Spark算子执行流程详解之五
Posted 亮亮-AC米兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark算子执行流程详解之五相关的知识,希望对你有一定的参考价值。
22.combineByKey
| def combineByKey[C](createCombiner: V => C, |
关注其入参:
combineByKey函数主要接受了三个函数作为参数,分别为createCombiner、mergeValue、mergeCombiners。这三个函数足以说明它究竟做了什么。理解了这三个函数,就可以很好地理解combineByKey。
要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。由于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的键相同。combineByKey()的处理流程如下:
如果是一个新的元素,此时使用createCombiner()来创建那个键对应的累加器的初始值。(!注意:这个过程会在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。)
如果这是一个在处理当前分区中之前已经遇到键,此时combineByKey()使用mergeValue()将该键的累加器对应的当前值与这个新值进行合并。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()将各个分区的结果进行合并。如果mergeCombiners为True,则在map的输出的时候提前进行一次合并,如果mergeCombiners为false,则在reduce结果的时候进行一次合并。提前进行合并的作用是为了减少shuffle读取的时候传输的数据量,提升shuffle read的速度。
先来看下ShuffleRDD里面的依赖:
| class ShuffledRDD[K, V, C]( |
通过向shuffleManager注册获取shuffle读写句柄,默认的shufflemanager是SortShuffleManager
| class ShuffleDependency[K, V, C]( |
通过getwriter和getreader获取各自的读写句柄
| private[spark] class SortShuffleManager(conf: SparkConf) extends ShuffleManager |
先看写句柄SortShuffleWriter:
| private[spark] class SortShuffleWriter[K, V, C]( |
且看ExternalSorter的insertAll:
| def insertAll(records: Iterator[_ <: Product2[K, V]]): Unit = |
接着看读句柄HashShuffleReader:
| private[spark] class HashShuffleReader[K, C]( |
因此假设一下的场景combineByKey的mapSideCombine一个为false,另外一个为true的情况:
| val initialScores = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 93.0), ("Wilma", 95.0), ("Wilma", 98.0)) val d1 = sc.parallelize(initialScores) type MVType = (Int, Double) //定义一个元组类型(科目计数器,分数) d1.combineByKey( score => (1, score), (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore), (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2), RangePartitioner, false ).map case (name, (num, socre)) => (name, socre / num) .collect d1.combineByKey( score => (1, score), (c1: MVType, newScore) => (c1._1 + 1, c1._2 + newScore), (c1: MVType, c2: MVType) => (c1._1 + c2._1, c1._2 + c2._2), ).map case (name, (num, socre)) => (name, socre / num) .collect |
mapSideCombine为false的执行流程如下:

mapSideCombine为true的执行流程如下:

可见提前在map端做聚合可以减少shuffle过程中产生的数据。
23.distinct()
去重,删除RDD中相同的元素
| def distinct(): RDD[T] = withScope def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope |
最终调用的还是combineByKey,因为对于RDD最终的聚合类操作,其本质运算都是由combineByKey完成的。其具体的执行流程如下:
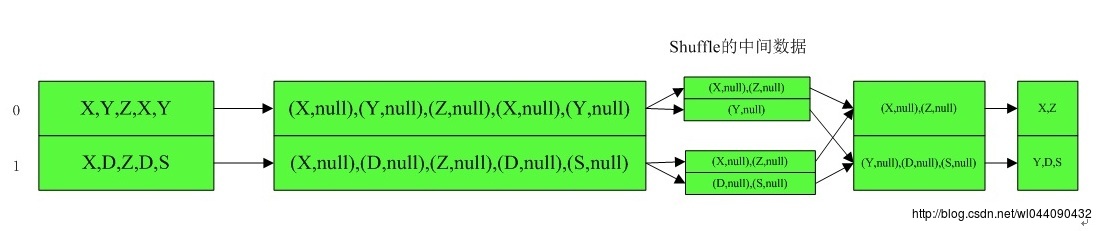
24.groupByKey
将相同key的记录聚合起来
| /** |
其本质就是利用combineByKey来实现相同KEY的聚合操作,但是需要注意的一点是groupByKey不在map端聚合,因为它在map端聚合无法减少网络传输的数据量,反而会增加maptask运行消耗的java内存,进而导致GC拖慢整个计算过程。
现在假设分区函数相同和不同的情况下其groupbykey的执行流程如下:
分区函数相同:
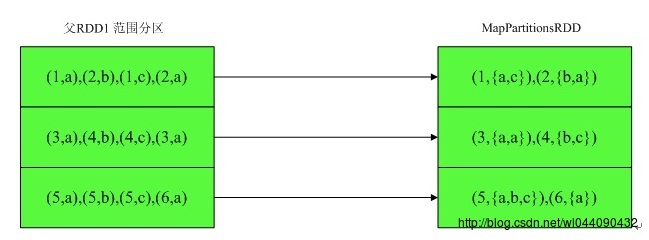
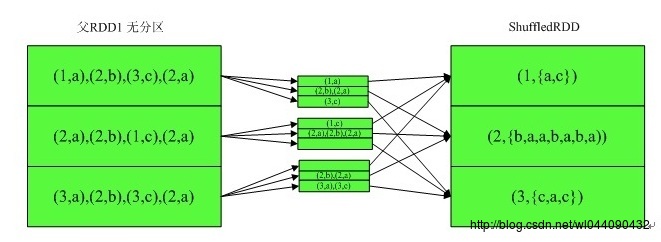
分区函数不相同:
25.aggregateByKey
聚合操作,将相同的key的value聚合起来,类似于sql里面的聚合函数,可以实现求max,min,avg等操作。
| /** / def aggregateByKey[U: ClassTag](zeroValue: U, numPartitions: Int)(seqOp: (U, V) => U, /** |
首先需要和aggregate操作区别开来,aggregate里面的SeqOp和combOp都会使用zeroValue的值,而aggregateByKey的zeroValue只会在SeqOp中使用。且其mapSideCombine为true,会在map端进行聚合,假设利用aggregateByKey计算每月平均气温的操作如下:
| val rdd = sc.textFile("气象数据") val rdd2 = rdd.map(x=>x.split(" ")).map(x => (x(0).substring("从年月日中提取月"),x(1).toInt)) val zeroValue = (0,0) val seqOp= (u:(Int, Int), v:Int) => (u._1 + 1, u._2 + v)
val compOp= (c1:(Int,Int),c2:(Int,Int))=> (u1._1 + u2._1, u1._2 + u2._2)
val vdd3 = vdd2.aggregateByKey( zeroValue , seqOp, compOp )
rdd3.foreach(x=>println(x._1 + ": average tempreture is " + x._2._2/x._2._1) |
由于rdd2是从rdd转化而来,而rdd是来自文本数据,则其无分区函数,而aggregateByKey执行时是以hash分区的,那么其计算过程如下:
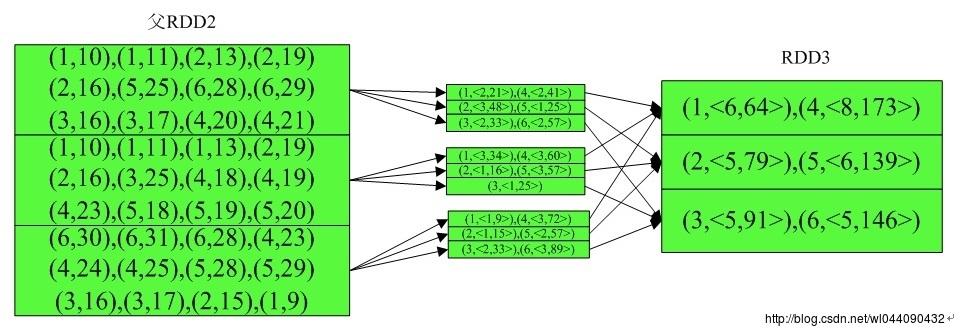
以上是关于Spark算子执行流程详解之五的主要内容,如果未能解决你的问题,请参考以下文章