spark.mllib源码阅读-bagging方法
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark.mllib源码阅读-bagging方法相关的知识,希望对你有一定的参考价值。
在训练集成分类器时,关键的一步在于如何从全训练样本集中构建子样本集提供给子分类器进行训练。目前主流的两种子样本集构造方式是bagging方法和boosting方法。bagging方法的思想是从全样本集中有放回的进行抽样来构造多个子样本集,每个子样本集中可以包含重复的样本。对每个子样本集训练一个模型,然后取平均得到最后的集成结果。
bagging
bagging方法的主要目的是为了降低模型的variance,由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。由于
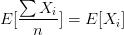
所以bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,则有
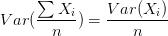
此时可以显著降低variance。若各子模型完全相同,则
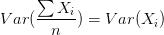
此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。(摘自知乎)。
如需要进一步的降低模型的variance,则需要降低各个子模型之间的相关性,Random forest通过随机选取特征集子集来做到这一点。因此,在需要降低模型variance时,一方面可以通过bagging方法来选取子样本集构造子模型,另外一方面,每个子模型之间的特征相关性需要尽量小。
boosting
boosting方法是各个子模型在迭代中串行地产生的。训练时着重关注训练集中那些不容易区分的样本。AdaBoost是一种典型的boosting方法,其算法思想是:给训练集中的元组重新分配权重,权重影响抽样,权重越大,越可能被抽取。迭代训练若干个分类器,在前一个分类器中被错误分类的元组被提高权重;最后由所有分类器一起投票(投票权重取决于分类器的准确率),决定分类。由于boosting方法在子模型的训练过程中关注那些被上一个子模型损失较大的样本(在分类问题中是误分的样本,在回归问题中是残差较大的样本),在逐轮的迭代过程中,整个模型的输出会逐渐收敛至目标值,因此,boosting方法会降低模型的bias。
目前,bagging方法和boosting方法方法在Spark中都有实现,其中bagging方法的抽样过程是由BaggedPoint类实现的,而boosting方法则主要提现在模型迭代的过程中,目前仅对决策树实现了boosting方法即GradientBoostedTrees类。
在这一篇博客中将主要介绍bagging方法的Spark实现,boosting方法留待后续分析GBDT时介绍。BaggedPoint是Spark实现样本抽样来构造子样本集的类,BaggedPoint进行样本抽样,分为有放回抽样和无放回抽样两种。
有放回抽样,使用柏松分布根据输入的抽样比率,抽样份数进行抽样。
/**
* 使用PoissonDistribution模拟抽样,有放回抽样
* @param input
* @param subsample
* @param numSubsamples
* @param seed
* @tparam Datum
* @return
* p(x=k)=theta^^k / k! * e^^(-theta)
* 样本均值的期望为p,此处为抽样率subsample。因此抽样样本数的期望为 subsample*样本总数
*/
private def convertToBaggedRDDSamplingWithReplacement[Datum] (
input: RDD[Datum],
subsample: Double,
numSubsamples: Int,
seed: Long): RDD[BaggedPoint[Datum]] =
input.mapPartitionsWithIndex (partitionIndex, instances) => //partitionIndex:分区ID, instances:分区数据的迭代器
// Use random seed = seed + partitionIndex + 1 to make generation reproducible.
val poisson = new PoissonDistribution(subsample)//设定抽样比率
poisson.reseedRandomGenerator(seed + partitionIndex + 1)
instances.map instance => //
val subsampleWeights = new Array[Double](numSubsamples)
var subsampleIndex = 0
while (subsampleIndex < numSubsamples) //在每个分区抽样numSubsamples次,BaggedPoint保存的是<数据实例,<2,0,3...>>
subsampleWeights(subsampleIndex) = poisson.sample()
subsampleIndex += 1
new BaggedPoint(instance, subsampleWeights)
无放回抽样,使用XORShiftRandom随机数生成算法进行抽样。
//无放回抽样,每个子样本集只包含一次该样本
private def convertToBaggedRDDSamplingWithoutReplacement[Datum] (
input: RDD[Datum],
subsamplingRate: Double,
numSubsamples: Int,
seed: Long): RDD[BaggedPoint[Datum]] =
input.mapPartitionsWithIndex (partitionIndex, instances) =>
// Use random seed = seed + partitionIndex + 1 to make generation reproducible.
val rng = new XORShiftRandom
rng.setSeed(seed + partitionIndex + 1)
instances.map instance =>
val subsampleWeights = new Array[Double](numSubsamples)
var subsampleIndex = 0
while (subsampleIndex < numSubsamples)
val x = rng.nextDouble()
subsampleWeights(subsampleIndex) =
if (x < subsamplingRate) 1.0 else 0.0
subsampleIndex += 1
new BaggedPoint(instance, subsampleWeights)
抽样方法返回的是一个BaggedRDD<BaggedPoint>,BaggedPoint(datainstance, subsampleWeights),其中data instance 即为一个样本实例,subsampleWeights是一个形式为[1, 0, 4]的数组,表示抽样份数为3份,数组中的数字表示该样本在对应抽样样本集中出现的次数。这样的好处是只保留了一份原始样本集,构建了多个不同的"视图"即抽样样本集,一定程度上节省了内存。
另外,目前业界对bagging方法的实现主要是Randomforest,其它的诸如逻辑斯蒂回归、SVM等等算法上并没有采用这一方法,个人认为,其主要原因决策树具有良好的特征自选择性,而不会去使用全部的特征,一定程度上降低了各个子模型的相关性。当然,我们也可以人工的为各个子模型选择特征子集,这样就可以适用于其它算法上了。
以上是关于spark.mllib源码阅读-bagging方法的主要内容,如果未能解决你的问题,请参考以下文章