推荐系统阿里深度兴趣网络:DIN模型(Deep Interest Network)
Posted 天泽28
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统阿里深度兴趣网络:DIN模型(Deep Interest Network)相关的知识,希望对你有一定的参考价值。
推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
写在前面:
建议大家看DIN论文的时候看arxiv上的V1版本,传送门链接:DIN v1版本,不要看发表在KDD’18上的正式论文,个人认为正式版本的论文包装的太过厉害,尤其模型部分的图,看完之后完全不理解模型细节。而arxiv上的v1版本则朴实无华,非常容易理解,模型细节呈现的比较清晰。强烈建议看v1版本。
DIN(Deep Interest Network)模型是阿里妈妈盖坤团队发表在KDD’18上的文章,因为有阿里的光环,因此,这个模型在业界还是比较有名气的,至于最终在其他公司场景下有没有效果,取决于对比的baseline,如果你的baseline足够弱,理论上会有一定效果的提升,当然,如果你的baseline够强,可能一点效果都没有。之前博客介绍的模型都在解决如何有效的学到高阶交叉特征,而DIN的核心思想是把attention机制引入了到用户兴趣建模上。
工业界当前广告/推荐的模型基本都是遵循Embedding&MLP(embedding+mlp)的范式,在embedding阶段,所有的离散特征都要被映射成一个固定长度的低维稠密向量。离散特征一般有单值特征和多值特征,分别要做one-hot编码和multi-hot编码,单值特征没什么问题,直接映射成embedding向量即可,而对于多值特征,比如:用户点击过的item序列,用户点击过item类目的序列,通常的操作都是每个item映射成一个embedding向量,然后做一个sum/average pooling,最终得到一个embedding向量。当然,有条件的厂可能还会对这个序列使用一个LSTM,效果嘛,看天吃饭,反正也是有的没的。下图展示了单值特征和多值特征做embedding向量时的区别。
接下来,重点来了,我们在对多值特征做pooling的时候,只是简单的做sum或者average,这相当于认为序列中的每个item的重要性是一样的,所以最好的方式是给每个item一个权重,问题是权重怎么给?依据什么给?DIN这篇paper则非常朴素的认为,因为你的task是CTR预估,那么显然每个item的权重应该由目标广告(商品)与该item之间的相关性决定。
用论文中的一个例子来说明,假设某个用户在最近XX内点击(收藏、或者其他行为)序列为:泳衣、泳帽、薯片、坚果、书籍。候选广告是:护目镜。那么,显然在用户的点击行为序列中,决定这个用户是否点击推荐的护目镜是泳衣和泳帽,因为这两个item与目标候选广告之间相关性更强,因此所做的贡献也就更大。所以,DIN做的就是把传统多值特征做pooling的方式加了个权重,而这个权重是由item个候选广告之间的相关性决定的。
这里我们延伸一下,思考一下,有过工业界广告/推荐经验的同学应该很清楚,在Embedding&MLP的范式架构下,依然需要大量的人工特征工程,其中包含了大量的交叉特征。我个人酷爱的一类交叉特征是:目标与行为的交集及数量。比如上面那个例子,用户历史行为为:泳衣、泳帽、薯片、坚果、书籍,候选广告为护目镜。泳衣、泳帽与护目镜的类目都是相同的,因此我们可以用:护目镜类目与上述用户点击过item的类目做交集及数量,得到的结果为:泳衣类#2,2为交集集合长度(泳帽、泳衣、护目镜都属于泳衣类)。因此,如果有了这个交叉特征,理论上普通的Embedding&MLP效果应该不比DIN差多少,所以,如果你打算尝试DIN,不妨先试试上面我说的方法。
相比较上面我说的方式,DIN里的做法更加soft,更加丝滑。这里不得不感叹,这种小细节,经过比较好的包装,外加一些其他方面的创新,就能够产生一篇高质量的论文,因此,阿里妈妈每年能产出这么多paper也不是没有原因的。
说了这么多,我们来具体剖析下DIN这篇论文,接下来将会从以下几个方面来介绍DIN:
- DIN模型整体的网络结构
- DIN网络核心模块Activation unit
- 自适应的正则技术:Adaptive Regularization Technique
- 激活函数Dice(Data Adaptive Activation Function)
- 评估方式GAUC
一、DIN模型整体的网络结构
直接上图,来看看DIN的网络结构(图片来自arxiv上DIN v1版论文,KDD的正式版包装的都不认识了,必须吐槽下~)
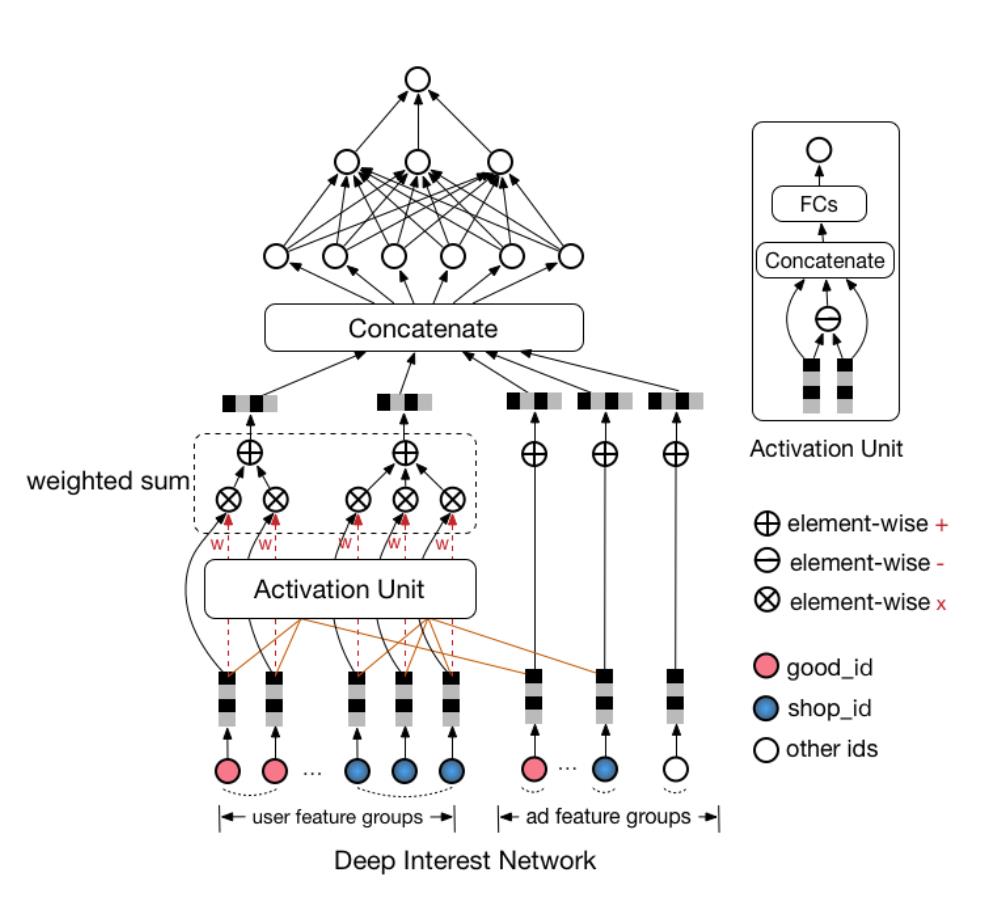
DIN网络结构整体上来看是在embedding层与MLP(全连接层)之间加入了activation unit。从上图,我们能够看出,用户历史点击过的商品id(good id)只与候选广告的商品id算相关性(上图中是element-wise减,当然你也可以算内积等,甚至可以都算),用户历史点击过的商铺id只与候选广告的商铺id算相关性。
二、DIN网络核心模块Activation unit
这个模块是整个DIN网络的核心模块,也是该模型的创新之处,如下图所示。

上图比较清晰的展示了activation unit模块是如何工作的,以用户历史行为的商品id序列与候选广告id举例子。
假设用户历史行为:
- 商品id序列为 u g = [ u g 1 , u g 2 , . . . , u g n ] ug = [ug_1,ug_2,...,ug_n] ug=[ug1,ug2,...,ugn],经过embedding层后对应的向量为 u g e = [ u g e 1 , u g e 2 , . . . , u g e n ] uge = [uge_1,uge_2,...,uge_n] uge=[uge1,uge2,...,ugen]。
- 商铺id序列为 u s = [ u s 1 , u s 2 , . . . , u s n ] us = [us_1,us_2,...,us_n] us=[us1,us2,...,usn],经过embedding层后对应的向量为 u s e = [ u s e 1 , u s e 2 , . . . , u s e n ] use = [use_1,use_2,...,use_n] use=[use1,use2,...,usen]。
候选广告:
- 商品id为 a g ag ag,经过embedding层后对应的向量为 a g e age age。
- 商品id为 a s as as,经过embedding层后对应的向量为 a s e ase ase。
则activation unit的做法为:
- 把用户历史行为的商品向量与候选广告商品向量做 ⊝ \\circleddash ⊝(向量对应元素相减),即 a u g = [ a g e ⊝ u g e 1 , a g e ⊝ u g e 2 , . . . , a g e ⊝ u g e n ] aug = [age\\circleddash uge_1, age\\circleddash uge_2,..., age\\circleddash uge_n] aug=[age⊝uge1,age⊝uge2,...,age⊝ugen]
- 把用户历史行为的商铺向量与候选广告商铺向量做 ⊝ \\circleddash ⊝,即 a u s = [ a s e ⊝ u s e 1 , a s e ⊝ u s e 2 , . . . , a s e ⊝ u s e n ] aus = [ase\\circleddash use_1, ase\\circleddash use_2,..., ase\\circleddash use_n] aus=[ase⊝use1,ase⊝use2,...,ase⊝usen]
- 把1,2步中得到的结果向量 a u g , a u s aug, aus aug,aus与用户商品向量 u g e uge uge,用户商铺向量 u s e use use,候选广告商品向量 a g ag ag,候选广告商铺向量 a s as as,做拼接concatenate,输入一个全连接网络。
用论文中形式化的公式表达为(虽然个人认为有了上面的例子,公式没必要了,但还是贴出来吧):
V
u
=
f
(
V
a
)
=
∑
i
=
1
N
w
i
∗
V
i
=
∑
i
=
1
N
g
(
V
i
,
V
a
)
∗
V
i
(1)
V_u = f(V_a) = \\sum_i=1^Nw_i*V_i = \\sum_i=1^Ng(V_i,V_a)*V_i \\tag1
Vu=f(Va)=i=1∑Nwi∗Vi=i=1∑Ng(Vi,Va)∗Vi(1)
其中,
V
u
V_u
Vu表示用户
u
u
u的向量,
V
a
V_a
Va表示广告
a
a
a的向量,
V
i
V_i
Vi表示行为
i
i
i的向量(比如商品id,商铺id),
w
i
w_i
wi表示行为
i
i
i的attention得分。
论文中给出的是同类id做向量减
⊝
\\circleddash
⊝,当然你可以做内积,甚至都要。DIN作者给出的实现中就使用了内积,参见:https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/model_dice.py#L241
另外一点是,论文中明确说了他们没有把权重做归一化,论文原文为:
That is, normalization with softmax on the output of a(·) is abandoned. Instead, value of ∑ i w i \\sum_iw_i ∑iwi is treated as an approximation of the intensity of activated user interests to some degree.
但在实现的时候,却用了softmax做归一化,参见:https://github.com/zhougr1993/DeepInterestNetwork/blob/master/din/model_dice.py#L221
我们来看下具体的实现(paddle):
"""
hist_item_seq: 用户点击过的商品序列,Tensor(shape=[32, 2],
2-->由该batch内用户点击过的商品序列最大长度决定,比如20。
不够的用0(不在id集合内的任意数字都可以)补全
hist_cat_seq: Tensor(shape=[32, 2], 用户点击过的商品类目序列,同hist_item_seq
target_item: Tensor(shape=[32],推荐广告商品
target_cat: Tensor(shape=[32],推荐广告商品类目
label: Tensor(shape=[32, 1],点击标记
mask: Tensor(shape=[32, 2, 1],mask矩阵,用于hist_item_seq和hist_cat_seq中补 0的部分失效,对于补齐的网格部分,初始化为-INF,从而在sigmoid后,使之失效为0; 目前做法是有数据的为0,补齐的用-INF
target_item_seq: Tensor(shape=[32, 2],因为候选打分广告item要与用户点击过的每个item做减法(或内积,或加法),因此,需要把target_item扩展成与hist_item_seq维度一样,即把target_item重复len(hist_item_seq)次
target_cat_seq: Tensor(shape=[32, 2],同target_item_seq
"""
# Tensor(shape=[32, 2, 128])
hist_seq_concat = paddle.concat([hist_item_emb, hist_cat_emb], axis=2)
# Tensor(shape=[32, 2, 128])
target_seq_concat = paddle.concat(
[target_item_seq_emb, target_cat_seq_emb], axis=2)
# Tensor(shape=[32, 128]
target_concat = paddle.concat(
[target_item_emb, target_cat_emb], axis=1)
# shape=[32, 2, 512]
# 1. 这里不光做element-wise减,还做内积
concat = paddle.concat(
[
hist_seq_concat, target_seq_concat, # shape=[32, 2, 128], shape=[32, 2, 128]
hist_seq_concat - target_seq_concat, # shape=[32, 2, 128]
hist_seq_concat * target_seq_concat # shape=[32, 2, 128]
],
axis=2)
# 2. 输入一个全连接网络
# [Linear(in_features=512, out_features=80, dtype=float32), Sigmoid(),
# Linear(in_features=80, out_features=40, dtype=float32), Sigmoid(),
# Linear(in_features=40, out_features=1, dtype=float32)]
for attlayer in self.attention_layer:
concat以上是关于推荐系统阿里深度兴趣网络:DIN模型(Deep Interest Network)的主要内容,如果未能解决你的问题,请参考以下文章