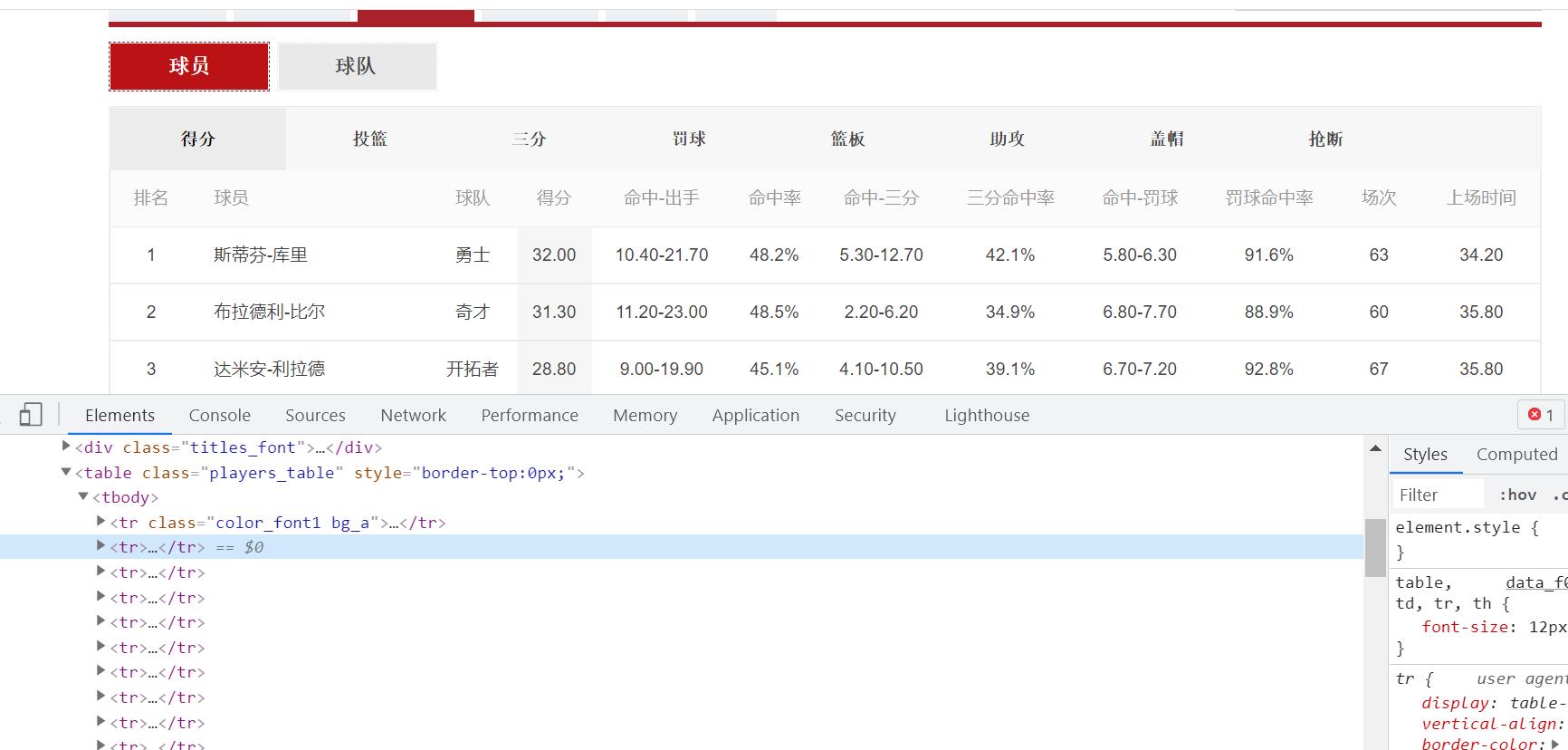
selector = parsel.Selector(html_data)
trs = selector.xpath(\'//table[@class="players_table"]/tbody/tr\')[1:] # 二次提取
获取到所有的tr之后再遍历每一个tr,从中获取球员的各项数据
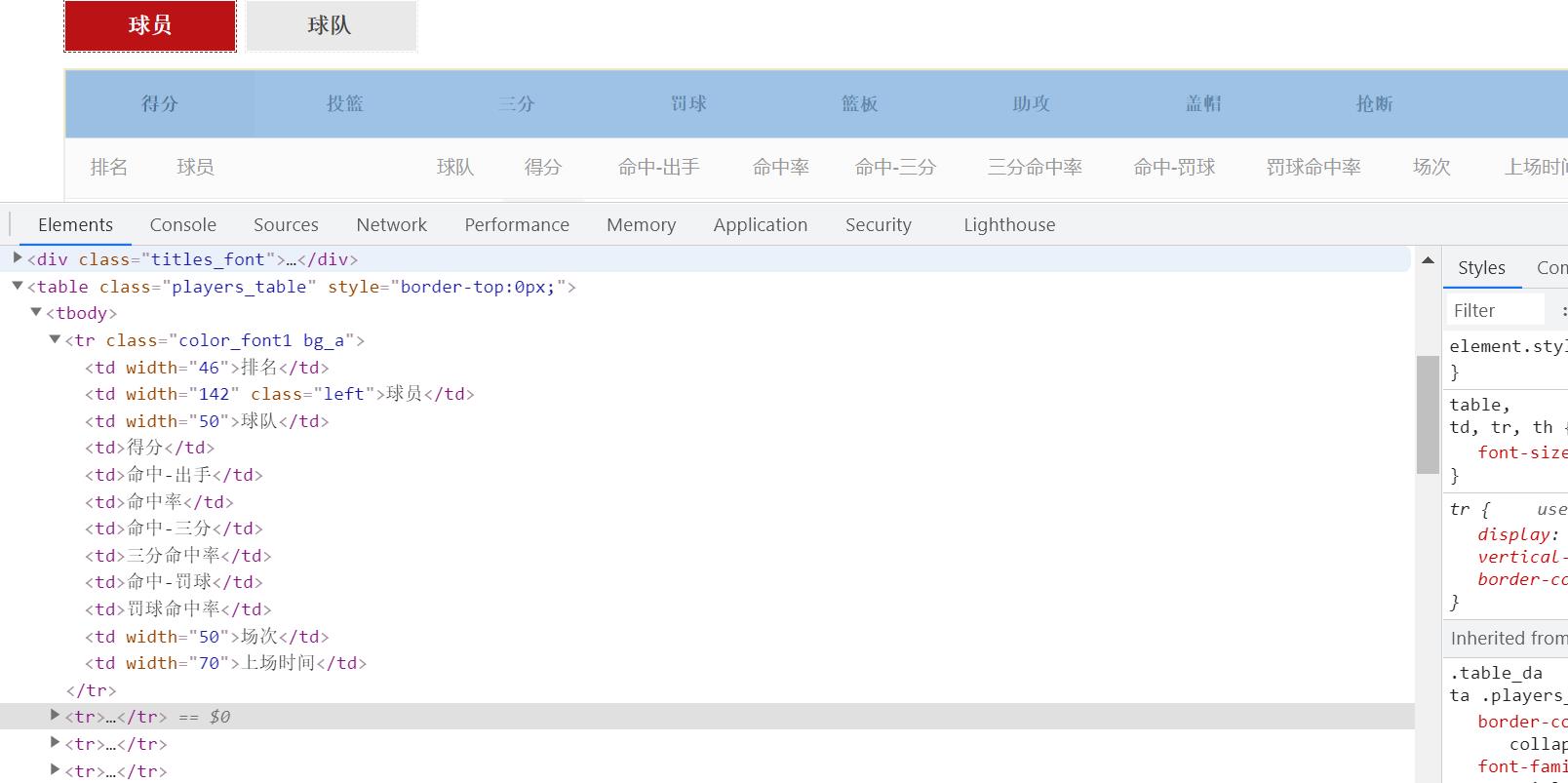
for tr in trs:
rank = tr.xpath(\'./td[1]/text()\').get() # 排名
player = tr.xpath(\'./td[2]/a/text()\').get() # 球员
team = tr.xpath(\'./td[3]/a/text()\').get() # 球队
score = tr.xpath(\'./td[4]/text()\').get() # 得分
hit_shot = tr.xpath(\'./td[5]/text()\').get() # 命中-出手
hit_rate = tr.xpath(\'./td[6]/text()\').get() # 命中率
hit_three = tr.xpath(\'./td[7]/text()\').get() # 命中-三分
three_rate = tr.xpath(\'./td[8]/text()\').get() # 三分命中率
hit_penalty = tr.xpath(\'./td[9]/text()\').get() # 命中-罚球
penalty_rate = tr.xpath(\'./td[10]/text()\').get() # 罚球命中率
session = tr.xpath(\'./td[11]/text()\').get() # 场次
playing_time = tr.xpath(\'./td[12]/text()\').get() # 上场时间
最后再将结果打印出来:
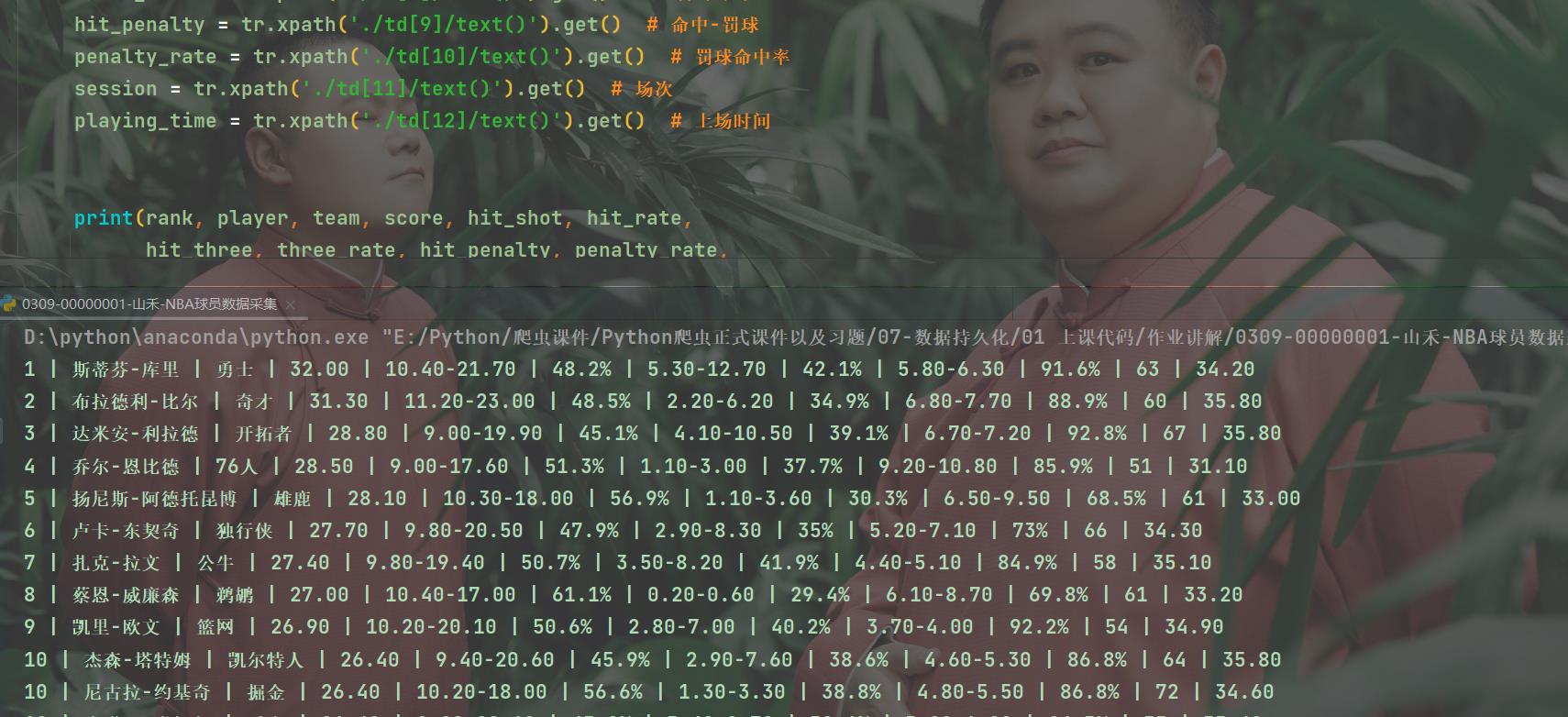
完整代码放在文末附录三。
4.总结
数据解析的内容到现在也已经介绍完毕。我介绍的只是常用的数据解析方法,当然还有很多数据解析的方法,比如Bautifulsoup、PyQuery……但是我上面介绍的这些已经完全足够了。每一种都能够获取想要的数据,只不过获取的方式有所不同。具体使用哪种方式取决于所要爬取的网页结构。这里需要注意的是我们在安装了parsel库之后就不需要另外再安装css以及xpath库了,在这里就可以直接构建selector对象并使用,还是十分方便的。如果大家对于爬虫有需求或者是有疑惑可以联系我。下一次给大家介绍数据持久化的方式,也就是我们常说的将数据保存为xlsx、csv、txt……等的一些格式,而不单单是打印出来,以便我们后续对数据进行操作。
附录一:
import requests
import re
for page in range(1, 11):
print(f\'----正在抓取第{page}页数据---\')
response = requests.get(f\'https://fabiaoqing.com/biaoqing/lists/page/{page}.html\')
html_data = response.text
# print(html_data)
# 数据解析
"""
<img class="ui image lazy" data-original="(.*?)"
"""
result_list = re.findall(\'<img class="ui image lazy" data-original="(.*?)"\', html_data, re.S)
# print(result_list)
for result in result_list:
img_data = requests.get(result).content # 请求到的图片数据
# 准备文件名
file_name = result.split(\'/\')[-1]
with open(\'img\\\\\' + file_name, mode=\'wb\') as f:
f.write(img_data)
print(\'保存完成:\', file_name)
附录二:
import parsel
import requests
for page in range(0, 226, 25):
print(\'-\' * 100)
url = f\'https://movie.douban.com/top250?start={page}&filter=\'
headers = {
\'Host\': \'movie.douban.com\',
\'Cookie\': \'bid=0Zh2xEHDtYQ; dbcl2="244637883:MwqForzW8Xw"; ck=5JFU; push_doumail_num=0; \'
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36\',
}
# 2. 发送请求
response = requests.get(url=url, headers=headers)
html_data = response.text
# 一定要对比数据,确认我们要的数据已经请求到了
selector = parsel.Selector(html_data)
lis = selector.css(\'.grid_view li\') # 所有li标签
for li in lis:
title = li.css(\'.title::text\').get()
info = li.css(\'.bd p:nth-child(1)::text\').getall()
score = li.css(\'.rating_num::text\').get()
follow = li.css(\'.star span:nth-child(4)::text\').get()
print(title, info, score, follow)
附录三:
import requests
import parsel
url = \'https://nba.hupu.com/stats/players/pts\'
# 2. 发送网络请求
response = requests.get(url=url)
html_data = response.text
# print(html_data) # 通过数据对比确认了我想要的数据已经请求下来了
# 3.1 转换数据类型
selector = parsel.Selector(html_data)
trs = selector.xpath(\'//table[@class="players_table"]/tbody/tr\')[1:] # 二次提取
for tr in trs:
rank = tr.xpath(\'./td[1]/text()\').get() # 排名
player = tr.xpath(\'./td[2]/a/text()\').get() # 球员
team = tr.xpath(\'./td[3]/a/text()\').get() # 球队
score = tr.xpath(\'./td[4]/text()\').get() # 得分
hit_shot = tr.xpath(\'./td[5]/text()\').get() # 命中-出手
hit_rate = tr.xpath(\'./td[6]/text()\').get() # 命中率
hit_three = tr.xpath(\'./td[7]/text()\').get() # 命中-三分
three_rate = tr.xpath(\'./td[8]/text()\').get() # 三分命中率
hit_penalty = tr.xpath(\'./td[9]/text()\').get() # 命中-罚球
penalty_rate = tr.xpath(\'./td[10]/text()\').get() # 罚球命中率
session = tr.xpath(\'./td[11]/text()\').get() # 场次
playing_time = tr.xpath(\'./td[12]/text()\').get() # 上场时间
print(rank, player, team, score, hit_shot, hit_rate,
hit_three, three_rate, hit_penalty, penalty_rate,
session, playing_time, sep=\' | \')
# 4. 数据持久化
以上是关于Python爬虫常用的几种数据提取方式的主要内容,如果未能解决你的问题,请参考以下文章