Azure Data PlatformDedicated SQL Pool——导入性能测试——传统insert
Posted 發糞塗牆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Azure Data PlatformDedicated SQL Pool——导入性能测试——传统insert相关的知识,希望对你有一定的参考价值。
本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】使用Azure Blob Storage Lifecycle Management归档数据
本文介绍SQL DW,也称Synapse Analysis,或者最新的Dedicated SQL Pool的外部导数工具的对比。
前言
项目从前年开始从Azure SQL DB转换到SQL DW(我还是习惯用这个术语),其中一个原因是因为在宽表导入数据的过程中,SQL DB根本没法满足SLA。 哪怕使用可以使用的最高配置。那既然SQL DW在宽表/大表导入上有很好的性能表现,我们就来对比一下SQL DW内部的导入功能。
table distribution
SQL DW有3类表distribution:repeated, hash和round_robin, 第一种适合小表,按照官网说法,小表是导出来大小小于2GB的表。后面两种适合大表,其中Hash是按照一个指定的hash key进行分布。而round_robin则是完全平均分布。
所谓的数据分布,首先要了解SQL DW是一个分布式的系统,它有60 个distributions,不管它当前的DWU(性能配置)有多高。
接下来的几篇文章,会分别测试传统insert (从外部表), CTAS(polybase的实现)和Copy命令在同等DWU下,对一个相对较大的表从ADLS的文件导入到表中的性能,同时也会对比表的distribution, 是否有聚集列存储索引的效果。
本章会测试以下内容:
- table 为Hash distribution 的堆表和聚集列存储索引(CCI)的insert into select from external table的性能。
- table 为Round_robin distribution 的堆表和聚集列存储索引(CCI)的insert into select from external table的性能。
这次我们使用DWU2000c, 具有largerc resource class的账号进行测试。
环境准备
首先把一个表的数据导到ADLS上作为测试的数据源,这里选择一个253GB, 37亿行的数据作为测试源。
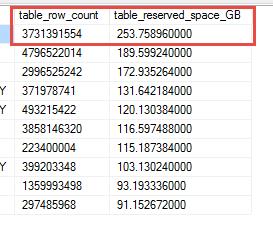
然后使用CTAS命令构建从SQL DW导出到ADLS的命令并执行,这个命令会把表以ParquetFF格式导出到ADLS的SQLDWTest目录下。

数据源已经准备好了,现在要实现导入,我们需要创建一个外部表(external table),让它作为桥梁打通ADLS与SQL DW。因为这是真实数据,不方便明文,所以大部分的内容会打码,我们只关注测试过程即可。
在导出的过程,我也做了一些监控,后面会专门用一篇文章来分析这些监控内容。
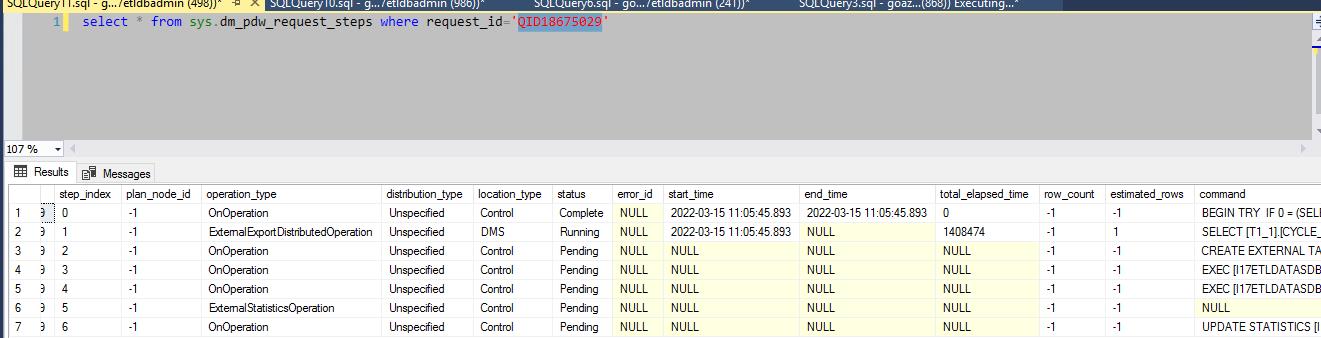
监控所用的SQL:
select ab.request_id, ab.step_index,ab.operation_type,ab.location_type,
ab.status,
ab.error_id,
ab.start_time,
ab.end_time,
ef.type as DMStype,
ef.status as DMSstatus,
ef.numthreads as DMSthreads,
ab.command, ef.sum_bytes_processed , ef.max_bytes_processed ,
ef.min_bytes_processed ,
ef.sum_rows_processed ,ef.min_rows_processed ,
ef.max_rows_processed ,
ef.sum_total_time,
ef.max_total_time,ef.min_total_time
from sys.dm_pdw_request_steps ab
inner join (
select b.request_id,b.step_index , b.type,status ,count(*) as numthreads, sum(cast(b.bytes_processed as bigint)) as sum_bytes_processed ,
max(b.bytes_processed) as max_bytes_processed ,
min(b.bytes_processed) as min_bytes_processed ,
sum(cast(b.rows_processed as bigint)) as sum_rows_processed , min(b.rows_processed) as min_rows_processed ,
max(b.rows_processed) as max_rows_processed ,
sum(cast(b.total_elapsed_time as bigint)) as sum_total_time,
max(b.total_elapsed_time) as max_total_time,
min(b.total_elapsed_time) as min_total_time
from sys.dm_pdw_dms_workers b
group by
b.request_id,b.step_index , b.type,b.status ) ef
on ab.request_id=ef.request_id and ab.step_index=ef.step_index
inner join (select request_id FROM sys.dm_pdw_exec_requests
where status not in ('Completed','Failed','Cancelled') and session_id <> session_id()) er
ON ab.request_id=er.request_id;
结果如下:

接上图:
这次导出花了接近1个小时:
导出的文件大小为91GB, 那么大概可以说,在使用压缩导出(parquet格式)后,数据的大小大概会降低30~50%。

导入测试
首先创建4个测试表:分别是Hash with CCI, Hash with heap, Round_robin with CCI, Round_robin with heap, 用来测试在有聚集列存储索引和堆表下,不同的distribution的性能差异。这个过程我尽量选择没有人使用系统的时间,所以其他会话对测试结果的影响时比较少的。
CREATE TABLE [dbo].test_hash_cci_insert
(--字段省略
)
WITH
(
DISTRIBUTION = Hash(hash列) ,
CLUSTERED COLUMNSTORE INDEX
)
GO
CREATE TABLE [dbo].test_robin_cci_insert
(--字段省略
)
WITH
(
DISTRIBUTION = round_robin,
CLUSTERED COLUMNSTORE INDEX
)
GO
CREATE TABLE [dbo].test_robin_heap_insert
(--字段省略
)
WITH
(
DISTRIBUTION = round_robin,
heap
)
GO
CREATE TABLE [dbo].test_hash_heap_insert
(--字段省略
)
WITH
(
DISTRIBUTION = hash(hash列),
heap
)
GO
下面来测试一下导入,首先创建一个外部表,打通ADLS跟SQL DW:
CREATE EXTERNAL TABLE xxxx (
省略列名
)
WITH (
LOCATION = 'SQLDWTest/文件名路径/*'
,DATA_SOURCE = [ext_ds_abfss]
,FILE_FORMAT = [ParquetFF]
);
--round_robin with heap
insert into [dbo].test_robin_heap_insert
select * from xxxx
--round_robin with cci
insert into [dbo].test_robin_cci_insert
select * from xxxx
--hash with heap
insert into [dbo].test_hash_heap_insert
select * from xxxx
--hash with cci
insert into [dbo].test_hash_cci_insert
select * from xxxx
期间监控如下结果:

接上图:


测试结果:
--round_robin with heap
--1:1:37
insert into [dbo].test_robin_heap_insert
select * from 外部表
--round_robin with cci
--52:50
insert into [dbo].test_robin_cci_insert
select * from 外部表
--hash with heap
--41:24
insert into [dbo].test_hash_heap_insert
select * from 外部表
go
--hash with cci
--1:00:08
insert into [dbo].test_hash_cci_insert
select * from 外部表
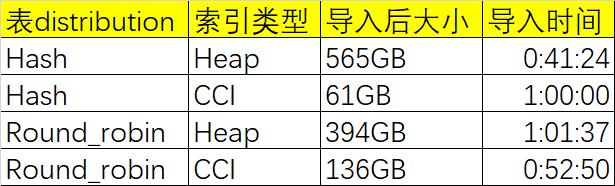
同时检查各个表在导入后的大小(初始大小,没有经过重建索引操作)

下面以表格形式总结:
小结
我们可以大概给出一个结论:
- insert 到Hash distribution 的堆表最快。
- 使用了CCI的表,由于有高度压缩的特性,所以普遍表大小都比较小。
但是其实我们很少使用单纯的Insert,如果非要这样做,SQL DW提供了Copy命令来实现,这个在第三篇文章会演示。在这里只是做一个对比而已。微软建议以SQL命令来导入,尽可能使用PolyBase和Copy命令来实现。
下一篇我们会使用CTAS功能来再做一次比较。
以上是关于Azure Data PlatformDedicated SQL Pool——导入性能测试——传统insert的主要内容,如果未能解决你的问题,请参考以下文章