ConcurrentHashMap是如何保证线程安全的
Posted JasonGaoH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap是如何保证线程安全的相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap是如何保证线程安全的
之前分析过HashMap的一些实现细节,关于HashMap你需要知道的一些细节, 今天我们从源码角度来看看ConcurrentHashMap是如何实现线程安全的,其实网上这类文章分析特别多,秉着”纸上得来终觉浅,绝知此事要躬行“的原则,我们尝试自己去分析下,希望这样对于ConcurrentHashMap有一个更深刻的理解。
为什么说HashMap线程不安全,而ConcurrentHashMap就线程安全
其实ConcurrentHashMap在android开发中使用的场景并不多,但是ConcurrentHashMap为了支持多线程并发这些优秀的设计却是最值得我们学习的地方,往往”ConcurrentHashMap是如何实现线程安全“这类问题却是面试官比较喜欢问的问题。
首先,我们尝试用代码模拟下HashMap在多线程场景下会不安全,如果把这个场景替换成ConcurrentHashMap会不会有问题。
因为不同于其他的线程同步问题,想模拟出一种场景来表明HashMap是线程不安全的稍微有点麻烦,可能是hash散列有关,在数据量较小的情况下,计算出来的hashCode是不太容易产生碰撞的,网上很多文章都是尝试从源码角度来分析HashMap可能会导致的线程安全问题。
我们来看下下面这段代码,构造一百个线程每个线程都先是往HashMap中put一个数据,然后再将这个数据remove掉,理论上如果没有线程安全问题的话,我们的每个线程拿到的HashMap的size应该都是0.
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class HashMapTest
public static void main(String[] args)
Map<String, String> map = new HashMap<String, String>();
for (int i = 0; i < 100; i++)
TestThread testThread = new TestThread(map, "线程名字:" + i);
testThread.start();
class TestThread extends Thread
public Map<String, String> map;
public String name;
public TestThread(Map<String, String> map, String name)
this.map = map;
this.name = name;
public void run()
int i = (int)Math.random() * 100;
map.put("键" + i, "值" + i);
map.remove("键" + i);
System.out.println(name + " 当前时间:" + i + " size = " + map.size());
输出结果如下所示,由于输出量太大,中间删除了部分重复的输出,我们发现打印出的数量是不准确的。
线程名字:0 当前时间:0 size = -1
线程名字:3 当前时间:0 size = -1
线程名字:5 当前时间:0 size = -1
线程名字:7 当前时间:0 size = -1
线程名字:6 当前时间:0 size = -1
线程名字:4 当前时间:0 size = 0
线程名字:9 当前时间:0 size = -1
线程名字:2 当前时间:0 size = -1
线程名字:1 当前时间:0 size = -1
线程名字:10 当前时间:0 size = -1
线程名字:11 当前时间:0 size = -1
线程名字:8 当前时间:0 size = -1
线程名字:12 当前时间:0 size = -1
线程名字:13 当前时间:0 size = -1
...
线程名字:90 当前时间:0 size = -1
线程名字:91 当前时间:0 size = -1
线程名字:92 当前时间:0 size = -1
线程名字:93 当前时间:0 size = -1
线程名字:94 当前时间:0 size = -1
线程名字:95 当前时间:0 size = -1
线程名字:96 当前时间:0 size = -1
线程名字:97 当前时间:0 size = -1
线程名字:98 当前时间:0 size = -1
线程名字:99 当前时间:0 size = -1
那我们如果把这里的HashMap换成ConcurrentHashMap来试试看看效果如何。
public class HashMapTest
public static void main(String[] args)
Map<String, String> map = new ConcurrentHashMap<String, String>();
for (int i = 0; i < 100; i++)
TestThread testThread = new TestThread(map, "线程名字:" + i);
testThread.start();
输出如下,同样中间也省略了很多重复的打印,我们发现这个时候所有的打印的map的size都是0,从而也验证了ConcurrentHashMap是线程安全的。
线程名字:0 当前时间:0 size = 0
线程名字:7 当前时间:0 size = 0
线程名字:3 当前时间:0 size = 0
线程名字:9 当前时间:0 size = 0
线程名字:6 当前时间:0 size = 0
线程名字:2 当前时间:0 size = 0
线程名字:1 当前时间:0 size = 0
线程名字:5 当前时间:0 size = 0
线程名字:4 当前时间:0 size = 0
线程名字:11 当前时间:0 size = 0
线程名字:10 当前时间:0 size = 0
线程名字:8 当前时间:0 size = 0
...
线程名字:91 当前时间:0 size = 0
线程名字:92 当前时间:0 size = 0
线程名字:93 当前时间:0 size = 0
线程名字:94 当前时间:0 size = 0
线程名字:95 当前时间:0 size = 0
线程名字:96 当前时间:0 size = 0
线程名字:97 当前时间:0 size = 0
线程名字:98 当前时间:0 size = 0
线程名字:99 当前时间:0 size = 0
其实列举上面这个例子只是为了从一个角度来展示下为什么说HashMap线程不安全,而ConcurrentHashMap则是线程安全的,鉴于HashMap线程安全例子比较难列举出来,所有才通过打印size这个角度来模拟了下。
-----------------------------------------------更新分隔线----------------------------------------------
评论区中指出了上面程序设计的错误,感谢。我看了上面随机数生成的地方,是有点问题。于是改了后,发现运行结果变得不一样了,是我之前这个地方程序设计的问题,再次感谢评论区大佬们指出问题。
修改后的代码如下:
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
public class HashMapTest
public static void main(String[] args)
Map<String, String> map = new HashMap<String, String>();
// Map<String, String> map = new ConcurrentHashMap<String, String>();
for (int i = 0; i < 100; i++)
TestThread testThread = new TestThread(map, "线程名字:" + i);
testThread.start();
class TestThread extends Thread
public Map<String, String> map;
public String name;
private Random random = new Random();
public TestThread(Map<String, String> map, String name)
this.map = map;
this.name = name;
public void run()
int i = random.nextInt(1000);
System.out.println("i: " + i);
map.put("键" + i, "值" + i);
map.remove("键" + i);
System.out.println(name + " 当前时间:" + i + " size = " + map.size());
随即数之前生成的一直是零,是有问题的,这里换成random.nextInt来生成了。这段程序不管使用HashMap还是ConcurrentHashMap打印出的size都是0,所有从这个角度来判断是否线程安全是不太合适的。这里没有直接删掉这部分,也是想给读者朋友们一个提示。
另外,我想到了另一种方法来验证HashMap是线程不安全,而ConcurrentHashMap是线程不安全的。
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class HashMapTest2
public static void main(String[] args)
Map<String, String> map = new HashMap<String, String>();
// Map<String, String> map = new ConcurrentHashMap<String, String>();
for (int i = 0; i < 10; i++)
MyThread testThread = new MyThread(map, "线程名字:" + i);
testThread.start();
//等待所有线程都结束
while(Thread.activeCount() > 1)
Thread.yield();
System.out.println(map.size());
class MyThread extends Thread
public Map<String, String> map;
public String name;
public MyThread(Map<String, String> map, String name)
this.map = map;
this.name = name;
public void run()
for(int i =0;i<1000;i++)
map.put(i + name, i + name);
我们构造10个线程,每个线程分别往map中put 1000个数据,为了保证每个数据的key不一样,我们将i+ 线程名字来作为map 的key,这样,如果所有的线程都累加完的话,我们预期的map的size应该是10 * 1000 = 10000。
使用HashMap,程序运行,结果如下:
9930
然后再使用ConcurrentHashMap,运行程序,结果如下:
10000
我们发现不管运行几次,HashMap的size都是小于10000的,而ConcurrentHashMap的size都是10000。从这个角度也证明了ConcurrentHashMap是线程安全的,而HashMap则是线程不安全的。
HashMap在多线程put的时候,当产生hash碰撞的时候,会导致丢失数据,因为要put的两个值hash相同,如果这个对于hash桶的位置个数小于8,那么应该是以链表的形式存储,由于没有做通过,后面put的元素可能会直接覆盖之前那个线程put的数据,这样就导致了数据丢失。
分隔线以内都是后续补充,主要为了纠正之前的错误,方便读者查看,再次感谢指出程序的问题。
-----------------------------------------------更新分隔线----------------------------------------------
这篇文章深入解读HashMap线程安全性问题就详细介绍了HashMap可能会出现线程安全问题。
文章主要讲了两个可能会出现线程不安全地方,一个是多线程的put可能导致元素的丢失,另一个是put和get并发时,可能导致get为null,但是也仅是在源码层面分析了下,因为这中场景想要完全用代码展示出来是稍微有点麻烦的。
接下来我们来看看ConcurrentHashMap是如何做到线程安全的。
JDK8的ConcurrentHashMap文档提炼
- ConcurrentHashMap支持检索的完全并发和更新的高预期并发性,这里的说法很有意思检索支持完全并发,更新则支持高预期并发性,因为它的检索操作是没有加锁的,实际上检索也没有必要加锁。
- 实际上ConcurrentHashMap和Hashtable在不考虑实现细节来说,这两者完全是可以互相操作的,Hashtable在get,put,remove等这些方法中全部加入了synchronized,这样的问题是能够实现线程安全,但是缺点是性能太差,几乎所有的操作都加锁的,但是ConcurrentHashMap的检测操作却是没有加锁的。
- ConcurrentHashMap检索操作(包括get)通常不会阻塞,因此可能与更新操作(包括put和remove)重叠。
- ConcurrentHashMap跟Hashtable类似但不同于HashMap,它不可以存放空值,key和value都不可以为null。
印象中一直以为ConcurrentHashMap是基于Segment分段锁来实现的,之前没仔细看过源码,一直有这么个错误的认识。ConcurrentHashMap是基于Segment分段锁来实现的,这句话也不能说不对,加个前提条件就是正确的了,ConcurrentHashMap从JDK1.5开始随java.util.concurrent包一起引入JDK中,在JDK8以前,ConcurrentHashMap都是基于Segment分段锁来实现的,在JDK8以后,就换成synchronized和CAS这套实现机制了。
JDK1.8中的ConcurrentHashMap中仍然存在Segment这个类,而这个类的声明则是为了兼容之前的版本序列化而存在的。
/**
* Stripped-down version of helper class used in previous version,
* declared for the sake of serialization compatibility.
*/
static class Segment<K,V> extends ReentrantLock implements Serializable
private static final long serialVersionUID = 2249069246763182397L;
final float loadFactor;
Segment(float lf) this.loadFactor = lf;
JDK1.8中的ConcurrentHashMap不再使用Segment分段锁,而是以table数组的头结点作为synchronized的锁。和JDK1.8中的HashMap类似,对于hashCode相同的时候,在Node节点的数量少于8个时,这时的Node存储结构是链表形式,时间复杂度为O(N),当Node节点的个数超过8个时,则会转换为红黑树,此时访问的时间复杂度为O(long(N))。
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
数据结构图如下所示:
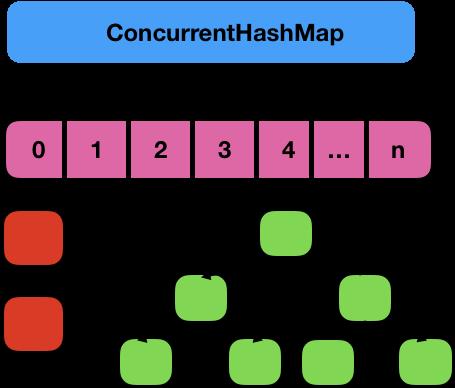
其实ConcurrentHashMap保证线程安全主要有三个地方。
- 一、使用volatile保证当Node中的值变化时对于其他线程是可见的
- 二、使用table数组的头结点作为synchronized的锁来保证写操作的安全
- 三、当头结点为null时,使用CAS操作来保证数据能正确的写入。
使用volatile
可以看到,Node中的val和next都被volatile关键字修饰。
volatile的happens-before规则:对一个volatile变量的写一定可见(happens-before)于随后对它的读。
也就是说,我们改动val的值或者next的值对于其他线程是可见的,因为volatile关键字,会在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据。
static class Node<K,V> implements Map.Entry<K,V>
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
另外,ConcurrentHashMap提供类似tabAt来读取Table数组中的元素,这里是以volatile读的方式读取table数组中的元素,主要通过Unsafe这个类来实现的,保证其他线程改变了这个数组中的值的情况下,在当前线程get的时候能拿到。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
而与之对应的,是setTabAt,这里是以volatile写的方式往数组写入元素,这样能保证修改后能对其他线程可见。
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
我们来看下ConcurrentHashMap的putVal方法:
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent)
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;)
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//当头结点为null,则通过casTabAt方式写入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null)
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
else if ((fh = f.hash) == MOVED)
//正在扩容
tab = helpTransfer(tab, f);
else
V oldVal = null;
//头结点不为null,使用synchronized加锁
synchronized (f)
if (tabAt(tab, i) == f)
if (fh >= 0)
//此时hash桶是链表结构
binCount = 1;
for (Node<K,V> e = f;; ++binCount)
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek))))
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
Node<K,V> pred = e;
if ((e = e.next) == null)
pred.next = new Node<K,V>(hash, key,
value, null);
break;
else if (f instanceof TreeBin)
//此时是红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null)
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
if (binCount != 0)
//当链表结构大于等于8,则将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
addCount(1L, binCount);
return null;
在putVal方法重要的地方都加了注释,可以帮助理解,现在我们一步一步来看putVal方法。
使用CAS
当有一个新的值需要put到ConcurrentHashMap中时,首先会遍历ConcurrentHashMap的table数组,然后根据key的hashCode来定位到需要将这个value放到数组的哪个位置。
tabAt(tab, i = (n - 1) & hash))就是定位到这个数组的位置,如果当前这个位置的Node为null,则通过CAS方式的方法写入。所谓的CAS,即即compareAndSwap,执行CAS操作的时候,将内存位置的值与预期原值比较,如果相匹配,那么处理器会自动将该位置值更新为新值,否则,处理器不做任何操作。
这里就是调用casTabAt方法来实现的。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v)
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
casTabAt同样是通过调用Unsafe类来实现的,调用Unsafe的compareAndSwapObject来实现,其实如果仔细去追踪这条线路,会发现其实最终调用的是cmpxchg这个CPU指令来实现的,这是一个CPU的原子指令,能保证数据的一致性问题。
使用synchronized
当头结点不为null时,则使用该头结点加锁,这样就能多线程去put hashCode相同的时候不会出现数据丢失的问题。synchronized是互斥锁,有且只有一个线程能够拿到这个锁,从而保证了put操作是线程安全的。
下面是ConcurrentHashMap的put操作的示意图,图片来自于ConcurrentHashMap源码分析(JDK8)get/put/remove方法分析。

参考文章
从ConcurrentHashMap的演进看Java多线程核心技术
ConcurrentHashMap源码分析(JDK8)get/put/remove方 以上是关于ConcurrentHashMap是如何保证线程安全的的主要内容,如果未能解决你的问题,请参考以下文章