HBase客户端
Posted 法海你懂不
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase客户端相关的知识,希望对你有一定的参考价值。
用户可以直接使用HBase客户端API,或者使用一些能够将请求转换成API调用的代理,这些代理将原生Java API包装成其他协议,这样客户端可以使用API提供的任意外部语言来编写程序。通常来说,外部API实现了专门基于Java的服务,而这种服务能够在内部使用HTable客户端提供的API。
客户端与网关之间的协议是由当前可用选择以及远程客户端的需求决定的。HBase提供了REST、Thrift、Avro的辅助服务。它们可以被实现成专门的网关服务,这些服务可以运行在专有的或共享的机器中,因为Thrift和Avro都有各自的RPC实现,所以网关服务仅仅是在它们的基础上进行了封装。至于REST,HBase则采用了自己的实现,并提供了访问数据数据的途径。
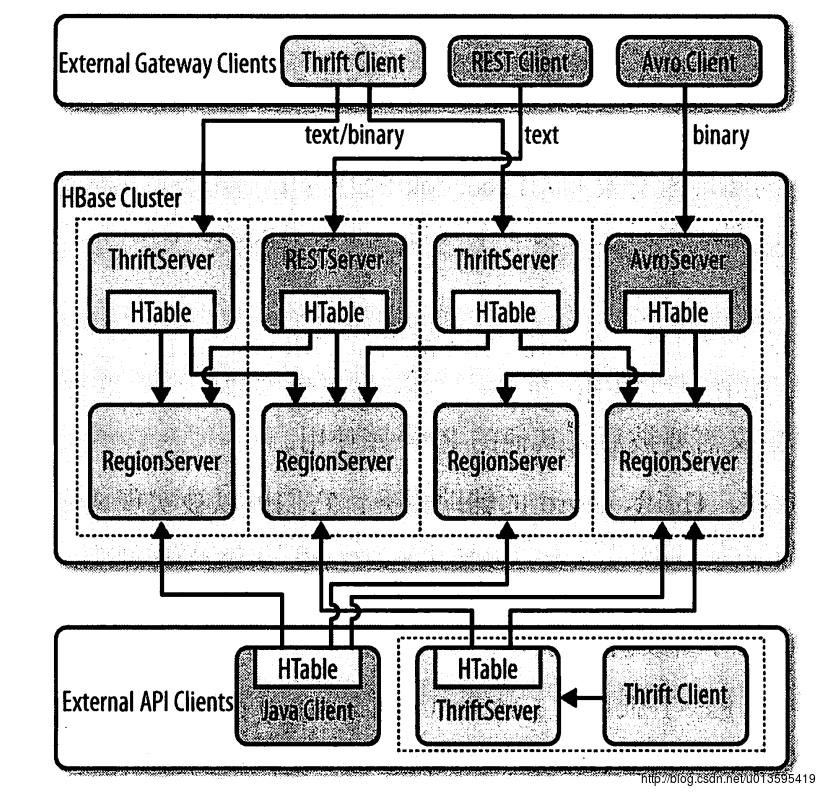
交互客户端
原生Java
REST
bin/hbase rest start
bin/hbase-daemon.sh start rest
curl http://<servername>:8080/version
bin/hbase-daemon.sh stop restREST的Java客户端
Thrift
Apache Thrift是由C++编写的框架,但是提供了跨语言的模式定义文件,包括Java、C++、Perl、php、Python和Ruby等。
bin/hbase thrift start
bin/hbase-daemon.sh start thrift
bin/hbase-daemon.sh stop thriftAvro
Apache Avro,类似于Thrfit,提供了针对多种编译语言的模式定义文件。因此一旦用户编译了预定义的模式文件,就可以在异构系统上跨语言通信。
bin/hbase avro start
bin/hbase-daemon.sh start avro
bin/hbase-daemon.sh stop avro其他客户端
- JRuby
- HBql
- HBase-DSL
- JPA/JPO
- PyHBase
- AsyncHBase
批处理客户端
MapReduce
原生 Java
Clojure
Hive
Hive提供了类似于SQL的处理语言,叫做HiveQL,允许用户查询存储在Hadoop中的半结构化数据。最终查询会转化成MapReduce作业,在本地执行或在分布式的MapReduce集群中执行。数据在作业执行的时候被解析,并且Hive提供了一个不仅可以访问HDFS的数据,还可以访问其他数据源的存储处理(storage handler)层。存储层的数据获取对用户查询来说是透明的。
Hive 0.6.0之后的版本提供了对HBase的支持,用户可以直接定义将Hive表存储为HBase表,并按照映射列值,在需要的时候行健可以作为独立的一列。
Pig
Apache Pig项目提供了一个分析海量数据的平台,它提供了自己的查询语言,叫做Pig Latin。Pig语法使用了命令式编程风格,迭代执行,并最终将输入转化为输出。Pig语言的编程风格与Hive模拟SQL的实现方式的风格截然相反。
Pig支持HBase表的读写,用户可以映射HBase表中的列到Pig元祖(tuple),并且可以选择行健作为第一列读取。写入的时候,第一个字段通常当作行健写入。存储层也支持基本的过滤,它在行级别上工作并且提供了比较操作。
Cascading
Cascading是MapReduce的替代API,实际上它使用MapReduce执行作业,但用户在开发时不必以MapReduce的模式来考虑它的运行。
Shell
HBase Shell是HBase集群的命令行接口,用户可以使用Shell访问本地或远程服务器并与其进行交互,Shell同时提供了客户端和管理功能的操作。
bin/habse shell基于Web的UI
HBase的Web默认端口是60010,region服务器的Web默认端口是60030。
以上是关于HBase客户端的主要内容,如果未能解决你的问题,请参考以下文章