利用CRNN来识别图片中的文字(一)数据预处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用CRNN来识别图片中的文字(一)数据预处理相关的知识,希望对你有一定的参考价值。
参考技术A 数据集中含有10072个图片文件和10072个图片所对应的包含图片中中文字内容的文本文。1.得到图片数据集中所有的中文字符,构成字符字典,字典大小为所包含不同中文字符的类别数;(dict_size=992,加上一个“空白”,在CTC中一共含有992+1=993个类别)
2.构建训练数据 train_x,train_y; train_x中每一个元素为一张图片(cv2.imread()读取的灰度图),train_y 中每一个元素为图片对应的文字在字符字典中的序号;
返回path路径下的符合条件的所有文件,然后用for循环对每一个文件进行操作。
用于打开一个文件。创建一个 file 对象,相关的方法才可以调用它进行读写。
readline()函数读取整行,包括 "\n" 字符。
返回一个无序不重复元素集(这里用于删除重复的中文字符)。
用于将元组转换为列表。
人口普查分析:利用python+百度文字识别提取图片中的表格数据
今天发布了最新的人口普查结果,笔者拿到的文件是pdf格式(网上应该有)。之前就一直想实现从pdf提取表格数据,输出为excel。正好这次有公开数据,因此打算用来练个手。
尝试了两种方法:
1.python的pdfplumber包:利用pdfpumber中的extract_table()方法,可以直接将pdf中表格抽取转换成excel,但是对于不规则的表格(比如有合并单元格、分布在两页中)抽取效果不太理想
2. python+百度智能云的文字识别:需要把pdf先转换成图片,再通过图片识别完成(其实。。。感觉有些多此一举。。。),不过对于边框有缺失的表格感觉效果一般。
以下是用 python+百度智能云的文字识别抽取表格信息的步骤:
零经验新手第一次尝试,正好写的稍微细致一些
声明:代码使用python3实现
!!!前期准备
1. 注册百度智能云账号:也可以用百度云账号。需要完成实名认证,并进行刷脸认证(这一步被迫下载了百度智能云app,吐槽!!为什么要另外下载app,用百度云app不香么。。。)
2. 登录百度智能云并开通通用文字识别的应用:在这个官方网站里https://ai.baidu.com/tech/ocr/general选择免费使用就行(新手练习的次数够了,我爱开放平台!)
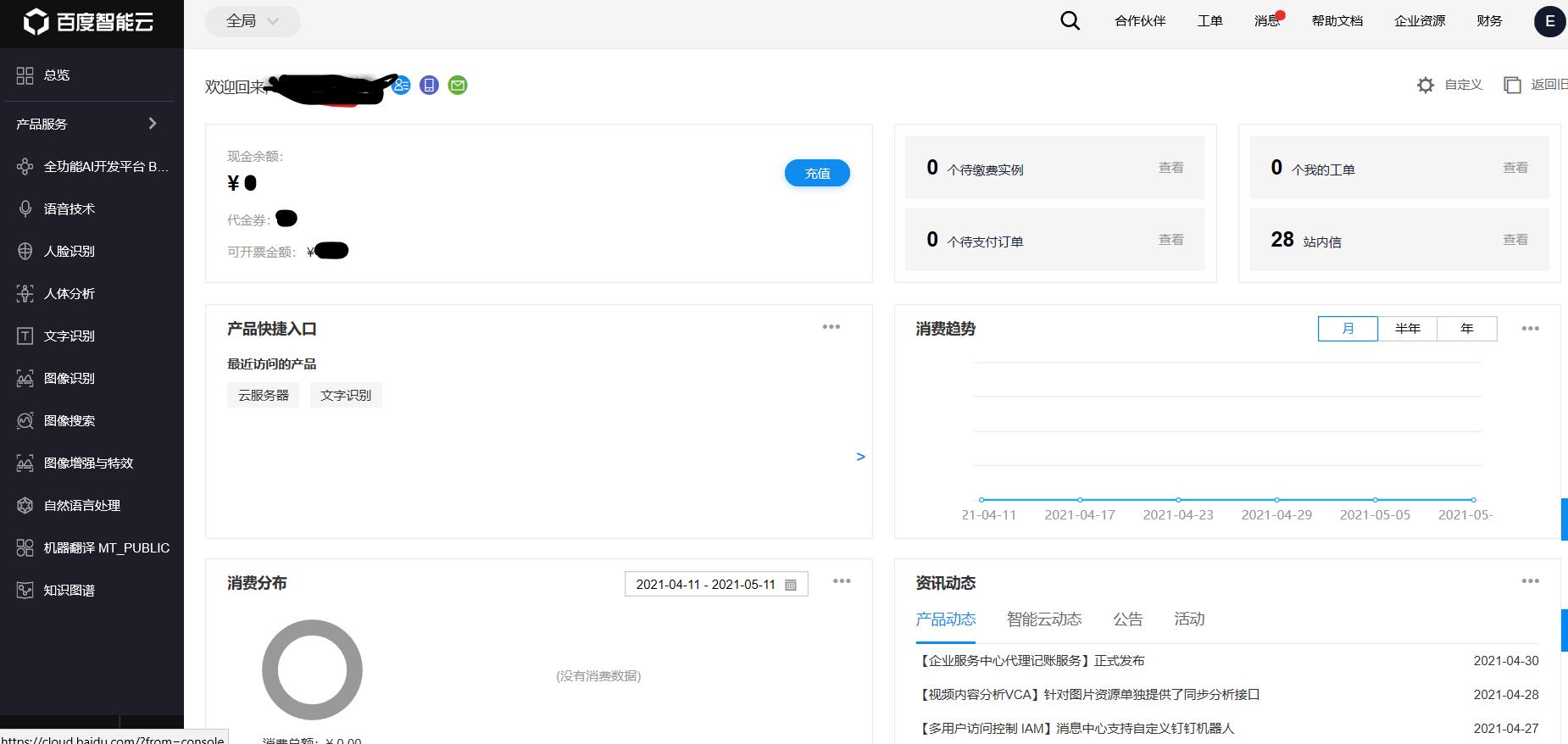
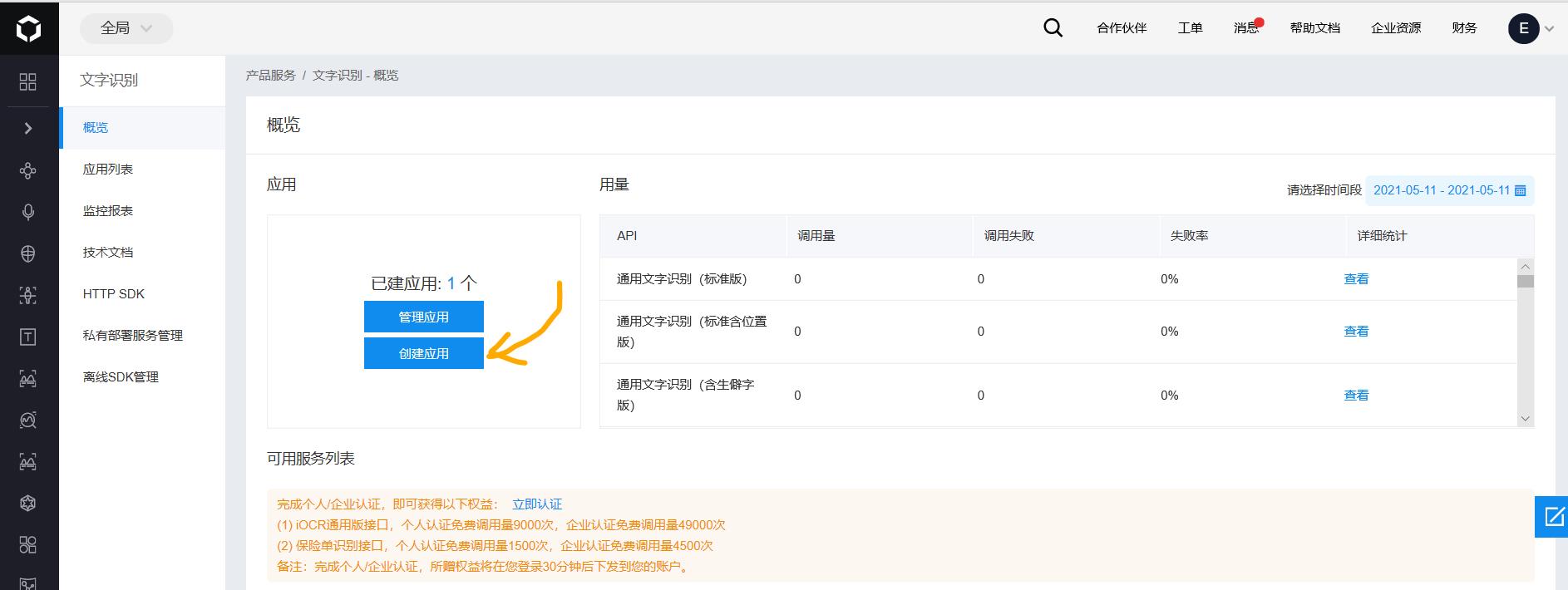
3. 创建应用:这一步是为了获取后续请求接口时需要使用到的API Key和Secret Key,个人理解有点像用户名和密码,发送请求和获取结果接口的时候需要使用到。点击上图中左边栏的”文字识别“,然后出现下图的界面后,点击”创建应用”即可。具体该怎么创建,也可以百度搜索,此处省略一些描述。。。
!!!python准备
!!给python安装sdk:
csdn里搜到的安装sdk的代码是:
pip install baidu-aip百度云官网提供的讲解视频里写的安装sdk代码是:(视频讲解地址:https://cloud.baidu.com/doc/APIGUIDE/s/Ek1mzbeek)
pip install bce-python-sdk我也不知道哪个是对的或者有用的,所以都安装了。。。(求大佬指点)
也可以从百度云官网下载sdk包,手动安装:https://cloud.baidu.com/doc/Developer/index.html
!!!终于可以进入正文了,代码实现
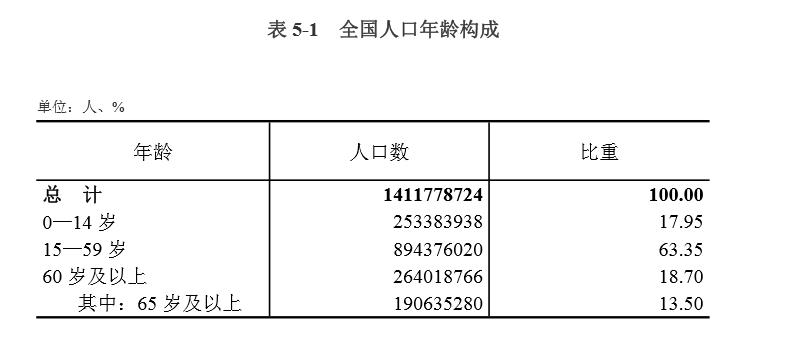
本次测试的图片来自今天最新发布的人口普查分析。因为百度文字识别不能识别pdf,只能用图片,所以先把pdf里表格部分截图(从这步开始,此方法就不适合多表格多页PDF了。。)
具体的实现代码如下:
【步骤一:获取access toke】
官网的说明文档里面提供了代码示例和说明,网址如下:https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu
import requests #在第一、二、三步都需要调用
import base64 #在第二、三步需要调用
'''
使用百度智能云的表格文字识别(异步接口)获取图片中表格数据
'''
#步骤一:获取Access token
# 需要将官方文档中提供的host中client_id=【官网获取的AK】&client_secret=【官网获取的SK】的黑框内容替换
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】'
response = requests.get(host)
response = requests.get(host)
if response:
#print(response.json()) 官网代码示例中给的,打印返回结果,可以查看返回的内容
#print(type(response.json())) 我自己加的,打印返回结果的类型,发现是一个字典
#需要取键名为“access_token”的value
token_result = response.json()
access_token = token_result.get('access_token')
print(access_token)通用场景文字识别中的表格文字识别(异步接口)官方说明中提供了代码示例(墙裂推荐阅读!!),网址如下:https://cloud.baidu.com/doc/OCR/s/Ik3h7y238
【步骤二:提交请求接口】
按照官网的说明,这一步可以通过调整参数is_sync,实现同步获取识别结果。(下次可以试试~)
#步骤二:提交请求接口
#请求URL,从上面提到的官方说明中查到的,不用修改,直接粘过来
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/request"
# 二进制方式打开图片文件,把图片文件与本代码文件保存在一个文件夹里
f = open('全国人口年龄构成.png', 'rb')
img = base64.b64encode(f.read())
#请求主体,image是必选参数,其他可选参数详见官方说明
params = "image":img
#access_token来自第一步,即调用鉴权接口获取的token
request_url = request_url + "?access_token=" + access_token
headers = 'content-type': 'application/x-www-form-urlencoded'
response = requests.post(request_url, data=params, headers=headers)
if response:
# print (response.json()) 这是官网提供的代码示例,如成功返回,则应该是一个包含了键名为 'result'和'log_id'的字典
# 成功返回结果的文件结构如下:'result': ['request_id': '一串字符'], 'log_id': 一串数字
#从返回结果文件中获取后续步骤需要用到的request_id和log_id
result = response.json()
result_id = result.get('result')
request_id = result_id[0].get('request_id') #说明:result_id是一个含有一个值的列表,而这个值的类型是字典。
log_id = result.get('log_id')
print (request_id, log_id) #查看是不是成功获取【步骤三:获取结果接口】
基本上就是步骤二的代码,但是注意更新URL,因为获取结果接口的URL和提交请求接口的URL不同
#步骤三:获取结果接口
#请求URL,注意与提交请求时的URL不一样!从官方文档获取,直接黏贴即可,不要修改
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/get_request_result"
#请求主体,可以传递两个参数:request_id和result_type,详见官方文档
#request_id: 必选参数,来自第二步的返回结果
#result_type:可选参数,可以选择传回结果类型为Excel还是json,默认为Excel
params = "request_id":request_id
#access_token来自第一步
request_url = request_url + "?access_token=" + access_token
headers = 'content-type': 'application/x-www-form-urlencoded'
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
#response.json()是返回一个字典类型对象
因为采用的传回结果类型是excel, 所以response.json()对象中有一个'result_data'键,这个’result_data'键值是一个网址,将网址复制黏贴到浏览器里,会弹出提示下载excel的提示框
下载后就是本次图片的表格文字识别的结果,结果包含多个sheet,包括表格主体内容、表格标题等,见下图:
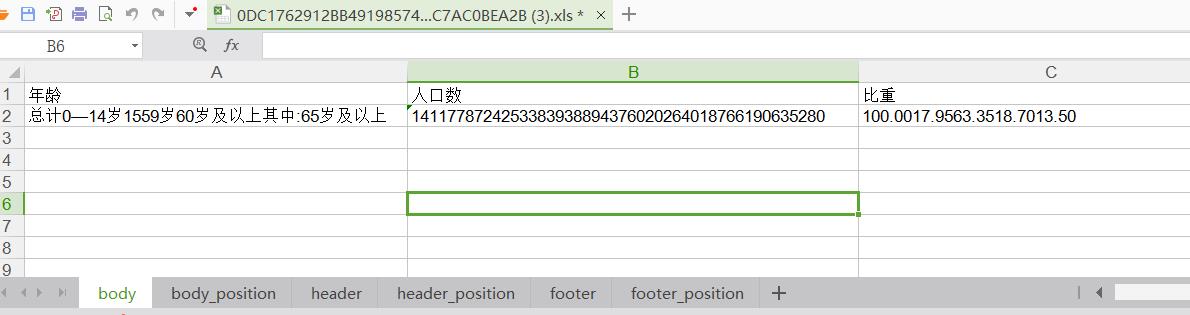
猜测,因为图片中的表格内容中间没有框线,所以不同行的内容都在一个单元格里了。
总之,效果一般般。对于没有框线或者框线部分缺失的表格,慎用
以上是关于利用CRNN来识别图片中的文字(一)数据预处理的主要内容,如果未能解决你的问题,请参考以下文章