实时即未来,车联网项目之原始终端数据实时ETL
Posted 码农Maynor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时即未来,车联网项目之原始终端数据实时ETL相关的知识,希望对你有一定的参考价值。
文章目录
Flink 将报文解析后的数据推送到 kafka 中
-
步骤
-
开启 kafka 集群
# 三台节点都要开启 kafka [root@node01 kafka]# bin/kafka-server-start.sh -daemon config/server.properties -
使用 kafka tool 连接 kafka 集群,创建 topic
# 第1种方式通过命令 bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic vehicledata --replication-factor 2 --partitions 3 # 查看 kafka topic 的列表 bin/kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --list # 第2种 kafka tool 工具
-
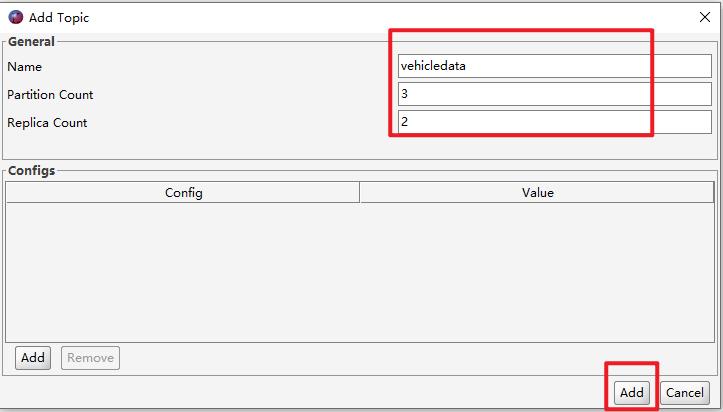
-
通过 flink 将解析后的报文 json 字符串推送到 kafka 中
package cn.maynor.flink.source; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import javax.annotation.Nullable; import java.util.Properties; /** * Author maynor * Date 2021/9/20 9:11 * 实现flink将数据写入到kafka集群中 * 开发步骤: * 1.开启流处理环境 * 2.设置并行度、chk、重启策略等参数 * 3.创建FlinkKafkaProducer类 * 3.1.配置属性 * 4.设置数据源 * 5.执行流处理环境 */ public class FlinkKafkaWriter public static void main(String[] args) //1.开启流处理环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //2.设置并行度、chk、重启策略等参数 env.setParallelism(1); //2.1.读取车辆 json 数据 DataStreamSource<String> source = env .readTextFile("F:\\\\1.授课视频\\\\4-车联网项目\\\\05_深圳24期\\\\全部讲义\\\\2-星途车联网系统第二章-原始终端数据实时ETL\\\\原始数据\\\\sourcedata.txt"); //3.创建FlinkKafkaProducer类 //3.1.配置属性 Properties props = new Properties(); props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092,node02:9092,node03:9092"); props.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "5"); props.setProperty(ProducerConfig.ACKS_CONFIG, "0"); //props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.flink.api.common.serialization.SimpleStringSchema"); //3.2.实例化FlinkKafkaProducer FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>( "vehicledata", new KafkaSerializationSchema<String>() @Override public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) return new ProducerRecord( "vehicledata", element.getBytes() ); , props, FlinkKafkaProducer.Semantic.NONE ); //4.设置数据源 source.addSink(producer); //5.执行流处理环境 try env.execute(); catch (Exception e) e.printStackTrace();
实时ETL开发
- 创建模块 —— StreamingAnalysis
- 导入项目的 pom 依赖
- 常见包的含义 task , source ,sink ,entity
- 配置文件的导入 conf.properties 和 logback.xml
- 工具类的走读
- 日期处理
- 读取配置文件 静态代码块
- 字符串常用工具 - 字符串翻转
- JSON 字符串转对象
原始数据的实时ETL设置
开发的流程
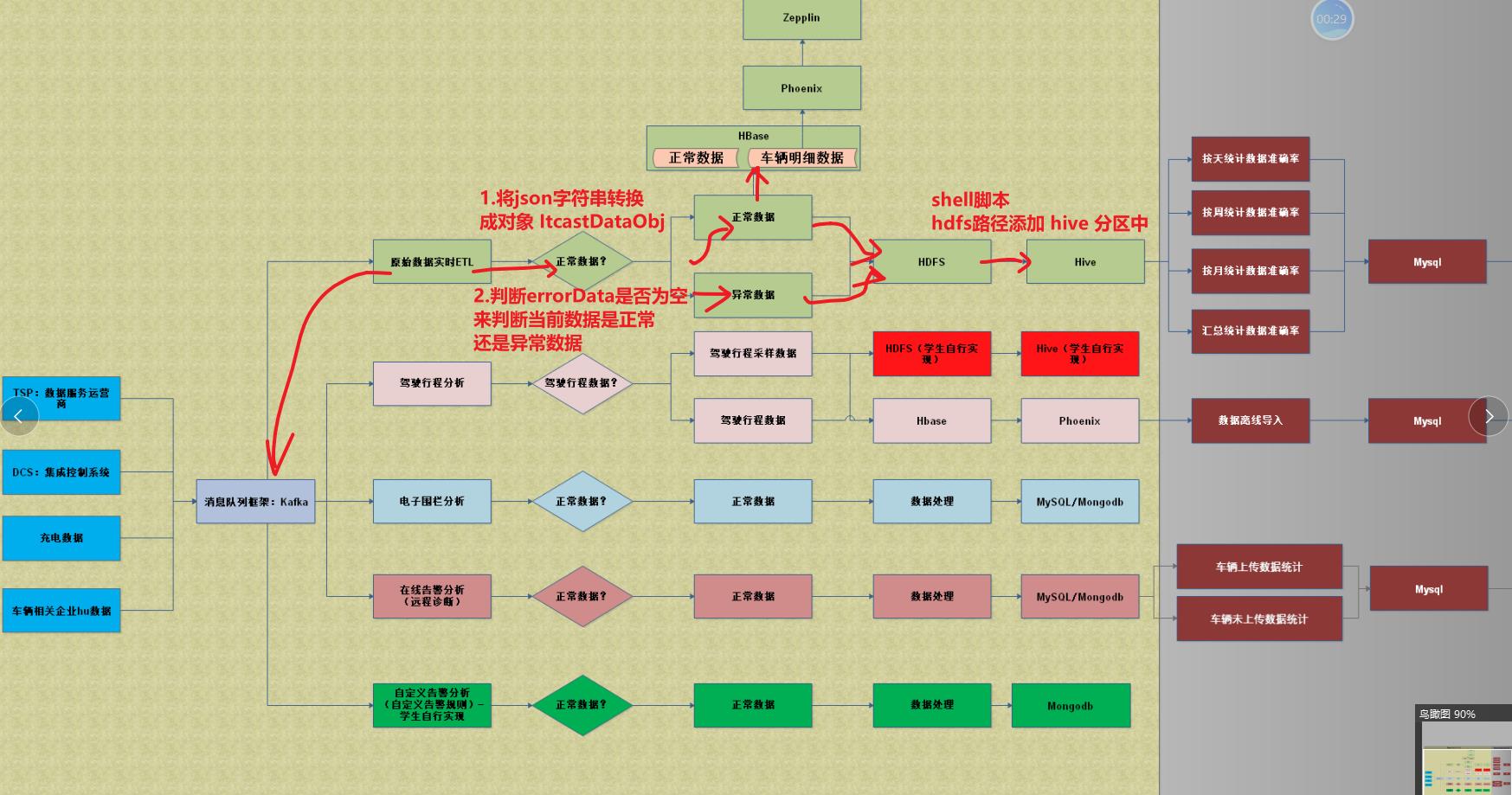
开发的类名 —— KafkaSourceDataTask
//todo 1.创建流执行环境
//todo 2.设置并行度 ①配置文件并行度设置 ②客户端设置 flink run -p 2 ③在程序中 env.setParallel(2) ④算子上并行度(级别最高)
//todo 3.开启checkpoint及相应的配置,最大容忍次数,最大并行checkpoint个数,checkpoint间最短间隔时间,checkpoint的最大
//todo 容忍的超时时间,checkpoint如果取消是否删除checkpoint 等
//todo 4.开启重启策略
//todo 5. 读取kafka中的数据
//todo 5.1 设置 FlinkKafkaConsumer
//todo 5.2 配置参数
//todo 5.3 消费 kafka 的offset 提交给 flink 来管理
//todo 6 env.addSource
//todo 7 打印输出
//todo 8 将读取出来的 json 字符串转换成 maynorDataObj
//todo 9 将数据拆分成正确的数据和异常的数据
//todo 10 将正确的数据保存到 hdfs
//todo 11 将错误的数据保存到 hdfs 上
//todo 12 将正确的数据写入到 hbase 中
//todo 8 执行流环境
设置 checkpoint 中 statebackend
-
配置的地方有两种
- 配置文件中 flink-conf.yaml
- 在 job 中配置 env.setStateBackend()
-
配置的方式三种
- memorystatebackend
- fsStatebackend
- rocksdbStatebackend(状态特别大的使用)
-
配置读取kafka的数据的设置
数据积压和反压机制
-
就是生产的数据大于消费的数据的速度,造成数据的积压
-
解决反压机制的方法
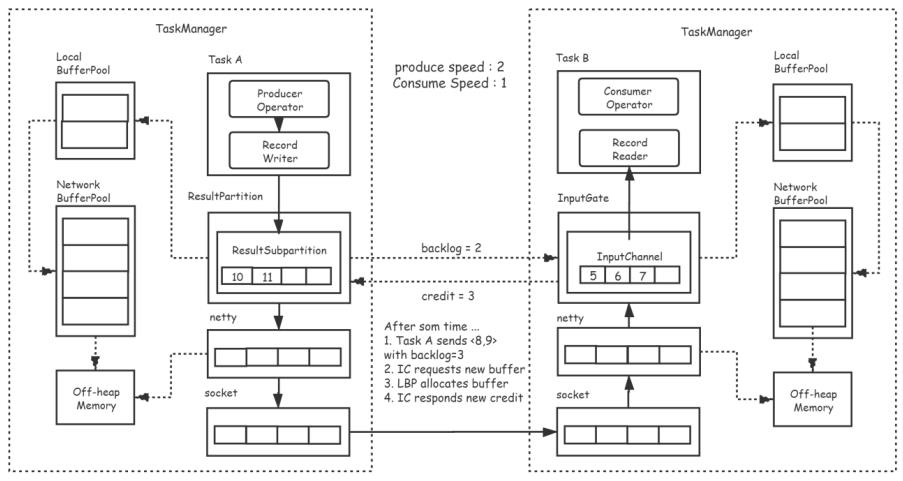
通过 credit 和 反压策略解决数据堆积问题
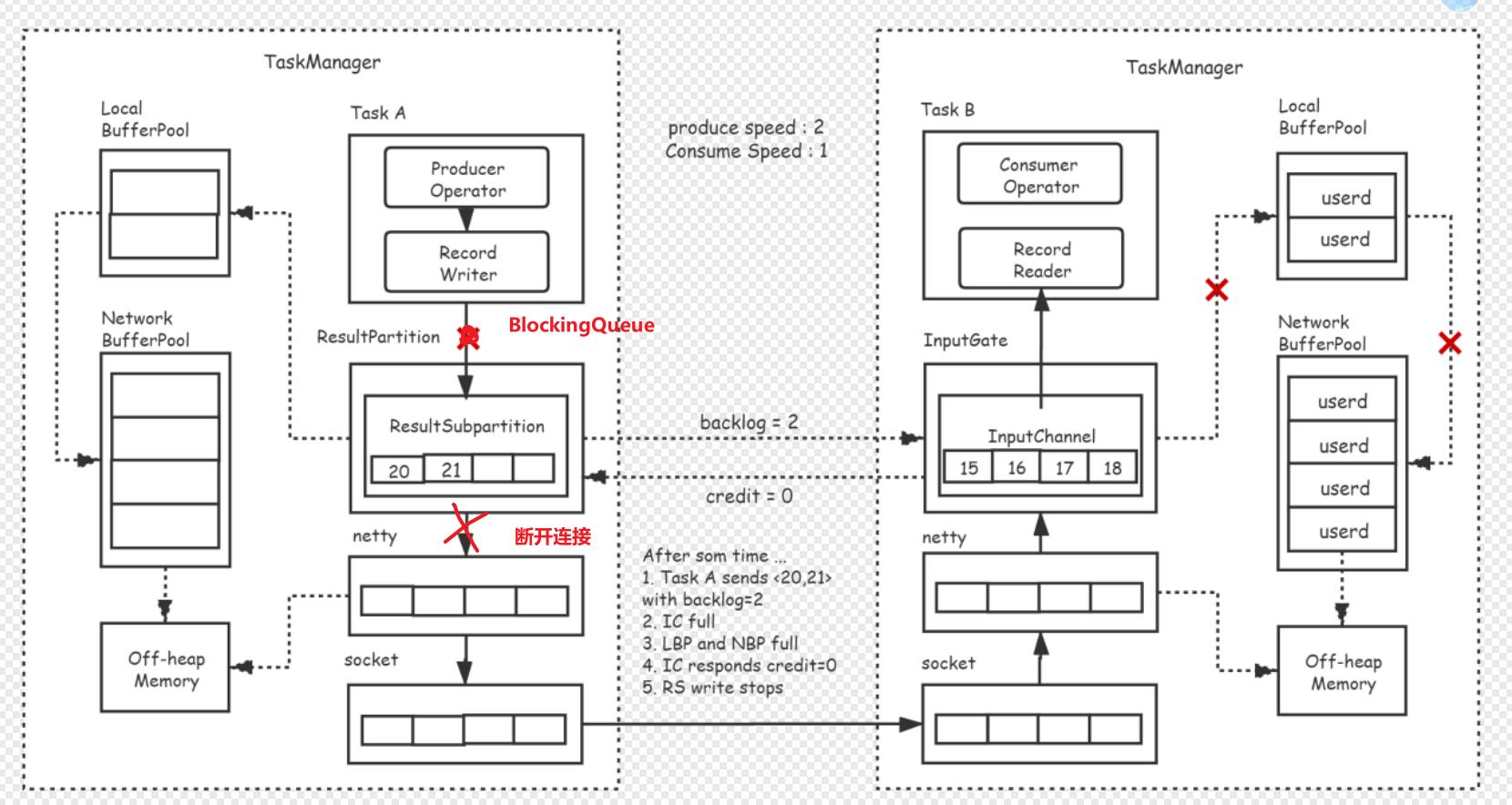
抽象 BaseTask 用于处理数据流和读取kafka数据
- 将公共的固定的代码抽象出来 BaseTask 抽象类
- 使用 Flink 的自带的 ParameterTool 来接收 client 或 配置文件中的配置
以上是关于实时即未来,车联网项目之原始终端数据实时ETL的主要内容,如果未能解决你的问题,请参考以下文章
实时即未来,大数据项目车联网之原始数据实时ETL任务消费数据策略
实时即未来,大数据项目车联网之原始数据实时ETL任务消费数据策略
实时即未来,大数据项目车联网之原始数据实时ETL落地HBase