C开源项目-TinyHttp解读(中)
Posted 给个HK.phd读
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C开源项目-TinyHttp解读(中)相关的知识,希望对你有一定的参考价值。
解读(上)的总结
上篇解读主要讲解了server服务器端的几个流程,不要担心我们的simpleclient复杂程度,其远远比不上server,只要把server读懂那个就是piece of cake。
代码分析
- accept_request()函数分析
/**********************************************************************/
/* A request has caused a call to accept() on the server port to
* return. Process the request appropriately.
* Parameters: the socket connected to the client */
/**********************************************************************/
void accept_request(void *arg)
int client = (intptr_t)arg;
char buf[1024];
size_t numchars;
char method[255];
char url[255];
char path[512];
size_t i, j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI
* program */
char *query_string = NULL;
numchars = get_line(client, buf, sizeof(buf));
i = 0; j = 0;
while (!ISspace(buf[i]) && (i < sizeof(method) - 1))
method[i] = buf[i];
i++;
j=i;
method[i] = '\\0';
if (strcasecmp(method, "GET") && strcasecmp(method, "POST"))
unimplemented(client);
return;
if (strcasecmp(method, "POST") == 0)
cgi = 1;
i = 0;
while (ISspace(buf[j]) && (j < numchars))
j++;
while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < numchars))
url[i] = buf[j];
i++; j++;
url[i] = '\\0';
if (strcasecmp(method, "GET") == 0)
query_string = url;
while ((*query_string != '?') && (*query_string != '\\0'))
query_string++;
if (*query_string == '?')
cgi = 1;
*query_string = '\\0';
query_string++;
sprintf(path, "htdocs%s", url);
if (path[strlen(path) - 1] == '/')
strcat(path, "index.html");
if (stat(path, &st) == -1)
while ((numchars > 0) && strcmp("\\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
else
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
if ((st.st_mode & S_IXUSR) ||
(st.st_mode & S_IXGRP) ||
(st.st_mode & S_IXOTH) )
cgi = 1;
if (!cgi)
serve_file(client, path);
else
execute_cgi(client, path, method, query_string);
close(client);
我们已经看完了get_line函数,此函数就是对“取(一行)数据”的逻辑实现。简单地说就是遇“\\r,\\n,\\r\\n”就结束。
接下来的这个while循环好理解,其会提取非空格字符写入method变量中。method其实就是我们访问服务器的方法,这里提取完毕后实际上只对"GET && POST"两种方法进行处理,其余的就会用unimplemented告知未实现。
这个unimplemented函数并不困难,如下所示:
/**********************************************************************/
/* Inform the client that the requested web method has not been
* implemented.
* Parameter: the client socket */
/**********************************************************************/
void unimplemented(int client)
char buf[1024];
sprintf(buf, "HTTP/1.0 501 Method Not Implemented\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<HTML><HEAD><TITLE>Method Not Implemented\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</TITLE></HEAD>\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<BODY><P>HTTP request method not supported.\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</BODY></HTML>\\r\\n");
send(client, buf, strlen(buf), 0);
虽然有点长,主要都是向buf缓冲区写内容然后send给client,这里全部通过HTML语法来返回一串字符串还是挺走心的 (要我直接就error了) 。
返回到accept_request主函数,随后就是分别对“GET”和“POST”两种方法进行讨论。
首先我们先过滤掉方法后面的“空格”,然后将之后的信息写入到URL中。
从别人的博客那摘下一张图看看这两个访问方法的基本格式:


由上,应该知道了方法名之后跟上一个URL(统一资源定位符),就是我们要访问的网址罢了,最后应该还有一个遵循的协议。
其中有不难发现GET方法略有不同,其包含了参数,就是“?”后面的那一些。此时我们需要区分开来,所以while里面做的就是让query_string指向参数啦。
再之后我们开始处理路径的问题,由于我们把htdocs当作是服务器的文件夹,所以要将URL放于这个主文件夹之下。
同时,如果URL是一个目录,也就是最后一个字符是“/”的情况,我们默认让其指向主页,也就是“index.html”。
随后就开始讨论文件本身的问题,可能战线拉得有点长,就把有效代码拷下来:
if (stat(path, &st) == -1)
while ((numchars > 0) && strcmp("\\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
else
if ((st.st_mode & __S_IFMT) == __S_IFDIR)
strcat(path, "/index.html");
if ((st.st_mode & S_IXUSR) ||
(st.st_mode & S_IXGRP) ||
(st.st_mode & S_IXOTH) )
cgi = 1;
if (!cgi)
serve_file(client, path);
else
execute_cgi(client, path, method, query_string);
close(client);
这里的stat分别有代表函数和结构体,代表函数时其功能是获得文件属性并且写入缓冲区BUF中。如若返回-1,就表示文件路径不合法,索引不到这么一个文件,此时要干的事就是把socket套接字处的内容全部取完然后执行not_found函数。
这个函数也非常容易,返回给你一串HTML:
/**********************************************************************/
/* Give a client a 404 not found status message. */
/**********************************************************************/
void not_found(int client)
char buf[1024];
sprintf(buf, "HTTP/1.0 404 NOT FOUND\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<HTML><TITLE>Not Found</TITLE>\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "<BODY><P>The server could not fulfill\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "your request because the resource specified\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "is unavailable or nonexistent.\\r\\n");
send(client, buf, strlen(buf), 0);
sprintf(buf, "</BODY></HTML>\\r\\n");
send(client, buf, strlen(buf), 0);
恩,没错就是返回给你代码404,“网页不见啦”,裤子都脱了,你告诉我这个!!
我们要做的关键一步就是怎么处理那些有用的请求,合法的文件路径。
那些“S_”标志符确实看得头大,但也只能一步一步查!
第一种情况就是文件是一个目录,那么主动转到主页index.html上。
后面一种情况的三种标志符中IX其实代表了“Excute”,后面分别代表“GROUPE OWNER OTHERS”,就是代表了执行权限设置,此时也会采用cgi处理。
假如不用进行cgi处理的话,直接调用serve_file函数。
/**********************************************************************/
/* Send a regular file to the client. Use headers, and report
* errors to client if they occur.
* Parameters: a pointer to a file structure produced from the socket
* file descriptor
* the name of the file to serve */
/**********************************************************************/
void serve_file(int client, const char *filename)
FILE *resource = NULL;
int numchars = 1;
char buf[1024];
buf[0] = 'A'; buf[1] = '\\0';
while ((numchars > 0) && strcmp("\\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
resource = fopen(filename, "r");
if (resource == NULL)
not_found(client);
else
headers(client, filename);
cat(client, resource);
fclose(resource);
同样是先取完socket套接字处的所有内容。打开文件,如果不存在那么一个文件就执行not_found函数。(虽然在前面我们提及过stat函数用于判断文件路径是否合法,经测试,那个路径即使是目录也是会返回0合法的,所以此处当文件本身路径不合法时仍需经过相同的取完报头的步骤!)
测试截图:

好的,那么如果此文件也是合法的,可以打开的,我们就先发送报头再将文件内容添加进报文内容中。
报文头代码如下:
/**********************************************************************/
/* Return the informational HTTP headers about a file. */
/* Parameters: the socket to print the headers on
* the name of the file */
/**********************************************************************/
void headers(int client, const char *filename)
char buf[1024];
(void)filename; /* could use filename to determine file type */
strcpy(buf, "HTTP/1.0 200 OK\\r\\n");
send(client, buf, strlen(buf), 0);
strcpy(buf, SERVER_STRING);
send(client, buf, strlen(buf), 0);
sprintf(buf, "Content-Type: text/html\\r\\n");
send(client, buf, strlen(buf), 0);
strcpy(buf, "\\r\\n");
send(client, buf, strlen(buf), 0);
代码为200,意为成功!PERFECT!
发送报文内容的代码cat函数如下:
/**********************************************************************/
/* Put the entire contents of a file out on a socket. This function
* is named after the UNIX "cat" command, because it might have been
* easier just to do something like pipe, fork, and exec("cat").
* Parameters: the client socket descriptor
* FILE pointer for the file to cat */
/**********************************************************************/
void cat(int client, FILE *resource)
char buf[1024];
fgets(buf, sizeof(buf), resource);
while (!feof(resource))
send(client, buf, strlen(buf), 0);
fgets(buf, sizeof(buf), resource);
fgets函数就是从resource(文件内容获取buf大小的内容),只要还未取到文件结束符eof就一直取+发送。
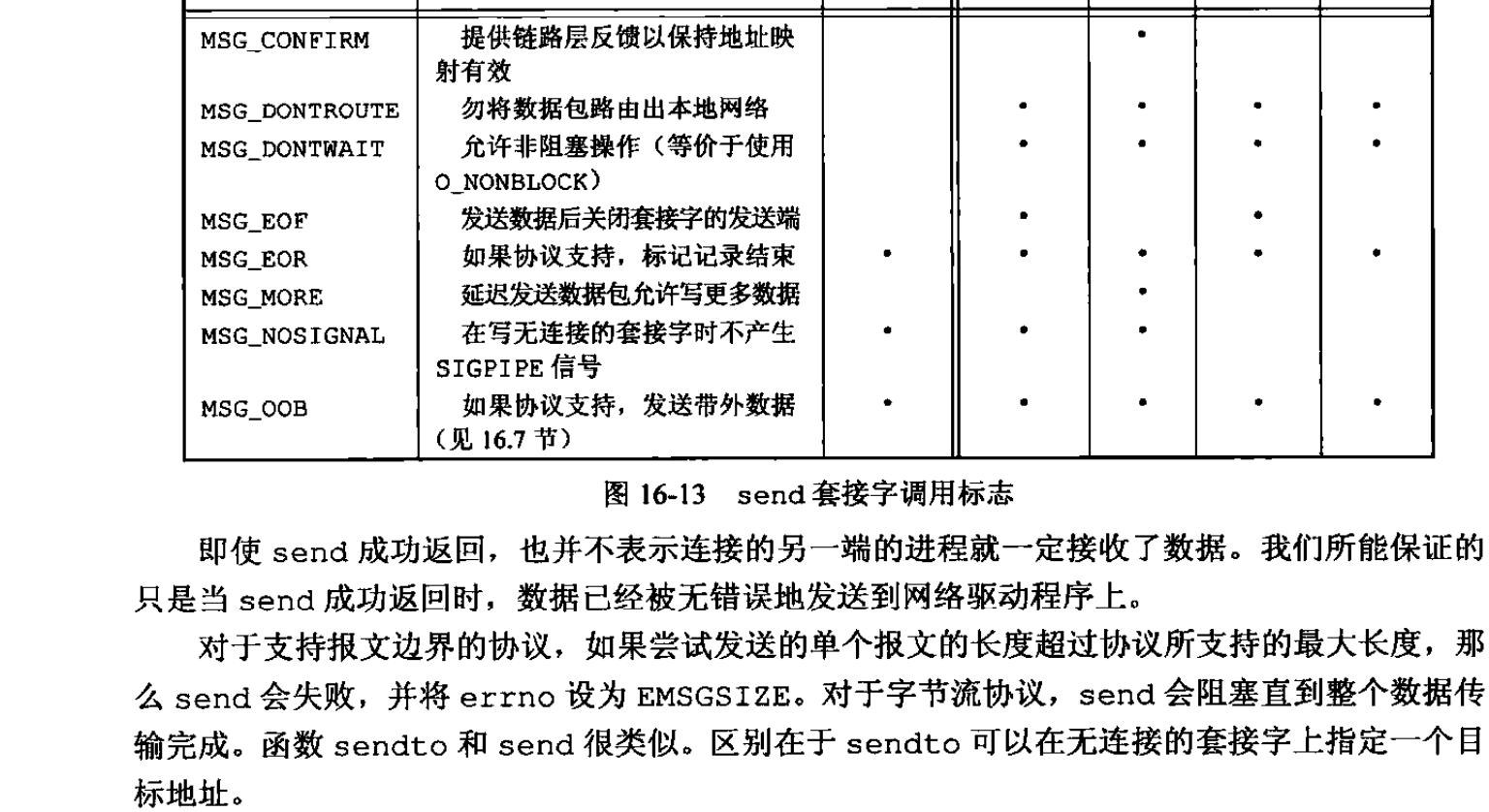
send函数也不是很难理解,第一个就是客户端套接字,第二个就是缓冲区地址,接着是发送字节数,最后是标志位,具体看下图所示:
C开源项目-TinyHttp解读(中)小结
代码不是特别困难,涉及到的UNIX环境高级编程确实非常生疏。按照思路来不是很难理解,但还有一些小细节考虑得不够到位,总体来说,自己从头开始写到这个程度的能力肯定还是没有的。需要沉淀慢慢练!
最后的CGI还不是很精通,希望把管道等知识复习一下再来写。
以上是关于C开源项目-TinyHttp解读(中)的主要内容,如果未能解决你的问题,请参考以下文章