线性回归
Posted 大数据最好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线性回归相关的知识,希望对你有一定的参考价值。
1.线性回归模型
"回归"的由来
Francis Galton,英国生物学家,他研究了父母身高与子女身高之间关系后得出,若父母身高高于平均大众身高,则其子女身高倾向于倒退生长,即会比其父母身高矮一些而更接近于大众平均身高。若父母身高小于平均身高,则其子女身高倾向于向上生长,以更接近于大众平均身高。此现象,被Galton称之为回归现象,即regression.
什么是线性回归?
这里我讲几点:
1)统计回归分析的任务,就在于根据X和Y的观察值,去估计函数f,寻求变量之间近似的函数关系。
2)我们常用的是,假定f函数的数学形式已知,其中若干个参数未知,要通过自变量和因变量的观察值去估计未知的参数值。这叫“参数回归”。其中应用最广泛的是f为线性函数的假设:
这种情况叫做“线性回归”。这个线性模型就是我们今后主要讨论的对象。
3)
自变量只有一个时,叫做一元线性回归。f = b0+b1x
自变量有多个时,叫做多元线性回归。
4)分类(Classification)与回归(Regression)都属于监督学习,他们的区别在于:
分类:用于预测有限的离散值,如是否得了癌症(0,1),或手写数字的判断,是0,1,2,3,4,5,6,7,8还是9等。分类中,预测的可能的结果是有限的,且提前给定的。
回归:用于预测实数值,如给定了房子的面积,地段,和房间数,预测房子的价格。
线性回归模型假设输入特征和对应的结果满足线性关系。在上述的数据集中加上一维--房间数量,于是数据集变为:
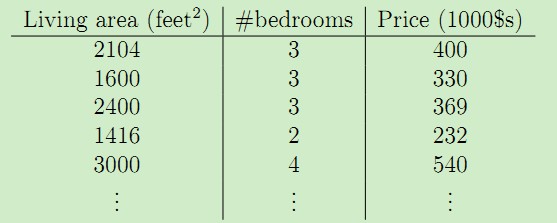
于是,输入特征x是二维的矢量,比如x1(i)表示数据集中第i个房子的面积,x2(i)表示数据集中第i个房子的房间数量。于是可以假设输入特征x与房价y满足线性函数,比如:
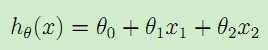
这里θi称为假设模型即映射输入特征x与结果y的线性函数h的参数parameters,为了简化表示,我们在输入特征中加入x0 = 1,于是得到:
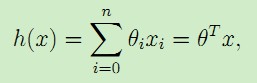
参数θ和输入特征x都为矢量,n是输入的特征x的个数(不包含x0)。
现在,给定一个训练集,我们应该怎么学习参数θ,从而达到比较好的拟合效果呢?一个直观的想法是使得预测值h(x)尽可能接近y,为了达到这个目的,我们对于每一个参数θ,定义一个代价函数cost function用来描述h(x(i))'与对应的y(i)'的接近程度:
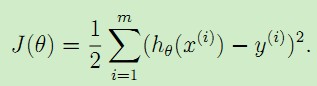
前面乘上的1/2是为了求导的时候,使常数系数消失。于是我们的目标就变为了调整θ使得代价函数J(θ)取得最小值,方法有梯度下降法,最小二乘法等。
2.1 梯度下降法
现在我们要调整θ使得J(θ)取得最小值,为了达到这个目的,我们可以对θ取一个随机初始值(随机初始化的目的是使对称失效),然后不断地迭代改变θ的值来使J(θ)减小,知道最终收敛取得一个θ值使得J(θ)最小。梯度下降法就采用这样的思想:对θ设定一个随机初值θ0,然后迭代进行以下更新
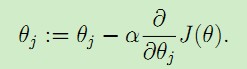
直到收敛。这里的α称为学习率learning rate。
梯度方向由J(θ)对θ 的偏导数决定,由于要求的是最小值,因此对偏导数取负值得到梯度方向。将J(θ)代入得到总的更新公式
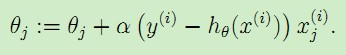
这样的更新规则称为LMS update rule(least mean squares),也称为Widrow-Hoff learning rule。
对于如下更新参数的算法:
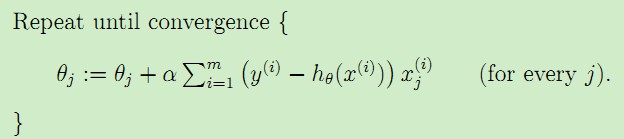
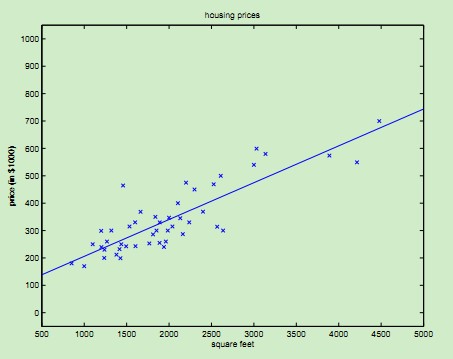
由于在每一次迭代都考察训练集的所有样本,而称为批量梯度下降batch gradient descent。对于引言中的房价数据集,运行这种算法,可以得到θ0 = 71.27, θ1 = 1.1345,拟合曲线如下图:
如果参数更新计算算法如下:
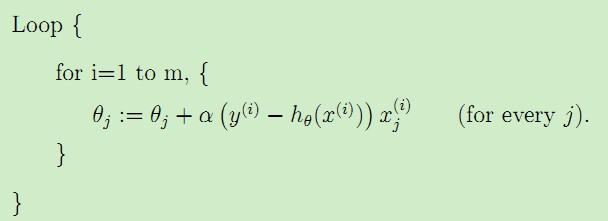
这里我们按照单个训练样本更新θ的值,称为随机梯度下降stochastic gradient descent。比较这两种梯度下降算法,由于batch gradient descent在每一步都考虑全部数据集,因而复杂度比较高,随机梯度下降会比较快地收敛,而且在实际情况中两种梯度下降得到的最优解J(θ)一般会接近真实的最小值。所以对于较大的数据集,一般采用效率较高的随机梯度下降法。
2.2 最小二乘法(LMS)
梯度下降算法给出了一种计算θ的方法,但是需要迭代的过程,比较费时而且不太直观。下面介绍的最小二乘法是一种直观的直接利用矩阵运算可以得到θ值的算法。为了理解最小二乘法,首先回顾一下矩阵的有关运算:
假设函数f是将m*n维矩阵映射为一个实数的运算,即 ,并且定义对于矩阵A,映射f(A)对A的梯度为:
,并且定义对于矩阵A,映射f(A)对A的梯度为:
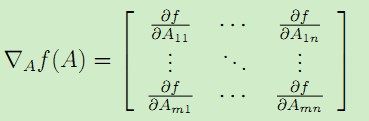
因此该梯度为m*n的矩阵。例如对于矩阵A= ,而且映射函数f(A)定义为:F(A) = 1.5A11 + 5A122+ A21A22,于是梯度为:
,而且映射函数f(A)定义为:F(A) = 1.5A11 + 5A122+ A21A22,于是梯度为:
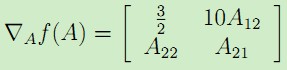 。
。
另外,对于矩阵的迹的梯度运算,有如下规则:
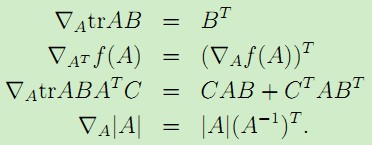 。
。
下面,我们将测试集中的输入特征x和对应的结果y表示成矩阵或者向量的形式,有:
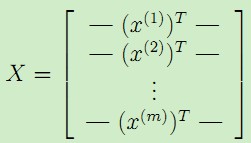 ,
,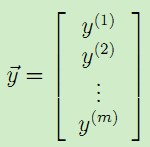 ,
,
对于预测模型有,即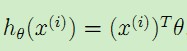 ,于是可以很容易得到:
,于是可以很容易得到:
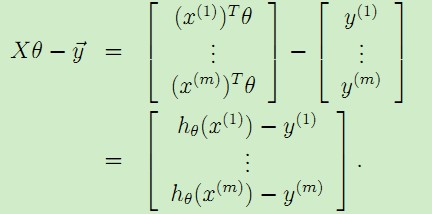 ,
,
所以可以得到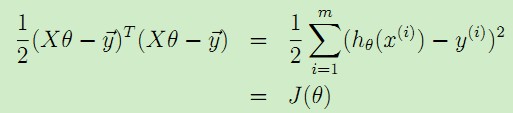 。
。
于是,我们就将代价函数J(θ)表示为了矩阵的形式,就可以用上述提到的矩阵运算来得到梯度:
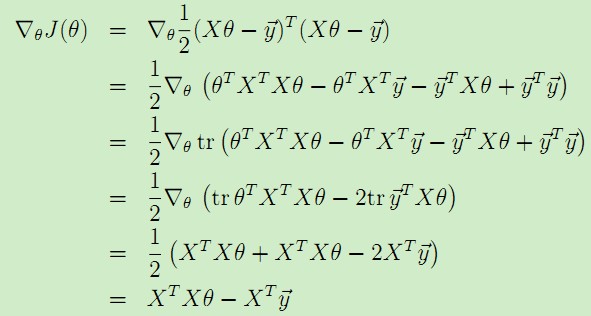 ,
,
令上述梯度为0,得到等式: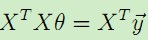 ,于是得到θ的值:
,于是得到θ的值:
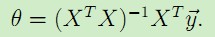 。这就是最小二乘法得到的假设模型中参数的值。
。这就是最小二乘法得到的假设模型中参数的值。
2.3 加权线性回归
首先考虑下图中的几种曲线拟合情况:
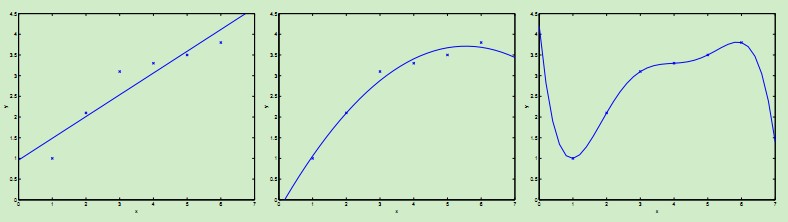
最左边的图使用线性拟合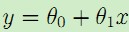 ,但是可以看到数据点并不完全在一条直线上,因而拟合的效果并不好。如果我们加入x2项,得到
,但是可以看到数据点并不完全在一条直线上,因而拟合的效果并不好。如果我们加入x2项,得到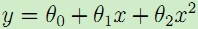 ,如中间图所示,该二次曲线可以更好的拟合数据点。我们继续加入更高次项,可以得到最右边图所示的拟合曲线,可以完美地拟合数据点,最右边的图中曲线为5阶多项式,可是我们都很清醒地知道这个曲线过于完美了,对于新来的数据可能预测效果并不会那么好。对于最左边的曲线,我们称之为欠拟合--过小的特征集合使得模型过于简单不能很好地表达数据的结构,最右边的曲线我们称之为过拟合--过大的特征集合使得模型过于复杂。
,如中间图所示,该二次曲线可以更好的拟合数据点。我们继续加入更高次项,可以得到最右边图所示的拟合曲线,可以完美地拟合数据点,最右边的图中曲线为5阶多项式,可是我们都很清醒地知道这个曲线过于完美了,对于新来的数据可能预测效果并不会那么好。对于最左边的曲线,我们称之为欠拟合--过小的特征集合使得模型过于简单不能很好地表达数据的结构,最右边的曲线我们称之为过拟合--过大的特征集合使得模型过于复杂。
正如上述例子表明,在学习过程中,特征的选择对于最终学习到的模型的性能有很大影响,于是选择用哪个特征,每个特征的重要性如何就产生了加权的线性回归。在传统的线性回归中,学习过程如下:
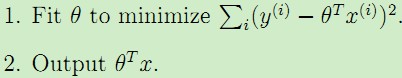 ,
,
而加权线性回归学习过程如下:
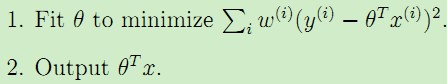 。
。
二者的区别就在于对不同的输入特征赋予了不同的非负值权重,权重越大,对于代价函数的影响越大。一般选取的权重计算公式为:
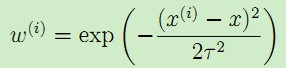 ,
,
其中,x是要预测的特征,表示离x越近的样本权重越大,越远的影响越小。
以上是关于线性回归的主要内容,如果未能解决你的问题,请参考以下文章