论文笔记Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Posted 糖梦梦是女侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks相关的知识,希望对你有一定的参考价值。
写在前面:
我看的paper大多为Computer Vision、Deep Learning相关的paper,现在基本也处于入门阶段,一些理解可能不太正确。说到底,小女子才疏学浅,如果有错误及理解不透彻的地方,欢迎各位大神批评指正!
E-mail:merrytangmengyun@gmail.com。
————————————————————————————————————————————————
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》收录于Neural Information Processing Systems (NIPS), 2015( Meachine Learning领域的顶会)。R-CNN和Fast R-CNN引领了近两年目标检测的潮流,Fast R-CNN对R-CNN进行了加速,而这篇Faster R-CNN则进一步对Fast R-CNN进行了加速,使得这种基于CNN的目标检测方法在real-time上看到了希望,使之运用到工程上成为了可能。
在作者的主页上提供了论文下载链接、Python代码、MATLAB代码以及相关文档,这样一丝不苟的科研精神令人敬佩。这篇paper实验部分相当充分,实验结果强有力地证明了文中方法的有效性,非常不错,值得学习。
作者主页:http://people.eecs.berkeley.edu/~rbg/
相关参考文献如下:
【1】R-CNN: Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C], CVPR, 2014.
【2】SPPNET: He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C], ECCV, 2014.
【3】Fast-RCNN: Girshick R. Fast R-CNN[C]. ICCV, 2015.
《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
论文架构:
Abstract
1.Introduction
2.Related Work
3.Faster R-CNN
3.1 Region Proposal Networks
3.1.1 Anchors
3.1.2 Loss Function
3.1.3 Training RPNs
3.2 Sharing Feature for RPN and Fast R-CNN
3.3 Implementation Details
4.Experiments
4.1 Experiments on PASCAL VOC
4.2 Experiments on MS COCO
4.3 From MS COCO toPASCAL VOC
5.Conclusion
1.内容概述
目前的目标检测网络依靠region proposal算法来假设目标的位置,诸如SPPnet和Fast R-CNN所取得的进步已经减少了这些检测网络的运行时间,但也揭露了region proposal的计算是一个瓶颈。
作者发现用于基于region的detector(如Fast R-CNN)的卷积feature map也可以用于生成region proposals。于是在这些卷积特征的顶部,通过添加一些额外的卷积层来构建一个Region Proposal Network(RPN)(与检测网络共享整幅图像的卷积特征,由此使得可以进行几乎无代价的region proposal),对每一位置同时输出region bounds以及objectness score。因此RPN是一个全卷积网路(full convolutional network,FCN),可以进行端到端训练,生成高质量的region proposals,然后送入Fast R-CNN进行检测。
RPNs可以预测尺度和长宽比变化很大的regionproposal。相对于使用图像金字塔(图1(a))和filters金字塔(图1(b))的方法,文中提出一种新颖的“anchor” boxes来作为多尺度和多长宽比的参照。可将其视为一个回归参照(regression reference)金字塔(图1(c)),从而避免枚举多尺度和多长宽比的图片或者filters。
文中的方法通过共享卷积特征进一步将RPN和Fast R-CNN整合成一个网络,并提出了一种训练机制:在保持proposal固定的情况下,交替微调region proposal和object detection。文中的方法使用了deep VGG-16模型,并且该检测系统在GPU上获得了每秒5张图像的速度,在PASCAL VOC 2007、2012以及MS COCO数据集中获得了最佳的目标检测准确率。

图1.处理多尺度的不同机制。(a)建立图像和feature map的金字塔,classifier在所有尺度上工作。(b)在feature map上建立多尺度/大小的filters金字塔。(c)文中在回归函数上reference boxes金字塔。
2.方法
文中的对象检测系统,称之为Faster RCNN,主要由两个模块组成:第一层是深度全卷积网络来提取区域,第二层为Fast R-CNN检测器。整个系统是一个对象检测的独立、统一的网络,如图2所示。
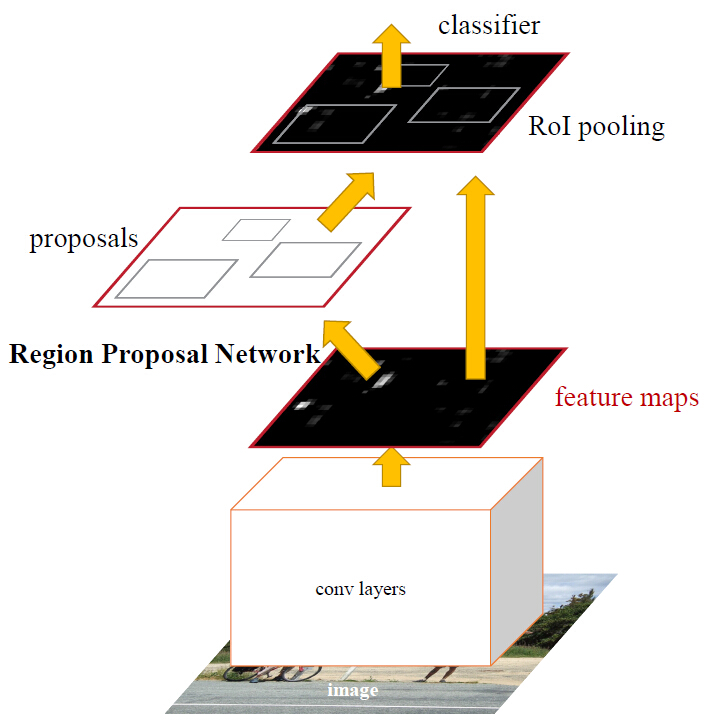
图2.Faster R-CNN是一个对象检测的独立、统一的网络。RPN模块作为这个统一的“attention”。
(1)Region Proposal Networks
RPN以一张任意大小的图片作为输入,输出一组矩形object proposals,每一个带有一个objectness score。文中使用全连接网络(full convelutional network)对这一过程进行建模,由于最终目的是与一个Fast R-CNN对象检测网络共享计算,假定两个网络共享一组卷积网络。本文中使用了Zeiler and Fergus(ZF)模型(带5层可共享的卷积层)和Simonyan and Zisserman (VGG-16)模型(带13层可共享的卷积层)。
文中通过在最后一层共享卷积层输出的卷积feature map上滑动一个小网络(窗口)来生成region proposals。这个小网络将输入卷积feature map的n*n spacial window作为输入。每个滑窗映射到低维特征(ZF为256维,VGG为512维,后面跟着ReLU)。这个特征被送入到两个兄弟全连接层——box-regreesion层(reg)和一个box-classification层(cls)。在这篇文章中n=3,注意输入图片的有效接受域(ZF为171个像素点,VGG为228个像素点)。这个迷你网络如图3左所示。由于迷你网络是以滑窗的方式来进行的,全连接层是通过所有空间位置来共享的。这个架构通过n*n卷积层后面跟着两个1*1卷积层(分别为reg和cls)实现的。
A. Anchor
对于每个滑窗位置,同时预测多个region proposal,每个位置最大可能的proposal数目定义为k。因此,reg层有4k个输出来编码k个box的坐标,cls层会输出2k个score来估计每个proposal是对象或者不是对象的可能性。我们对k个proposal进行参数化,相对应于k个参照box,我们称之为anchor。每个anchor集中于滑窗中心,关联一个尺度(scale)和一个长宽比(aspect ratio)(图3左)。我们默认使用3中scale和3个 aspect ratio,因此对于每个滑窗位置,产生k=9个anchor对于一个大小为W*H的卷积feature map,总共会产生WHk个anchor。
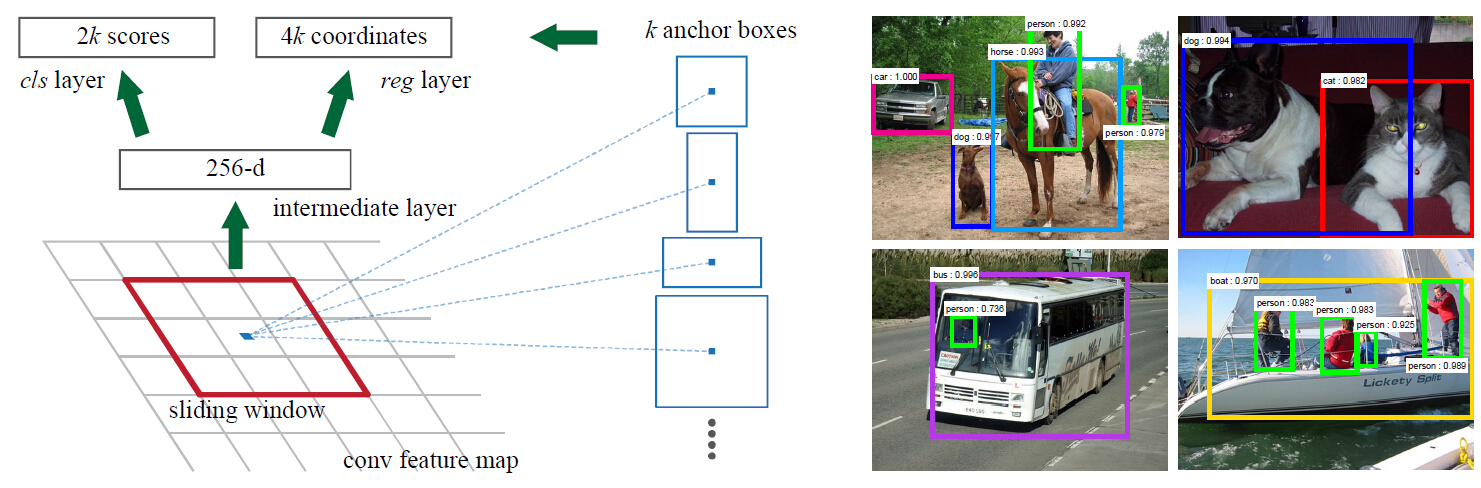
图3.左边:Region Proposal Network(RPN)。右边:使用RPN proposalzai PASCAL VOC 2007测试集上进行样本检测。文中方法检测的对象在尺度和长宽比上变化范围很大。
平移不变anchor(Translation-Invariant Anchors)
这种方法的一大主要特征是平移不变性(translation invariant),而类似于MultiBox之类的方法使用K-means来生成800个anchor,不具有平移不变性。
同时平移不变性降低了模型的大小。MultiBox有(4+1)*800维的全连接输出层,论文中的方法在k=9时仅有(4+2)*9维卷积输出层。因此,这种方法的参数远远少于MultiBox的参数。
多尺度anchor作为回归引用
我们对anchor的设计使用了一种新颖的机制来处理多尺度(以及长宽比)。图1展示了两种流行的多尺度预测(multi-scale prediction)方法。一种是基于图像/特征金字塔(image/feature pyramid)。这种方法将图像resize到多种尺度,然后为针对于一种尺度计算feature map或者深度卷积特征(deep convelotional feature),有效但是耗时。第二种方法是在feature map上使用多尺度(和/或长宽比)的滑窗。例如,DPM分别使用不同大小的filter来训练不同长宽比的模型。若这种方法用来解决多尺度问题,可以认为是“filter金字塔(pyramid of filters)”。第二种方法通常与第一种方法一起使用。
我们基于anchor的方法建立了一个anchor的金字塔(pyramid of anchors),更加高效。我们的方法对与多尺度和多长宽比的anchor box相关联的bounding boxes进行分类和回归。他仅仅依赖于单一尺度的图片和feature map,并且使用单一大小的filter(feature map上的滑窗)。
B. 损失函数(Loss function)
为了训练RPNs,我们为每个anchor设定了一个二值分类标签(是一个object或者不是)。我们给以下两类anchor标定一个正标签(positive label):(i)与ground-truth box有最高Intersection-over-Union (IoU)的anchor;(ii)与任意ground-truth box的IoU重叠超过0.7的anchor。并且给与所有ground-truth boxes的IoU比例小于0.3的非正anchor标定一个负标签(negative label)。
一张图片的损失函数定义为:
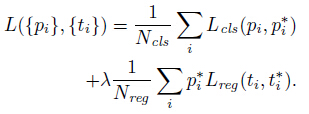 式(1)
式(1)
其中,i为一个anchor在一个mini-batch中的下标,pi是anchor i为一个object的预测可能性。如果这个anchor是positive的,则ground-truth标签pi*为1,否则为0。ti表示预测bounding box的4个参数化坐标,ti*是这个positive anchor对应的ground-truth box。分类的损失(classification loss)Lcls是一个二值分类器(是object或者不是)的softmax loss。回归损失(regression loss)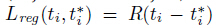 ,其中R是Fast R-CNN中定义的robust ross function (smooth L1)。pi*Lreg表示回归损失只有在positive anchor(pi*=1)的时候才会被激活。cls与reg层的输出分别包含pi和ti。
,其中R是Fast R-CNN中定义的robust ross function (smooth L1)。pi*Lreg表示回归损失只有在positive anchor(pi*=1)的时候才会被激活。cls与reg层的输出分别包含pi和ti。
这里还有一个平衡参数λ来权衡Ncls和Nreg。cls term标准化为mini-batch的大小(Ncls256),reg term标准化为anchor位置的数目(Nreg~2400)。默认λ=10。
对于bounding box的回归,我们应用了以下4个坐标的参数化:
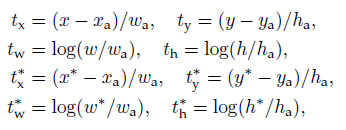
x、y、w、h表示box中心的坐标以及它的宽度和高度。变量x、xa和x*分别针对于预测的box、anchor boxhe ground-truth box(y、w、h也是一样的)。可以认为是从一个anchor box到一个附近的ground-truth box的bouding box回归。
然而,相对于之前基于感兴趣区域的(RoI-based)的方法,我们的方式通过一种不同的方式来获取bounding-box回归。在feature map上,我们用于回归的feature具有相同的空间大小(3×3)。为了解决变化大小的问题,让其学习k个bouding box回归量。每个回归量对应一个尺度和一个长宽比,并且k个回归量并没有共享权值。因此,尽管feature是固定的大小,仍能预测不同大小的box,多亏了anchor的设计。
C. 训练RPNs
RPN可以由反向传播(back-propagation)和随机梯度下降(stochastic gradient descent, SGD)来进行端到端训练。我们使用“image-centric”取样策略来训练这个网络。每个mini-batch来自于一张图片,包含许多positive样本anchor和negative样本anchor。可以对所有anchor的损失函数进行优化,但是这样会偏袒negative样本。取而代之,我们在一张图片中随机取样256个anchor来计算一个mini-batch的损失函数,取样的positive anchor和negative anchor的比例在1:1之上。若一张图像没有128个positive样本,则用negative样本来补充。
使用便准偏差为0.01的零均值高斯分布来对新增的两层进行随机初始化,其余使用ImageNet的模型来进行初始化。我们使用0.001的学利率来学习60k个mini-batches,以及0.001的学习率来学习后面PASCAL VOC数据集的20k个mini-batch。momentum=0.9,weight-decay=0.0005,使用了Caffe框架。
(2)RPN与Fast R-CNN共享特征
下面将介绍由RPN以及Fast R-CNN共享卷积层构成的统一网络的学习算法(图2)。通过交替优化来学习共享特征,训练算法包含4步:
step1:使用3.1.3节的方法来训练RPN。使用提前训练好的ImageNet模型来初始化,然后对region proposal task进行微调。
step2:使用step1中得到的proposal和Fast R-CNN来训练一个单独的detector network。这个detector network也是使用提前训练好的ImageNet模型来初始化。到这个时候两个网络还没有共享卷积层。
step3:我们step2中训练好的detector network来初始化RPN,然后训练。这里训练的使用固定共享卷积网络,只微调RPN部分的网络层。这个时候两个网络共享卷积层。
step4:保持共享卷积层固定,只微调Fast R-CNN部分的网络层。
这样,两个网络共享了相同的网络层,形成了一个统一的网络。
(3)实现细节
我们使用单一尺度的图片来对region proposal 和object detection network进行训练和测试。我们归一化图片使得它的较短边s=600像素。
对于anchor,使用三种scale,box的面积分别为128*128、256*256、和512*512,高宽比分别为1:1、1:2和2:1。这些参数不需要针对某一数据集进行谨慎选择(作者在下一章中对他们的影响进行了脱离实验)。文中的方法不需要一个图像金字塔或者filter金字塔来预测多尺度区域,节省了许多运行时间。图3右展示了文中方法处理大范围变化的尺度和长宽比的能力。表1展示了使用ZFnet学习的每个anchor的平均proposal大小。文中的算法允许与潜在接收域(underlying receptive field)大的预测。这样的预测不是不可能——即便只有object的中间部分是可见的,它仍然能粗糙地推断object的位置。
表1.对于每个anchor,使用ZF net学习的平均proposal大小(s=600)

穿过图片边界的anchor boxes应该小心处理。在训练的时候,忽略所有穿过边界的anchors。对一张1000*60的图像,大概总共有2000(≈60*40*9)个anchor。忽略穿过边界的anchor后,每张图片大概有6000个anchor来进行训练。然而,在测试的时候,将全卷积RPN应用到整张图片中。这有可能产生穿过边界的proposal boxes,作为图片边界减掉(文中写的是which we clip to the image boundary)。
一些RPN proposal彼此高度重合。为了减少冗余,在它们的cls score的基础上在proposal区域应用非极大抑制(non-maximum suppression,NMS)。NMS的IoU阈值固定为0.7,使得每张图片留下大概2000个proposal region。NMS并未降低最终的检测准确率。然后,使用2000个RPN proposal来训练Fast R-CNN,但是在测试的时候评估不同数目的proposal。
3.实验及结果
(1)PASCAL VOC中上的实验
数 据 集:PASCAL VOC 2007、2012 (包含5K张训练图像和5K张测试图像,超过20个object种类)
网 络:ZF net的“fast"版本(5个卷积层+3个全连接层) 和 VGG-16(13个卷积层+3个全连接层)
衡量标准:检测平均准确率(mean Average Precision,mAP)
A.一般实验及RPN消融实验
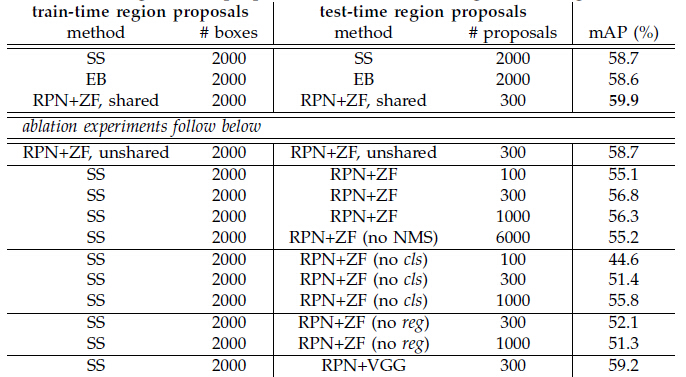
表2展示了当训练和测试使用不同的region proposal方法时Fast R-CNN的结果,使用了ZF net,其中 SS表示Selective Search [4],EB表示EdgeBoxes [6]。
表2.在PASCAL VOC 2007测试集上的检测结果(使用VOC 2007训练集进行训练),detector为Fast R-CNN+ZF,使用了不同的proposal方面进行测试和训练。
下面对上面表格中的6组实验进行一些说明:
a.第1组实验:
目的:验证region proposal生成方法的影响。
做法:在训练和测试中分别使用SS、EB和RPN+ZF(文中方法)这三种方法来生成region proposal进行实验。
结果:RPN+ZF获得了最佳结果,由于共享卷积计算,RPN+ZF速度也更快。
b.第2组实验
目的:验证RPN与Fast R-CNN检测网络之间共享卷积层的影响。
做法:在4步训练法进行到第2步后停止。
结果:正是因为第3步使用了detector-tuned特征来很好地调整RPN,使得proposal的质量提升。
c.第3组实验
目的:验证RPN对Fast R-CNN detector 网络的影响
做法:使用2000个SS proposals及ZF net来进行训练,固定detector,变化测试时候使用的proposal regions。在这组实验中,RPN并未与detector共享特征。
结果:SS+300 RPN proposals获得了最优结果,56.8%;测试时仅使用排在最前面的(top-ranked)100个proposal,仍能获得55.1%的mAP(第3组实验的第1个实验),说明排在前面的RPN proposal是准确的;在另一方面,极端地使用排在前面的6000个RPN proposals(不带NMS)获得了55.2%的mAP(第3组实验的第4个实验),说明NMS并未影响的mAP,并且可能降低虚警。
d.第4组实验
目的:验证cls层的影响。
做法:移除cls层(因此没有使用NMS/Ranking),从unscored regions中随机取样N个proposals。
结果:结果显示,cls scores影响排名最前面的proposals。
e.第5组实验
目的:验证reg层的影响。
做法:移除reg层(proposals变成了anchor boxes)。
f.第6组实验
目的:验证更加强大的网络对于RPN proposal质量的影响
做法:使用VGG-16来训练RPN,detector仍然用SS+ZF的detector(第3组实验中的第2个实验的detector)。
结果:mAP从56.8%(RPN+ZF)上升到了59.2%(RPN+VGG)。
B.VGG-16的性能
表3展示了在proposal和detection时都使用VGG-16,并在PASCAL 2007测试集上进行测试的结果(使用不同训练集或不同训练集的组合巡警训练)。“07”表示VOC 2007训练集,“07+12”表示VOC 2007训练集与VOC 2012训练集的合集。shared和unshared分别表示共享特征和不共享特征。对于RPN,训练Fast R-CNN的proposal数目为2000:
表3:在PASCAL 2007测试集上的测试结果

表4展示了在PASCAL 2012测试集上进行测试的结果(跟上面的实验的区别只是使用了不同的测试集,上表使用的是VOC 2007,这里使用的VOC 2012):
表4:在PASCAL VOC 2012上的测试结果

表5统计了统计了整个对象检测系统的时间。
表5:整个对象检测系统的时间。除了SS proposal是在CPU上进行测试的之外,其余都是在K40 GPU上进行的。“Region-wise"包括NMS,pooling,full-connected,以及softmax层。
表6、表7分别对应表3、表4,分别展示了在PASCAL VOC 2007和PASCAL VOC 2012测试集上进行测试时每一类对象的检测结果。
表6:PASCAL VOC 2007测试集上进行测试时每一类对象的检测结果(对应于表3)

表7:PASCAL VOC 2012测试集上进行测试时每一类对象的检测结果(对应于表4)

C. Sensitivities to Hyper-parameters
表8验证anchor设置的影响。
表8.使用不同anchor设置时Faster R-CNN在PASCAL VOC2007测试集上的检测结果,网络为VGG-16,训练集为VOC 2007训练集。使用3中尺度和3中长宽比(69.9%)的默认设置(表中最后一行的设置)与表3中的设置是一样的。

表9验证式(1)中不同λ值的影响。
表9.式(1)中使用不同λ值时,Faster R-CNN在PASCAL VOC 2007上的测试结果。网络为VGG-16,训练集为VOC 2007 训练集。默认设置λ=10(同表3)
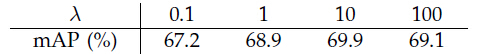
D.ReCall-to-IoU分析
接下来,文中计算了ground-truth bounding boxes具有不同IoU(Intersection-over-Union)比例的proposal的召回率。图4展示了使用300、1000、2000个proposals的结果,对比了SS、EB、RPN+ZF及RPN+VGG的方法。结果显示,当proposal的数目从2000降到300时,RPN的方法表现最佳。当proposal越少时,SS和 EB 相对于RPN下降得更快。

图4.Racall vs. IoU重叠率(PASCAL VOC 2007测试集)
E.One-stage vs.two-stage Proposal + Detection
这一部分的实验主要是对比了OverFat【9】的方法与本文的方法。
表10:One-stage vs.two-stage Proposal + Detection。检测结果为使用ZF模型及Fast R-CNN在VOC 2007测试集上的结果。RPN使用非共享特征。