spark小案例——RDD,sparkSQL
Posted Z-hhhhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark小案例——RDD,sparkSQL相关的知识,希望对你有一定的参考价值。
分别使用RDD和SparkSQL两种方式解决相同的数据分析问题;
项目数据
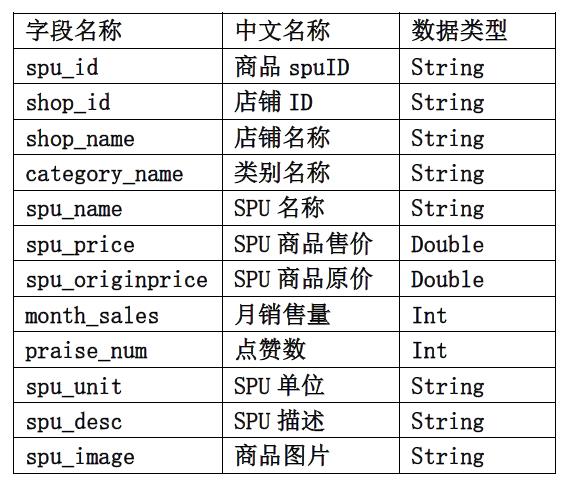
项目需求
使用RDD和SQL两种方式对数据清洗
- 清洗需求如下:
- 统计每个店铺分别有多少商品
- 统计每个店铺的总销售额
- 统计每个店铺销售额最高的前三商品,输出内容包括:店铺名,商品名和销售额其
- 中销售额为0的商品不进行统计计算,例如:如果某个店铺销售为 0则不进行统计 。
涉及到的pom依赖
<properties>
<scala.version>2.12.10</scala.version>
<spark.version>3.1.2</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>$scala.version</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>$scala.version</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>$scala.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>$spark.version</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
RDD方式
val session: SparkSession = SparkSession.builder().master("local[*]").appName("unname").getOrCreate()
val sc: SparkContext = session.sparkContext
//RDD方式
sc.textFile("hdfs://ip地址:9820/目录/meituan_waimai_meishi.csv")
.mapPartitionsWithIndex((ix,it)=>
//删除表头
if (ix == 0)it.drop(1)
it.map(line=>
//拆分数据,csv默认逗号拆分
val ps: Array[String] = line.split(",")
//获取有用的字段:店铺名,商品名,商品的总额
//提前计算商品总额,完成数据的转换
(ps(2),ps(4),ps(5).toFloat*ps(7).toInt)
)
)
//根据店铺名分组
.groupBy(_._1)
//mapValues对键值对每个value都应用一个函数,但是,key不会发生变化
.mapValues(itshop=>
//迭代器不支持排序
(
itshop.size,itshop.map(_._3).sum,
itshop.filter(_._3>0)
.toArray
.sortWith(_._3 > _._3)
.take(3)
.map(x=>
s"$x._2$x._3"
).mkString(";")
)
)
.foreach(println)
sc.stop()
session.close()
SparkSQL方式
val session: SparkSession = SparkSession.builder().master("local[*]").appName("unname").getOrCreate()
val sc: SparkContext = session.sparkContext
import session.implicits._ //隐式转换
/*
这里的session不是Scala中的包名,
而是创建的sparkSession对象的变量名称,
所以必须先创建SparkSession对象再导入。
这里的session对象不能使用var声明,因为Scala只支持val修饰的对象的引入
* */
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
val frame: DataFrame = session.read.format("CSV")
.option("inferSchema", true) //是否根据文件格式推断表结构
.option("delimiter", ",") //指定分隔符,默认为逗号
.option("nullValue", "NULL") //填充空值
.option("header", true) //是否存在表头
.load("hdfs://192.168.71.200:9820/test/data/meituan_waimai_meishi.csv")
.select($"shop_name", $"spu_name", ($"spu_price" * $"month_sales").as("month_total"))
.cache() //避免重复计算=persist(StorageLevel.MEMORY_AND_DISK_2)
val top3_shopname: DataFrame = frame
.filter($"month_total" > 0)
.select($"shop_name", $"spu_name", $"month_total",
dense_rank().over(Window.partitionBy($"shop_name")
.orderBy($"month_total".desc)).as("rnk")
).orderBy($"rnk".desc)
.filter($"rnk" < 3)
.groupBy($"shop_name".as("shop_name_top3"))
.agg(collect_list(concat_ws("_", $"spu_name", $"month_total")).as("top3"))
frame.groupBy($"shop_name")
.agg(count($"spu_name").as("cmm_count"),sum($"month_total").as("shop_total"))
.join(top3_shopname,$"shop_name_top3" === $"shop_name","inner")
.select($"shop_name",$"cmm_count",$"shop_total",$"top3")
.collect() //合并分区
.foreach(println)
// frame.collect().foreach(println)
// top3_shopname.foreach(x=>println(x.toString()))
sc.stop()
session.close()
以上是关于spark小案例——RDD,sparkSQL的主要内容,如果未能解决你的问题,请参考以下文章