推荐物品算法:欧几里得距离评价&皮尔逊相关度评价
Posted zhangqixiang5449
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐物品算法:欧几里得距离评价&皮尔逊相关度评价相关的知识,希望对你有一定的参考价值。
两种算法用来计算相似度评价,应用于例如网站的自动推荐。
欧几里得距离评价
将被评价的内容变为横纵坐标,称为“偏好空间”,将评价人置于坐标系中例如:
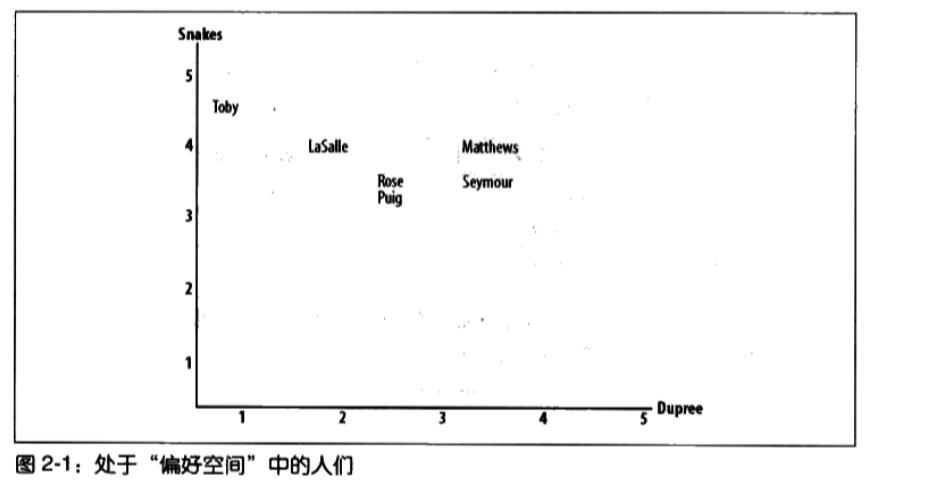
如图Toby对Snakes的评价为4.5,对Dupree的评价为1。
通过计算两个评价人在偏好空间中的距离平方和再开方即为两人的相似度,距离越短越相似。
为了得出数值便于理解,将计算所得距离+1取倒数,得到0-1范围内的相似值。+1的原因是防止距离为0,无法取倒数。相似值越高越相似。
代码(python):
critics =
'Lisa':'Lady':2.5,'Snak':3.5,'Just':3.0,'Superman':3.5,'Dupree':2.5,'Night':3.0,
'Gene':'Lady':3.0,'Snak':3.5,'Just':1.5,'Superman':5.0,'Dupree':3.5,'Night':3.0,
'Michael':'Lady':2.5,'Snak':3.0,'Superman':3.5,'Night':4.0,
'Claudia':'Snak':3.5,'Just':3.0,'Superman':4.0,'Dupree':2.5,'Night':4.5,
'Mick':'Lady':3.0,'Snak':4.0,'Just':2.0,'Superman':3.0,'Dupree':2.0,'Night':3.0,
'Jack':'Lady':3.0,'Snak':4.0,'Just':3.0,'Superman':5.0,'Dupree':3.5,'Night':3.0,
'Toby':'Snak':4.5,'Superman':4.0,'Dupree':1.0
from math import sqrt
def sim_distance(prefs,person1,person2):
si =
for item in prefs[person1]:
if item in prefs[person2]:
si[item] = 1
if len(si) == 0: return 0
sum_of_squares = sum([pow(prefs[person1][item]-prefs[person2][item],2)
for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares))
print (sim_distance(critics,'Lisa','Gene'))
print (sim_distance(critics,'Lisa','Toby'))
print (sim_distance(critics,'Lisa','Michael'))输出:
0.294298055086
0.348331477355
0.472135955
皮尔逊相关度评价
皮尔逊相关系数是判断两组数据与某一直线拟合程度的一种度量,在数据不是很规范时(例如某些用户夸大评价)会产出更好的结果。
延续上一个例子,将评价人置于XY轴,被评价的影片置于坐标系中

其公式为:

该算法返回一个介于-1到1之间的数值,值为1表明两人对每一样物品的评价均一致
代码(python)
from math import sqrt
def sim_pearson(prefs,p1,p2):
si =
for item in prefs[p1]:
if item in prefs[p2]: si[item] = 1
n = len(si)
if n == 0:return 1
sum1 = sum([prefs[p1][it] for it in si])
sum2 = sum([prefs[p2][it] for it in si])
sum1Sq = sum([pow(prefs[p1][it],2) for it in si])
sum2Sq = sum([pow(prefs[p2][it],2) for it in si])
pSum = sum([prefs[p1][it]*prefs[p2][it] for it in si])
num = pSum - (sum1*sum2/n)
den = sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq - pow(sum2,2)/n))
if den == 0: return 0
r = num/den
return r
print (sim_pearson(critics,'Lisa','Gene'))
输出
0.396059017191
推荐物品
基于上述两种算法,我们可以计算某用户与其他用户的相似度,然后按高低排序,推荐与其相似度较高的人所评价较高的物品。然而这样做有些不好,比如A用户与B用户相似度很高,但B用户喜欢一部“奇怪”的物品,对其打分很高,那么也会对A推荐该物品。这样做的推荐就有些不准了。
所以我们需要对评价值进行加权处理,相似对越高的人贡献的最终得分越多。
处理算法是:
例如:

总计/sim.sum一栏即为最后结果
def getRcommendations(prefs,person,similarity = sim_pearson):
totals =
simSums =
for other in prefs:
#排除自己
if other == person: continue
sim = similarity(prefs,person,other)
#排除相似度<0情况
if sim <= 0:continue
for item in prefs[other]:
#排除看过的
if item not in prefs[person] or prefs[person][item] == 0:
#相似度*评价 之和
totals.setdefault(item,0)
totals[item] += prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item] += sim
rankings = [(total/simSums[item],item) for item,total in totals.items()]
#排序并调转
rankings.sort()
rankings.reverse()
return rankings输出
print (getRcommendations(critics,'Toby'))
[(3.3477895267131013, 'Night'), (2.8325499182641614, 'Lady'), (2.6116637140516676, 'Just')]
基于物品的过滤
对于庞大的用户而言,上述算法的速度会很慢才能得出结果。基于物品的协作型过滤允许将大量的计算进行预先执行,使得用户获得结果的速度更快。
其思路是为每件物品预先计算和最为相近的物品,为某位用户推荐时,可查看其以评价的物品,寻找其相似的物品,经过加权,排序即可。
首先我们需要一个将物品和人的关系转置的函数:
def transformPrefs(prefs):
result =
for person in prefs:
for item in prefs[person]:
result.setdefault(item,)
result[item][person] = prefs[person][item]
return result运行:
print (transformPrefs(critics))
'Snak': 'Claudia': 3.5, 'Toby': 4.5, 'Michael': 3.0, 'Mick': 4.0, 'Jack': 4.0, 'Lisa': 3.5, 'Gene': 3.5,
'Just': 'Claudia': 3.0, 'Lisa': 3.0, 'Gene': 1.5, 'Mick': 2.0, 'Jack': 3.0,
'Dupree': 'Claudia': 2.5, 'Toby': 1.0, 'Mick': 2.0, 'Jack': 3.5,'Lisa': 2.5, 'Gene': 3.5,
'Night': 'Claudia': 4.5, 'Michael': 4.0, 'Mick': 3.0, 'Jack': 3.0, 'Lisa': 3.0, 'Gene': 3.0,
'Lady': 'Mick': 3.0, 'Gene': 3.0, 'Michael': 2.5, 'Jack': 3.0, 'Lisa': 2.5,
'Superman': 'Claudia': 4.0, 'Toby': 4.0, 'Michael': 3.5, 'Mick': 3.0, 'Jack': 5.0, 'Lisa': 3.5, 'Gene': 5.0
然后把物品当做人来进行计算相似度,即可得到相似的物品表。
在针对大数据集生成推荐列表时,基于物品的过滤方式速度要比基于用户(前述使用用户的相似度获得推荐物品的算法)的过滤更快。
以上是关于推荐物品算法:欧几里得距离评价&皮尔逊相关度评价的主要内容,如果未能解决你的问题,请参考以下文章