Informer学习记录之Informer-Tensorflow版本
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Informer学习记录之Informer-Tensorflow版本相关的知识,希望对你有一定的参考价值。
历时两天,博主终于将informer-tensorflow调试成功了,下一步就可以进行数据集更换和改进了,下面介绍自己的调试过程:
项目介绍
Transformer模型
Transformer是由谷歌团队近期提出的一种新型网络模型,抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
大放异彩
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
具体关于transformer请阅读博主这篇博客:
Transformer学习记录
不足:
近年来的研究表明,相对RNN类型的模型来看,Transformer在长距离依赖的表达方面表现出了较高的潜力。然而,Transformer存在几个严重的问题,使其不能直接适用于LSTF问题,例如、高内存使用量和编码器-解码器体系结构固有的局限性。其中Transformer模型主要存在下面三个问题:
self-attention机制的二次计算复杂度问题:self-attention机制的点积操作使每层的时间复杂度和内存使用量为L2 。
高内存使用量问题:对长序列输入进行堆叠时,J个encoder-decoder层的堆栈使总内存使用量为 ,这限制了模型在接收长序列输入时的可伸缩性。
预测长期输出的效率问题:Transformer的动态解码过程,使得输出变为一个接一个的输出,后面的输出依赖前面一个时间步的预测结果,这样会导致推理非常慢。
Informer应运而生
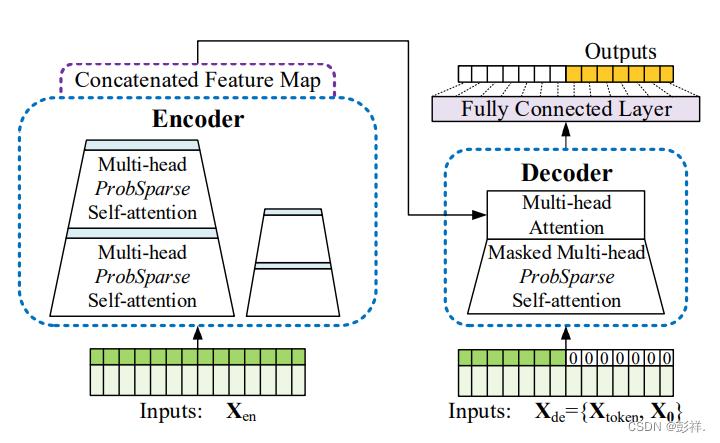
面对Transformer表现出的缺陷,各种改进方法层出不穷,而Informer也由此应运而生,其设计目标为:改进Transformer模型,使其计算、内存和体系结构更高效,同时保持更高的预测能力。
该模型具有三个显著特征:
ProbSpare self-attention机制,它可以在时间复杂度和内存使用方面达到 。
self-attention蒸馏机制,通过对每个attention层结果上套一个Conv1D,再加一个Maxpooling层,来对每层输出减半来突出主导注意,并有效地处理过长的输入序列。
并行生成式解码器机制,对长时间序列进行一次前向计算输出所有预测结果而不是逐步的方式进行预测,这大大提高了长序列预测的推理速度。
Informer是在2021年的AAAI 最佳论文奖项中一篇来自北京航空航天大学的论文中提出的,其能够解决长序列预测问题(LSTF),其为对Transformer的改进
最开始的版本是pytorch开发的,里面的内容很详细,很多方法是自定义的,由于博主技术有限,对这些自定义函数的解读让我感到头昏脑胀,且之前对pytorch没有太多应用,因此便使用了tensorflow版本。
环境要求
该项目是基于Tensorflow为后端来开发的,由于里面涉及自定义网络,所以对版本有要求,据说tensorflow1.6之前的keras是不支持自定义网络层的。
博主的项目环境为:
CUDA10.0 CuDNN7.4
tensorflow-gpu 1.14.0
keras 2.2.5
以上这些要求是有联系的,因为博主之前使用的是cuda8,其最高只能支持到tensorflow-gpu 1.0.0,因此博主便又安装了CUDA10.0,相应的,也就需要匹配的CuDNN等。
其余需要scikit-learn0.24.2,numpy1.16.0,pandas1.1.5
项目目录结构
代码解析
主函数读取参数
# 选择模型(去掉required参数,选择informer模型)
parser.add_argument('--model', type=str, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
# 数据选择(去掉required参数)
parser.add_argument('--data', type=str, default='WTH', help='data')
# 数据上级目录
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
# 数据名称
parser.add_argument('--data_path', type=str, default='WTH.csv', help='data file')
# 预测类型(多变量预测、单变量预测、多元预测单变量)
parser.add_argument('--features', type=str, default='M', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 数据中要预测的标签列
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
# 数据重采样(h:小时)
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型保存位置
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
# 输入序列长度
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
# 先验序列长度
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测序列长度
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
# 编码器default参数为特征列数
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
# 解码器default参数与编码器相同
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
parser.add_argument('--c_out', type=int, default=7, help='output size')
# 模型宽度
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制头数
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
# 模型中encoder层数
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
# 模型中decoder层数
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 网络架构循环次数
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
# 全连接层神经元个数
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 采样因子数
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
# 1D卷积核
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 是否需要序列长度衰减
parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True)
# 神经网络正则化操作
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
# attention计算方式
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
# 时间特征编码方式
parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')
# 激活函数
parser.add_argument('--activation', type=str, default='gelu',help='activation')
# 是否输出attention
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
# 是否需要预测
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data')
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
# 数据读取
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
# 多核训练(windows下选择0,否则容易报错)
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 训练轮数
parser.add_argument('--itr', type=int, default=2, help='experiments times')
# 训练迭代次数
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# mini-batch大小
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 早停策略
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test',help='exp description')
# loss计算方式
parser.add_argument('--loss', type=str, default='mse',help='loss function')
# 学习率衰减参数
parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')
# 是否使用GPU加速训练
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
# 取参数值
args = parser.parse_args()
# 获取GPU
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
调用模型开启实验
args = parser.parse_args()
data_parser =
'ETTh1': 'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1],
'ETTh2': 'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1],
'ETTm1': 'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1],
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
Exp = ExpInformer
for ii in range(args.itr):
setting = '__ft_sl_ll_pl_dm_nh_el_dl_df_at_eb__'.format(args.model, args.data, args.features, args.seq_len, args.label_len, args.pred_len, args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.embed, args.des, ii)
exp = Exp(args)
print('>>>>>>>start training : >>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
Exp模块开启训练与测试
Train方法
def train(self, setting):
train_data = self._get_data(flag='train')
valid_data = self._get_data(flag='val')
train_steps = len(train_data)
valid_steps = len(valid_data)
early_stopping = tf.keras.callbacks.EarlyStopping(patience=self.args.patience, restore_best_weights=True)
checkpoint_path = f'./checkpoints/setting'
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
model_optim = self._select_optimizer()
loss = tf.keras.losses.mse
self.model.compile(optimizer=model_optim, loss=loss, metrics=['mse', 'mae'])
self.model.fit(train_data.get_dataset(),
steps_per_epoch=train_steps,
validation_data=valid_data.get_dataset(),
validation_steps=valid_steps,
callbacks=[early_stopping],
epochs=self.args.train_epochs)
self.model.save_weights(checkpoint_path+'/model.h5')
return self.model
在Exp类调用时,进行初始化构造网络模型和数据集:
def _build_model(self):
model = Informer(
self.args.enc_in,
self.args.dec_in,
self.args.c_out,
self.args.seq_len,
self.args.label_len,
self.args.pred_len,
self.args.batch_size,
self.args.factor,
self.args.d_model,
self.args.n_heads,
self.args.e_layers,
self.args.d_layers,
self.args.d_ff,
self.args.dropout,
self.args.attn,
self.args.embed,
self.args.data[:-1],
self.args.activation
)
return model
获取数据集
def _get_data(self, flag):
args = self.args
if flag == 'test':
shuffle_flag = False
drop_last = True
batch_size = args.batch_size
else:
shuffle_flag = True
drop_last = True
batch_size = args.batch_size
dataset = DatasetETT(
root_path=args.root_path,
data_path=args.data_path,
flag=flag,
size=[args.seq_len, args.label_len, args.pred_len],
features=args.features,
shuffle=shuffle_flag,
drop_last=drop_last,
batch_size=batch_size,
is_minute=self.args.data == 'ETTm1'
)
print(flag, len(dataset))
return dataset
Test方法
def test(self, setting):
test_data = self._get_data(flag='test')
loss, mse, mae = self.model.evaluate_generator(test_data.get_dataset(), len(test_data))
print('mse:, mae:'.format(mse, mae))
数据预处理 data_loader.py
def __init__(self, root_path, flag='train', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, batch_size=32, shuffle=True, drop_last=True, is_minute=False):
# size [seq_len, label_len pred_len]
# info
if size == None:
self.seq_len = 24 * 4 * 4
self.label_len = 24 * 4
self.pred_len = 24 * 4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['train', 'test', 'val']
type_map = 'train': 0, 'val': 1, 'test': 2
self.set_type = type_map[flag]
self.features = features
self.target = target
self.scale = scale
self.batch_size 以上是关于Informer学习记录之Informer-Tensorflow版本的主要内容,如果未能解决你的问题,请参考以下文章
时间序列预测之为何舍弃LSTM而选择Informer?(Informer模型解读)
《k8s 源码分析》- Custom Controller 之 Informer