hive之udf函数的使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive之udf函数的使用相关的知识,希望对你有一定的参考价值。
参考技术A udf的全称是User Defined Function用户自定义函数,创建后可以直接在select语句中使用使用中需要注意的是,创建一个udf需要继承org.apache.hadoop.hive.ql.exec.UDF,并且要对evaluate进行overwrite
所以开发工程需要至少加上依赖包
然后创建一个类继承UDF,实现evaluate方法可以实现传入一个数据返回一个数据的效果
下面以信息脱敏为例
以上通过调用函数传入信息,然后数据处理后会返回一个脱敏信息。
接着需要用maven对这个进行package,生成jar包,将文件上传到服务器上。
以下流程注意登陆账户是否有权限
并建议将此jar包上传到分布式文件系统上,可以参考如下命令:
hdfs dfs -put /home/hive-udf/desensitization.jar /lib/hive_udf/
然后可以通过hdfs dfs -ls /lib/hive_udf/查看已上传成功的包
然后进入hive客户端:可以直接在服务器上使用hive的bin包下的hive进行直接连接,也可以是其他连接方式。
这里有两种方法进行创建,一个是创建临时函数,一个是创建永久函数
1.创建临时函数
用此种方式的话,请在sql前加上后面两句
add jar hdfs:///lib/hive_udf/desensitization.jar;
create temporary function desensitization as 'com.sfz.Desensitization';
注意:这里的desensitization为以后调用的函数名,com.sfz.Desensitization为jar包里的类路径。
然后可以进行测试
select desensitization("我是傻疯子");
最后删除命令为:(临时函数可以不用删除,窗口关闭后会消失)
drop temporary function desensitization;
2.创建永久函数
CREATE FUNCTION udf.desensitization AS 'com.sfz.Desensitization' USING JAR 'hdfs:///lib/hive_udf/desensitization.jar';
删除命令为DROP FUNCTION IF EXISTS udf.desensitization;
如果需要全局生效,目前来看需要重启hive,否则只对当前客户端有效。
hive之UDF函数编程详解
UDF的定义
- UDF(User-Defined Functions)即是用户定义的hive函数。hive自带的函数并不能完全满足业务需求,这时就需要我们自定义函数了
UDF的分类
- UDF:one to one,进来一个出去一个,row mapping。是row级别操作,如:upper、substr函数
- UDAF:many to one,进来多个出去一个,row mapping。是row级别操作,如sum/min。
- UDTF:one to many ,进来一个出去多个。如alteral view与explode
-
这三类中,我们只对UDF类的函数进行改写
pom文件配置
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.wsk.bigdata</groupId> <artifactId>g6-hadoop</artifactId> <version>1.0</version> <name>g6-hadoop</name> <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <hadoop.version>2.6.0-cdh5.7.0</hadoop.version> <hive.version>1.1.0-cdh5.7.0</hive.version> </properties> <!--添加CDH的仓库--> <repositories> <repository> <id>nexus-aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </repository> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> </repository> </repositories> <dependencies> <!--添加Hadoop的依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <!--添加hive依赖--> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>${hive.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.4</version> <configuration> <source>1.7</source> <target>1.7</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
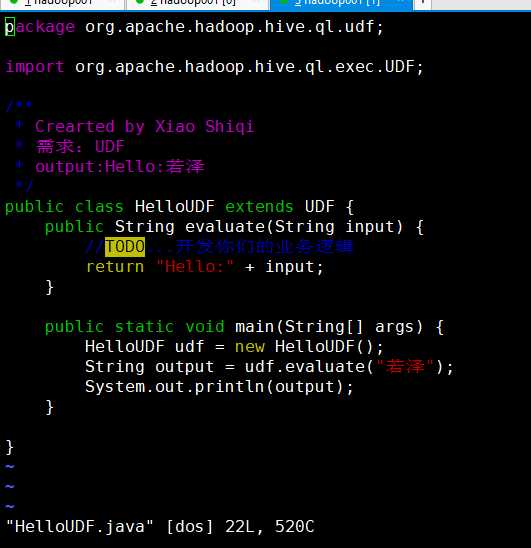
UDF函数编写
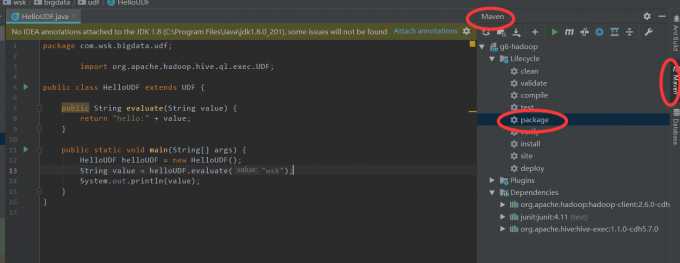
打jar包
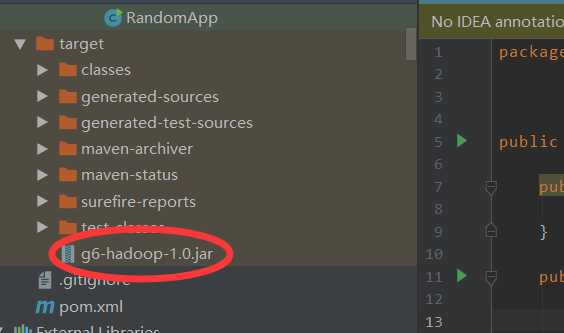
上传jar包
[[email protected] lib]$ rz [[email protected] lib]$ ll g6-hadoop-1.0.jar -rw-r--r--. 1 hadoop hadoop 11447 Apr 19 2019 g6-hadoop-1.0.jar
- 注意:如果jar包是上传到$HIVE_HOME/lib/目录以下,就不需要执行add命令了
添加jar包到hive
- 语法:add jar +jar包所在的目录/jar包名字
hive> add jar /home/hadoop/data/hive/g6-hadoop-1.0.jar;
在hive中创建UDF函数
-
创建临时函数 -----只对当前黑窗口有效
- 语法:
CREATE TEMPORARY FUNCTION function_name AS class_name;
function_name函数名
*******class_name 类路径,包名+类名********* 这里就是你写的UDF函数的第一行的package后边的东西然后在加个点加个类的名字

实例:
hive>CREATE TEMPORARY FUNCTION HelloUDF AS ‘org.apache.hadoop.hive.ql.udf.HelloUDF‘; OK Time taken: 0.485 seconds hive> hive> show functions; 【查看可以看到HelloUDF】
hive>select HelloUDF(‘17‘); OK Hello:17 #检查mysql中的元数据,因为是临时函数,故元数据中并没有相关的信息 mysql> select * from funcs; Empty set (0.11 sec)
删除临时函数 :
- 语法:DROP TEMPORARY FUNCTION [IF EXISTS] function_name;
测试
hive> DROP TEMPORARY FUNCTION IF EXISTS HelloUDF; OK Time taken: 0.003 seconds hive> select HelloUDF(‘17‘); FAILED: SemanticException [Error 10011]: Line 1:7 Invalid function ‘HelloUDF‘ ##其实不删除也无所谓,重新开一个窗口即可
CREATE TEMPORARY FUNCTION function_name AS class_name USING JAR path; function_name函数名 class_name 类路径, 包名+类名 path jar包hdfs路径
将jar上传到指定目录
[[email protected] hive-1.1.0-cdh5.7.0]$ hadoop fs -mkdir /lib [[email protected] hive-1.1.0-cdh5.7.0]$ hadoop fs -put /home/hadoop/data/hive/hive_UDF.jar /lib/ [[email protected] ~]$ hadoop fs -mkdir /lib [[email protected] ~]$ hadoop fs -ls /lib [[email protected] ~]$ hadoop fs -put ~/lib/g6-hadoop-1.0.jar /lib/ 把本地的jar上传到HDFS的/lib/目录下 [[email protected] ~]$ hadoop fs -ls /lib
创建永久生效的UDF函数
CREATE FUNCTION HelloUDF AS ‘org.apache.hadoop.hive.ql.udf.HelloUDF‘ USING JAR ‘hdfs://hadoop001:9000/lib/g6-hadoop-1.0.jar‘; #测试 hive> select HelloUDF("17") ; OK hello:17
检查mysql中的元数据,测试函数的信息已经注册到了元数据中
mysql> select * from funcs; +---------+------------------------------+-------------+-------+------------+-----------+------------+------------+ | FUNC_ID | CLASS_NAME | CREATE_TIME | DB_ID | FUNC_NAME | FUNC_TYPE | OWNER_NAME | OWNER_TYPE | +---------+------------------------------+-------------+-------+------------+-----------+------------+------------+ | 1 |org.apache.hadoop.hive.ql.udf.HelloUDF | 1555263915 | 6 | HelloUDF | 1 | NULL | USER | +---------+------------------------------+-------------+-------+------------+-----------+------------+------------+
- 创建的永久函数可以在任何一个窗口使用,重新启动函数也照样可以使用
官网参考地址:LanguageManual UDF
以上是关于hive之udf函数的使用的主要内容,如果未能解决你的问题,请参考以下文章