:分类和回归
Posted Sonhhxg_柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:分类和回归相关的知识,希望对你有一定的参考价值。
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
.对文档执行的最常见的机器学习任务是分类和回归。从确定临床记录的保险计费代码(分类)到预测社交媒体帖子的受欢迎程度(回归),大多数文档级机器学习任务都属于这些类别之一,而分类是两者中更为常见的一种。
在开始机器学习任务时,尝试手动标记一些文档是非常有用的,即使数据集中已经有标签。这将帮助您了解可以在您的任务中使用文档语言的哪些内容。标记时,请注意您要查找的内容。例如,特定的单词或短语、文档的某些部分,甚至文档长度都是有用的。
在关于分类和回归的章节中,您可能期望大部分讨论是关于不同的建模算法。使用 NLP,大部分工作都在特征化中。假设您已经创建了良好的特征,许多改进模型的通用技术将适用于 NLP。我们将讨论调优建模算法的一些注意事项,但本章的大部分内容都集中在如何对文本进行特征化以进行分类和回归。
我们将讨论词袋方法、基于正则表达式的特征和特征选择。在此之后,我们将讨论在文本数据上构建模型时如何进行迭代。
让我们加载并处理 mini_newsgroups 数据,这样我们就可以看到如何创建这些特征的示例。
import os
import re
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pyspark.sql.types import *
from pyspark.sql.functions import expr
from pyspark.sql import Row
from pyspark.ml import Pipeline
import sparknlp
from sparknlp import DocumentAssembler, Finisher
from sparknlp.annotator import *
%matplotlib inline
spark = sparknlp.start()我们将构建一个分类器来识别文档来自哪个新闻组。新闻组在文档的标题中被提及,所以让我们删除这些以更具运动性。
HEADER_PTN = re.compile(r'^[a-zA-Z-]+:.*')
def remove_header(path_text_pair):
path, text = path_text_pair
lines = text.split('\\n')
line_iterator = iter(lines)
while HEADER_PTN.match(next(line_iterator)) is not None:
pass
return path, '\\n'.join(line_iterator)path = os.path.join('data', 'mini_newsgroups', '*')
texts = spark.sparkContext.wholeTextFiles(path).map(remove_header)
schema = StructType([
StructField('path', StringType()),
StructField('text', StringType()),
])
texts = spark.createDataFrame(texts, schema=schema) \\
.withColumn('newsgroup', expr('split(path, "/")[7]')) \\
.persist()texts.groupBy('newsgroup').count().collect()[Row(newsgroup='comp.windows.x', count=100),
Row(newsgroup='misc.forsale', count=100),
Row(newsgroup='rec.sport.hockey', count=100),
Row(newsgroup='rec.sport.baseball', count=100),
Row(newsgroup='talk.politics.guns', count=100),
Row(newsgroup='comp.os.ms-windows.misc', count=100),
Row(newsgroup='talk.politics.misc', count=100),
Row(newsgroup='comp.sys.ibm.pc.hardware', count=100),
Row(newsgroup='comp.graphics', count=100),
Row(newsgroup='soc.religion.christian', count=100),
Row(newsgroup='comp.sys.mac.hardware', count=100),
Row(newsgroup='talk.religion.misc', count=100),
Row(newsgroup='talk.politics.mideast', count=100),
Row(newsgroup='rec.motorcycles', count=100),
Row(newsgroup='rec.autos', count=100),
Row(newsgroup='alt.atheism', count=100),
Row(newsgroup='sci.electronics', count=100),
Row(newsgroup='sci.space', count=100),
Row(newsgroup='sci.med', count=100),
Row(newsgroup='sci.crypt', count=100)]print(texts.first()['path'])
print(texts.first()['newsgroup'])
print(texts.first()['text'])file:/home/.../spark-nlp-book/data/mini_newsgroups/...
rec.motorcycles
Can anyone recommend a good place for reasonably priced bike paint
jobs, preferably but not essentially in the London area.
Thanks
Lisa Rowlands
--
Alex Technologies Ltd CP House
97-107 Uxbridge Road
Tel: +44 (0)81 566 2307 Ealing
Fax: +44 (0)81 566 2308 LONDON
email: lisa@alex.com W5 5LTassembler = DocumentAssembler()\\
.setInputCol('text')\\
.setOutputCol('document')
sentence = SentenceDetector() \\
.setInputCols(["document"]) \\
.setOutputCol("sentences")
tokenizer = Tokenizer()\\
.setInputCols(['sentences'])\\
.setOutputCol('token')
lemmatizer = LemmatizerModel.pretrained()\\
.setInputCols(['token'])\\
.setOutputCol('lemma')
normalizer = Normalizer()\\
.setCleanupPatterns([
'[^a-zA-Z.-]+',
'^[^a-zA-Z]+',
'[^a-zA-Z]+$',
])\\
.setInputCols(['lemma'])\\
.setOutputCol('normalized')\\
.setLowercase(True)
finisher = Finisher()\\
.setInputCols(['normalized'])\\
.setOutputCols(['normalized'])\\
.setOutputAsArray(True)
pipeline = Pipeline().setStages([
assembler, sentence, tokenizer,
lemmatizer, normalizer, finisher
]).fit(texts)
processed = pipeline.transform(texts).persist()
print(processed.count()) # number of documents
2000词袋特征
在上一章中,我们讨论了使用 TF.IDF 构建的文档向量。这些特征是文档分类和回归中最常用的特征。然而,使用这样的功能有一些困难。根据您的语料库的大小,您可能有超过十万个特征,而任何示例都只有几百到几千个非零特征。这可以通过创建特征矩阵的稀疏表示来处理,其中省略 0 值。然而,并不是所有的训练算法都支持稀疏矩阵。这就是我们在第 5 章中讨论的词汇缩减技术变得重要的地方。
如果您已经减少了词汇量,但仍需要减少特征数量,那么是时候考虑使用受限词汇了。例如,在处理临床数据时,最好将您的词汇限制为医学术语。这可以通过使用统一医学语言服务 (UMLS) 等外部资源来完成。如果您在其他领域工作,请考虑整理一个词表。精选词汇表可以成为您功能的过滤器。不过,这样的词汇有一些优点和缺点。它们不受数据集中信息的影响,因此不会导致过度拟合。相反,可能有些功能不太可能出现在真正有用的通用策划列表中。这就是为什么在模型构建的迭代过程中标记一些示例很重要的原因。如果您已经过滤了您的词汇表,您可以对错误分类的示例进行抽样以添加到您的词汇表中。
这种手动特征选择的扩展是试图将部分词汇表组合成更小的特征集。这可以通过正则表达式来完成。
让我们看一个 Spark 中的词袋示例(见表 7-1)。
from pyspark.ml.feature import CountVectorizer, IDF
count_vectorizer = CountVectorizer(
inputCol='normalized', outputCol='tf', minDF=10)
idf = IDF(inputCol='tf', outputCol='tfidf', minDocFreq=10)
bow_pipeline = Pipeline(stages=[count_vectorizer, idf])
bow_pipeline = bow_pipeline.fit(processed)
bows = bow_pipeline.transform(processed)bows.limit(5).toPandas()[['tf', 'tfidf']]| tf | tfidf | |
|---|---|---|
| 0 | (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, ... | (0.07307056787648658, 0.0, 0.0, 0.0, 0.1507415... |
| 1 | (21.0, 10.0, 16.0, 2.0, 9.0, 9.0, 28.0, 12.0, ... | (1.5344819254062183, 0.915192734288196, 2.1079... |
| 2 | (1.0, 5.0, 2.0, 2.0, 4.0, 0.0, 3.0, 1.0, 0.0, ... | (0.07307056787648658, 0.457596367144098, 0.263... |
| 3 | (4.0, 5.0, 4.0, 2.0, 6.0, 2.0, 3.0, 1.0, 0.0, ... | (0.2922822715059463, 0.457596367144098, 0.5269... |
| 4 | (6.0, 2.0, 2.0, 0.0, 2.0, 1.0, 3.0, 3.0, 2.0, ... | (0.4384234072589195, 0.1830385468576392, 0.263... |
正则表达式功能
假设您正在尝试将短篇小说分为流派。对于这个例子,我们的语料库中只有三种类型:科幻、奇幻和恐怖。我们可以创建特定的特征来帮助我们进行分类。如果我们有单词列表,我们可以将它们组合成一个特征。有几种方法可以做到这一点。
- 使用词袋特征并创建一个特征,该特征是用 sum 或 max 聚合特征的 TF.IDF 值的结果。
- 通过创建新令牌来创建新功能。您可以预处理文档,将标签添加到包含词汇表中的单词的任何文档。然后,您可以计算此标签的 TF.IDF。
我们可以添加其他类型的功能。例如,科幻小说中经常提到稀有和虚构的矿物——例如,二锂(星际迷航中的真实物质和虚构的矿物)和金刚金属(漫威漫画中的虚构合金)。我们可以创建一个正则表达式来查找这些矿物的共同结尾。
(lith|ant|an)ium
发现这些特征中的哪些将帮助我们进行分类是数据科学家和领域专家应该合作的任务。数据科学家可以找到可能对模型有帮助的特征。领域专家可以识别哪些特征实际上与问题相关,哪些与目标变量虚假相关。
这些功能对于模型的第一个版本很有用,但它们有一些严重的缺点。如果您希望在另一种语言的文本上构建类似的模型,您很可能无法重用正则表达式功能。
让我们使用RegexMatcherSpark NLP 在文档文本中查找匹配项。
%%writefile scifi_rules.tsv
\\w+(lith|ant|an)ium,mineral
(alien|cosmic|quantum|dimension(al)?),space_wordregex_matcher = RegexMatcher() \\
.setOutputCol("regex") \\
.setExternalRules('./scifi_rules.tsv', ',')因为RegexMatcher作品在原始文本上,所以不需要其他阶段。通常,您会提取正则表达式匹配以及其他基于文本的特征。结果如表7-2所示。
regex_finisher = Finisher()\\
.setInputCols(['regex'])\\
.setOutputCols(['regex'])\\
.setOutputAsArray(True)
regex_rule_pipeline = Pipeline().setStages([
assembler, regex_matcher, regex_finisher
]).fit(texts)
regex_matches = regex_rule_pipeline.transform(texts)regex_matches.orderBy(expr('size(regex)').desc())\\
.limit(5).toPandas()[['newsgroup', 'regex']]| newsgroup | regex | |
|---|---|---|
| 0 | talk.politics.guns | [alien, alien, alien, alien, alien, alien, alien] |
| 1 | comp.graphics | [dimensional, dimension, dimensional, dimension] |
| 2 | sci.space | [cosmic, cosmic, cosmic] |
| 3 | sci.med | [dimensional, alien, dimensional] |
| 4 | sci.space | [quantum, quantum, cosmic] |
有几种方法可以将这些转换为特征。您可以创建二进制特征——换句话说,如果任何正则表达式匹配,则值为 1。您还可以使用匹配数作为特征。
现在我们已经介绍了两个最常见的经典 NLP 特征,让我们来谈谈我们如何减少维度。
特征选择
一旦你确定了一组特征,通常是词袋和正则表达式的混合,你可能会发现你有一个非常高维的特征空间。这在很大程度上取决于语料库中使用的语言类型。在技术含量高的语料库中,特征多于示例的情况并不少见。如果您查看分布,您会发现它们是按幂律分布的。
我们可以使用 SparkStopWordsRemover删除像“the”和“of”这样的词,就像我们在第 6 章中讨论的那样。
from pyspark.ml.feature import StopWordsRemover
sw_remover = StopWordsRemover() \\
.setInputCol("normalized") \\
.setOutputCol("filtered") \\
.setStopWords(StopWordsRemover.loadDefaultStopWords("english"))最后,我们把它变成一个管道。在管道中包含文本处理步骤很重要。这将让您与 NLP 参数一起探索机器学习模型的超参数。NLP 预处理变得越复杂,这一点就越重要。我们还将包括我们的词袋阶段。
count_vectorizer = CountVectorizer(inputCol='filtered',
outputCol='tf', minDF=10)
idf = IDF(inputCol='tf', outputCol='tfidf', minDocFreq=10)
pipeline = Pipeline() \\
.setStages([
assembler,
sentence,
tokenizer,
lemmatizer,
normalizer,
finisher,
sw_remover,
count_vectorizer,
idf
]) \\
.fit(texts)现在我们已经构建了管道,我们可以转换我们的文本。
features = pipeline.transform(texts).persist()
features.printSchema()root
|-- path: string (nullable = true)
|-- text: string (nullable = true)
|-- newsgroup: string (nullable = true)
|-- normalized: array (nullable = true)
| |-- element: string (containsNull = true)
|-- filtered: array (nullable = true)
| |-- element: string (containsNull = true)
|-- tf: vector (nullable = true)
|-- tfidf: vector (nullable = true)在 Spark MLlib 中,特征存储在单个向量值列中。这比为每个特性创建一个列要高效得多,但它确实使与数据的交互更加复杂。为了解决这个问题,我们将把数据提取到 pandasDataFrame中。我们可以这样做,因为我们的数据很小并且可以放入内存中。这不适用于更大的数据集。
现在我们有了一个合适的CountVectorizerModel,我们可以看看它找到的词汇表。单词按文档频率排序。
pipeline.stages[DocumentAssembler_e20c28c687ac,
SentenceDetector_3ac13139f56d,
REGEX_TOKENIZER_543fbefa0fa3,
LEMMATIZER_c62ad8f355f9,
NORMALIZER_0177fbaed772,
Finisher_4074048574cf,
StopWordsRemover_2e502cd57d60,
CountVectorizer_0d555c85604c,
IDF_a94ab221196d]cv_model = pipeline.stages[-2]
len(cv_model.vocabulary)3033
这是一个适度的词汇量。当我们读到本书的第三部分时,我们会看到更大的尺寸。
让我们按文档频率来看看我们的前 10 个单词。
cv_model.vocabulary[:10]['write', 'one', 'use', 'get', 'article', 'say', 'know', 'x', 'make', 'dont']
让我们看一下平均词频的分布。我们将创建一个平均词频的直方图,如图 7-1 所示。
tf = features.select('tf').toPandas()
tf = tf['tf'].apply(lambda sv: sv.toArray())
mean_tf = pd.Series(tf.mean(), index=cv_model.vocabulary)
plt.figure(figsize=(12, 8))
mean_tf.hist(bins=10)
plt.show()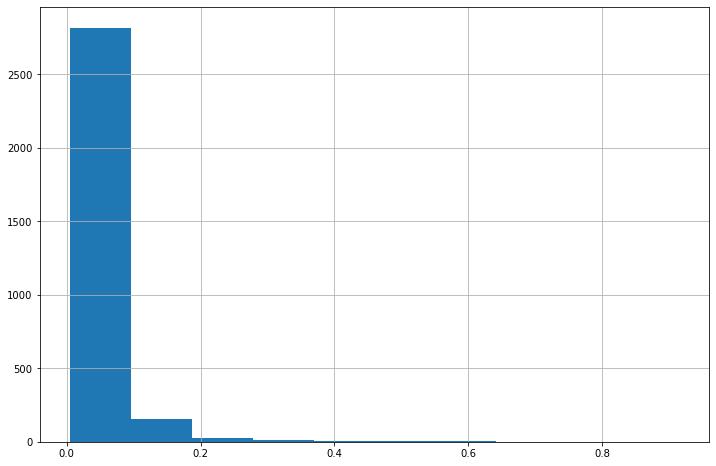
图 7-1。语料库中每个词的平均词频直方图
我们可以看到这看起来像一个幂律分布。让我们绘制等级的对数与平均词频的对数,如图 7-2 所示。
plt.figure(figsize=(12, 8))
ranks = np.arange(len(mean_tf)) + 1
plt.plot(np.log10(ranks), np.log10(mean_tf.values))
plt.show()这通常是您在词汇分布中看到的。请注意,即使我们删除了最常见的词,并删除了非常罕见的词,通过设置minDF为 10,我们仍然具有预期的分布。
既然我们有了我们的特征,并且确信我们没有扰乱预期的单词分布,那么我们如何减少特征的数量呢?我们可以尝试将更多单词添加到我们的停用词列表中,或者我们可以增加我们minDF以删除更多稀有词。但是,让我们考虑一种更有原则的方法来解决这个问题。许多用于减少特征数量的众所周知的技术(例如查看每个特征的单变量预测能力)不适用于文本。词袋特征的优势在于它们的相互作用。因此,我们可能会丢弃那些本身并不强大但组合起来可能非常强大的功能。高维意味着我们无法探索所有可能的交互。所以,我们能做些什么?
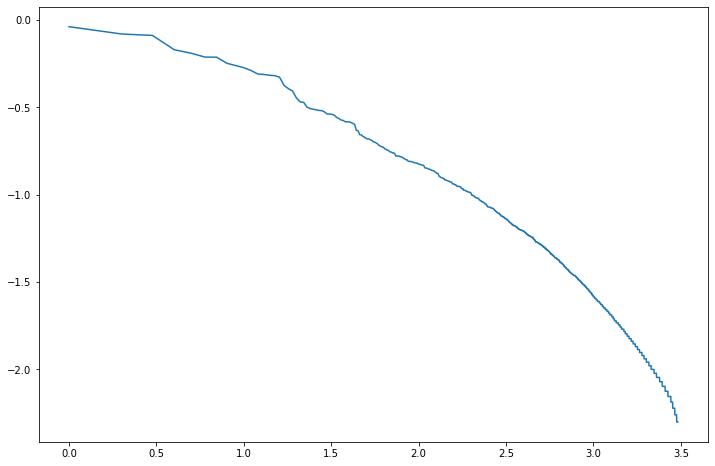
图 7-2。排名对数(按平均词频)与平均词频对数的关系图
我们可以使用领域专家选择的对问题很重要的单词或短语字典。我们还可以构建基于树的模型,例如随机森林,并使用特征重要性来选择特征子集。这是可行的,因为随机森林模型是非线性的,并且可以发现交互作用——因此,这个词只有在组合中才重要。
我们将在第10章和第11章中研究其他降维技术。现在,让我们讨论使用 TF.IDF 特征对文本进行建模。
Modeling
将文本转换为特征向量后,事情开始看起来更像是一个常规的机器学习问题,但有一些例外。以下是要记住的最重要的事情:
- 有很多稀疏特征。
- 这些功能不是相互独立的。
- 由于失去了单词的顺序,我们已经失去了大部分语言。
幸运的是,这些都不是亮点。即使算法做出与这些事实相违背的假设,它仍然是有效的。我们将在这里讨论一些流行的算法,我们将在本章的练习中尝试这些算法。
朴素贝叶斯
朴素贝叶斯得名于它的朴素假设,即所有特征都是相互独立的。然后它估计以特征值为条件的类的概率。我们知道,从语言学和常识来看,单词并不是相互独立的。但朴素贝叶斯实际上是一种流行的文本分类基线。朴素贝叶斯如此受欢迎的原因是它产生的概率类似于 TF.IDF:
磷(Cl一个ss|学期1,学期2,...,学期ñ)=磷(Cl一个ss)∏一世=1ñ磷(学期一世|Cl一个ss)∑ķ=1ķ磷(Cl一个ssķ)∏一世=1ñ磷(学期一世|Cl一个ssķ)如果一个术语在所有类中都是通用的,那么它对这个值的贡献不大。但是,如果一个术语对于特定类中的文档是唯一的,它将是朴素贝叶斯的一个重要特征。这类似于 IDF 如何降低许多文档中常见单词的重要性。
线性模型
线性回归和逻辑回归等线性模型假设它们的预测变量相互独立。我们可以解决这个问题的一种方法是查看交互。但是,这在我们的情况下不起作用,因为我们有一个非常高的维度空间。如果您计划使用线性模型,您可能希望在特征化上投入更多精力。具体来说,您将希望更积极地减少功能数量。
决策/回归树
决策树和回归树可以学习非线性关系,它们没有任何独立性假设。它们可能会受到稀疏特征的不利影响。具有较少固有熵的变量,如相对不常见的词,不太可能被信息增益等分裂标准挑选出来进行分裂。这意味着任何非稀疏特征都将优于稀疏特征。此外,具有较高方差的词(通常意味着较高的文档频率)可能比文档频率较低的词更受青睐。例如,可以通过更积极地删除停用词来缓解这种情况。如果您使用的是随机森林或梯度增强树,则可以减轻前面提到的一些困难。
基于树的模型的另一个重要方面是能够轻松解释模型的输出。因为您可以看到正在选择哪些特征,所以您可以轻松检查学习算法是否正在制作合理的模型。
深度学习算法
神经网络非常擅长学习复杂的函数,但它们确实需要大量数据。所需数据随着参数数量的增加而迅速增加。如果您使用词袋方法,则第一层的参数数量将是您的词汇量乘以第一个隐藏层的大小。这已经相当大了。这意味着您要花费大量时间来学习单词的中间表示——这也可能导致过度拟合。使用词嵌入通常是个好主意,我们将在第 11 章讨论,这样你的分类或回归模型需要学习的参数要少得多。
在进行 NLP 或机器学习时,请始终牢记您希望从数据中得到什么。训练和部署深度学习模型通常比经典机器学习模型更复杂。总是先尝试最简单的事情。
迭代
任何分类或回归项目中最重要的部分是迭代周期,如图 7-3 所示。
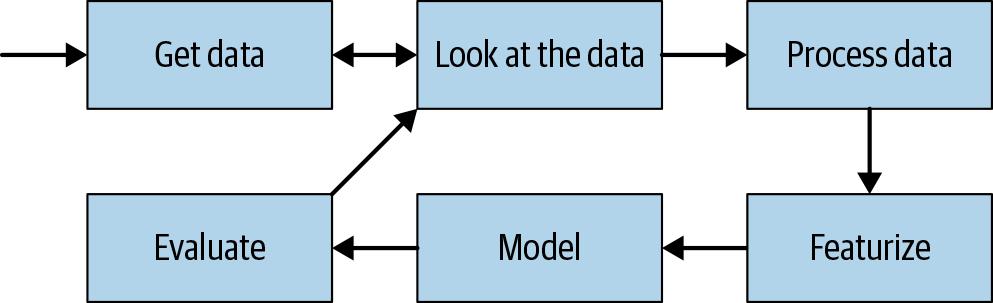
图 7-3。如何迭代 NLP 分类和回归问题
如果您过去做过机器学习,那么大部分内容看起来都很熟悉。在处理文本数据时,我们应该牢记一些不同之处,因此让我们回顾一下以下步骤。
-
获取数据。
这通常是此类项目中最耗时的部分。希望您使用的数据得到良好维护和记录。无论是否,您都必须验证数据。
-
看看数据。
无论是使用结构化数据还是非结构化数据,我们通常都需要做一些工作来准备数据以进行建模。对于结构化数据,这通常意味着删除无效值或规范化字段。对于文本数据,这有点模糊。可能存在规定最小或最大长度的业务逻辑。或者,您可能希望根据元数据删除某些文档。在业务逻辑之外,您应该检查文档的编码并将它们转换为通用编码(例如,UTF-8)。
您还想创建一个保留集。即使您使用的是交叉验证形式而不是训练测试拆分,保持完全不变的保留也很重要。很容易过拟合文本数据。
-
处理数据。
无论是使用结构化数据还是非结构化数据,我们通常都需要做一些工作来准备数据以进行建模。在结构化数据中,这通常意味着删除无效值或规范化字段。对于文本数据,这有点模糊。可能存在规定最小或最大长度的业务逻辑。或者,您可能希望根据元数据删除某些文档。在业务逻辑之外,您应该检查文档的编码并将它们转换为通用编码(例如,UTF-8)。
您还想创建一个保留集。即使您使用的是交叉验证形式而不是训练测试拆分,保持完全不变的保留也很重要。通常很容易过度拟合文本数据。
-
特色化。
现在您已经处理并准备好数据,您可以创建特征向量。创建特征后,您应该对特征进行一些基本的探索性分析。您可以像我们之前一样查看词汇分布。你也可以为此使用主题模型,我们将在第 10 章中介绍。主题模型可以为您提供决定如何创建模型的见解,并且作为附带好处,将帮助您发现错误。
由于 NLP 特征化通常比结构化数据的特征化更复杂,因此您希望将特征化阶段与建模放在同一管道中。这将有助于优化模型超参数以及特征化参数。
-
模型。
您需要决定要使用哪种算法。与一般机器学习任务一样,您需要设置基线。为基于文本的分类和回归问题设置基线的流行模型是逻辑回归、朴素贝叶斯和决策树。一旦你有了你的特征,并且你决定了一个算法,你就可以训练你的模型了。
-
评估。
查看数据对于了解模型发生的情况很重要,但查看指标同样重要。您应该使用交叉验证或在专用验证集上进行迭代。必须保存您的保留集,直到您认为您已准备好投入生产。
-
审查。
尽可能多地关注您的管道,这一点很重要。
- 审查您的代码:如果有人不熟悉数据,则可能很难审查数据处理代码。如果您找不到有上下文来审查您的代码的人,那么拥有完整的文档就变得很重要。
- 查看您的数据:您可以与主题专家一起查看您的数据。此外,请考虑与完全不熟悉数据的人一起进行审查。
- 检查您的功能:您创建的功能应该有意义。如果是这种情况,您应该与领域专家一起查看这些功能。如果特征太抽象而无法轻易地与领域联系起来,那么与有构建类似模型经验的人一起回顾特征背后的理论可能是值得的。
- 查看您的模型:在进行建模项目时,很容易迷失在细节中。重要的是要检查您选择算法的理由以及输出。
- 检查你的指标:与任何机器学习项目一样,你应该能够清楚地解释你的指标——尤其是你做出业务决策的指标。如果您很难找到一个好的指标,那么您可能没有解决问题的最佳方法。有时,将分类问题更好地描述为排名问题。
- 查看您的文档:您应该确保您的整个管道都有很好的文档记录。如果您想具有可重复性,这是必要的。
现在您已经验证了基线模型,是时候做出决定了。基线是否足以用于生产?如果有,请寄出。否则,是时候再次查看数据了。现在你已经建立了你的周期,你可以开始改进你的指标。
现在我们有了一个构建基于文本的分类器和回归器的框架。没有一种单一的技术可以更轻松地处理稀疏的高维文本。您应该依靠领域专家来帮助您做出选择。本章涵盖了一般的想法和规则;我们将在本书的第三部分中研究更具体的应用。词袋方法的一个问题是我们失去了语言的一个重要部分——句法。我们可以用 N-gram 来捕捉其中的一部分,但是如果我们想对文本中的片段进行分类会发生什么呢?在下一章中,我们将探讨如何构建序列模型。
练习
让我们构建一个分类器来预测文档所属的新闻组。我们将从本章之前构建的管道开始,我们将使用朴素贝叶斯分类器。
使用Spark MLlib 指南作为尝试新事物的参考。
train, test = texts.randomSplit([0.8, 0.2], seed=123)stopwords = set(StopWordsRemover.loadDefaultStopWords("english"))sw_remover = StopWordsRemover() \\
.setInputCol("normalized") \\
.setOutputCol("filtered") \\
.setStopWords(list(stopwords))
count_vectorizer = CountVectorizer(inputCol='filtered',
outputCol='tf', minDF=10)
idf = IDF(inputCol='tf', outputCol='tfidf', minDocFreq=10)
text_processing_pipeline = Pipeline(stages=[
assembler,
sentence,
tokenizer,
lemmatizer,
normalizer,
finisher,
sw_remover,
count_vectorizer,
idf
])
from pyspark.ml.feature import IndexToString, StringIndexer
from pyspark.ml.classification import *
from pyspark.ml.tuning import *
from pyspark.ml.evaluation import *label_indexer = StringIndexer(inputCol='newsgroup', outputCol='label').fit(texts)
naive_bayes = NaiveBayes(featuresCol='tfidf')
prediction_deindexer = IndexToString(inputCol='prediction', outputCol='pred_newsgroup',
labels=label_indexer.labels)
pipeline = Pipeline(stages=[
text_processing_pipeline, label_indexer, naive_bayes, prediction_deindexer
])model = pipeline.fit(train)train_predicted = model.transform(train)
test_predicted = model.transform(test)我们使用的是 F1-score,它是准确率和召回率的调和平均值。
evaluator = MulticlassClassificationEvaluator(metricName='f1')
print('f1', evaluator.evaluate(train_predicted))f1 0.946056760284357
print('f1', evaluator.evaluate(test_predicted))f1 0.6508170558829952
看起来我们在训练数据上的表现比在测试数据上的表现要好得多——也许我们过度拟合了。进行实验,看看您在测试集上的表现如何。
以上是关于:分类和回归的主要内容,如果未能解决你的问题,请参考以下文章