python-Unet计算机视觉~舌象舌头图片分割~机器学习
Posted Socialphobia_FOGO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python-Unet计算机视觉~舌象舌头图片分割~机器学习相关的知识,希望对你有一定的参考价值。
1 简介
舌体分割是舌诊检测的基础,唯有做到准确分割舌体才能保证后续训练以及预测的准确性。此部分真正的任务是在用户上传的图像中准确寻找到属于舌头的像素点。舌体分割属于生物医学图像分割领域。分割效果如下:

2 数据集介绍
舌象数据集包含舌象原图以及分割完成的二元图,共979*2张,示例图片如下:

数据集+源代码获取途径:
闲鱼链接
【闲鱼】https://m.tb.cn/h.UWW2yew?tk=1sgL2yMIPPl CZ0001 「我在闲鱼发布了【图像数据集与分割代码】」
点击链接直接打开
3 模型介绍
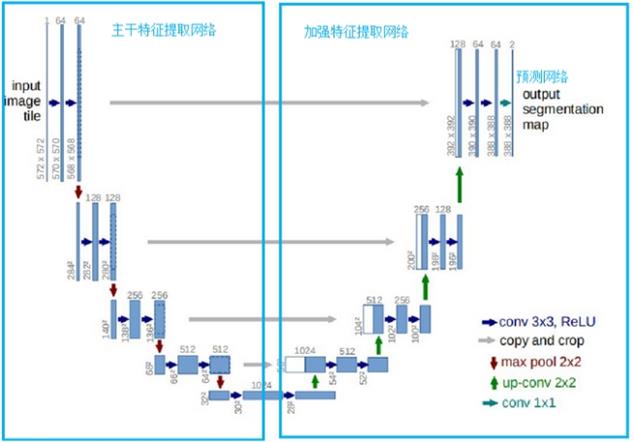
U-Net是一个优秀的语义分割模型,在中e诊中U-Net共三部分,分别是主干特征提取部分、加强特征提取部分、预测部分。利用主干特征提取部分获得5个初步有效的特征层,之后通过加强特征提取部分对上述获取到的5个有效特征层进行上采样并进行特征融合。最终获得了一个结合所有特征的有效特征层,并利用最终有效特征层对像素点进行预测,找到属于舌体的像素点。具体操作详情如下图所示:

进行标注后利用PyTorch框架构建U-Net模型抓取舌象图像特征,预测舌象图像标签。为对模型进行评价,在训练中计算每次循环的平均损失率。最终每张图的损失了约为2%左右。具体的平均损失率变化如下图:
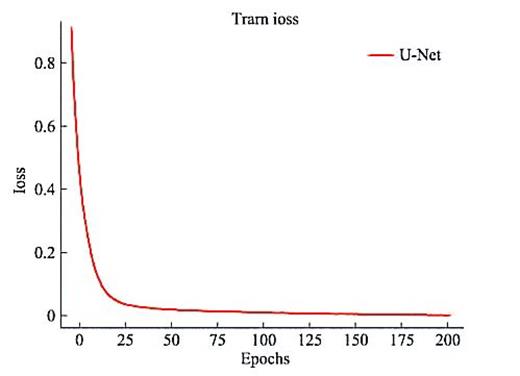
训练共历时4天,共979张标记图像,最终平均预测损失率约为2%。模型预测,即舌体分割的效果非常理想,在此展示当损失率为40%与损失率为2%时的分割结果示例,示例如下图所示:
(1)损失率为40%时分割结果图

(2)损失率为2%时分割结果图

根据模型预测结果对属于舌体的像素点进行匹配提取,将不属于舌体的部分以墨绿色进行填充,最终的舌体分割效果图如下:

4 代码实现细节
4.1 相关文件介绍

notedata文件夹中有分割标注图片、ordata文件夹中有原始图片、params文件夹中有训练模型文件、result文件夹中有测试样例图片、train_image文件夹中有训练过程图片。
4.2 utils.py
工具类:由于数据集中各个图片的大小是不一样的,为了保障后续工作可以顺利进行,这里应该定义一个工具类将图片可以等比例缩放至256*256(可以改看自己需求)。
from PIL import Image
def keep_image_size_open(path, size=(256, 256)):
img = Image.open(path)
temp = max(img.size)
mask = Image.new('RGB', (temp, temp), (0,0,0))
mask.paste(img, (0,0))
mask = mask.resize(size)
return mask
4.3 data.py
这里主要是将数据集中标签图片与原图进行匹配合并~具体步骤代码注释中有详解!
import os
from torch.utils.data import Dataset
from utils import *
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor()
])
class MyDataset(Dataset):
def __init__(self, path): #拿到标签文件夹中图片的名字
self.path = path
self.name = os.listdir(os.path.join(path, 'notedata'))
def __len__(self): #计算标签文件中文件名的数量
return len(self.name)
def __getitem__(self, index): #将标签文件夹中的文件名在原图文件夹中进行匹配(由于标签是png的格式而原图是jpg所以需要进行一个转化)
segment_name = self.name[index] #XX.png
segment_path = os.path.join(self.path, 'notedata', segment_name)
image_path = os.path.join(self.path, 'ordata', segment_name.replace('png', 'jpg')) #png与jpg进行转化
segment_image = keep_image_size_open(segment_path) #等比例缩放
image = keep_image_size_open(image_path) #等比例缩放
return transform(image), transform(segment_image)
if __name__ == "__main__":
data = MyDataset("E:/ITEM_TIME/project/UNET/")
print(data[0][0].shape)
print(data[0][1].shape)

可见数据集已经规整!
4.4 net.py
Unet网络的编写!
from torch import nn
import torch
from torch.nn import functional as F
class Conv_Block(nn.Module): #卷积
def __init__(self, in_channel, out_channel):
super(Conv_Block, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, 1, 1, padding_mode='reflect',
bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout2d(0.3),
nn.LeakyReLU(),
nn.Conv2d(out_channel, out_channel, 3, 1, 1, padding_mode='reflect',
bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout2d(0.3),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSample(nn.Module): #下采样
def __init__(self, channel):
super(DownSample, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(channel, channel,3,2,1,padding_mode='reflect',
bias=False),
nn.BatchNorm2d(channel),
nn.LeakyReLU()
)
def forward(self,x):
return self.layer(x)
class UpSample(nn.Module): #上采样(最邻近插值法)
def __init__(self, channel):
super(UpSample, self).__init__()
self.layer = nn.Conv2d(channel, channel//2,1,1)
def forward(self,x, feature_map):
up = F.interpolate(x, scale_factor=2, mode='nearest')
out = self.layer(up)
return torch.cat((out,feature_map),dim=1)
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.c1=Conv_Block(3,64)
self.d1=DownSample(64)
self.c2=Conv_Block(64, 128)
self.d2=DownSample(128)
self.c3=Conv_Block(128,256)
self.d3=DownSample(256)
self.c4=Conv_Block(256,512)
self.d4=DownSample(512)
self.c5=Conv_Block(512,1024)
self.u1=UpSample(1024)
self.c6=Conv_Block(1024,512)
self.u2=UpSample(512)
self.c7=Conv_Block(512,256)
self.u3=UpSample(256)
self.c8=Conv_Block(256,128)
self.u4=UpSample(128)
self.c9=Conv_Block(128,64)
self.out = nn.Conv2d(64,3,3,1,1)
self.Th = nn.Sigmoid()
def forward(self,x):
R1 = self.c1(x)
R2 = self.c2(self.d1(R1))
R3 = self.c3(self.d2(R2))
R4 = self.c4(self.d3(R3))
R5 = self.c5(self.d4(R4))
O1 = self.c6(self.u1(R5,R4))
O2 = self.c7(self.u2(O1,R3))
O3 = self.c8(self.u3(O2,R2))
O4 = self.c9(self.u4(O3,R1))
return self.Th(self.out(O4))
if __name__ == "__main__":
x = torch.randn(2, 3, 256, 256)
net = UNet()
print(net(x).shape)

结果匹配说明没问题~
4.5 train.py
训练代码~
from torch import nn
from torch import optim
import torch
from data import *
from net import *
from torchvision.utils import save_image
from torch.utils.data import DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weight_path = 'params/unet.pth'
data_path = 'E:/ITEM_TIME/project/UNET/'
save_path = 'train_image'
if __name__ == "__main__":
dic = []###
data_loader = DataLoader(MyDataset(data_path),batch_size=3,shuffle=True) #batch_size用3/4都可以看电脑性能
net = UNet().to(device)
if os.path.exists(weight_path):
net.load_state_dict(torch.load(weight_path))
print('success load weight')
else:
print('not success load weight')
opt = optim.Adam(net.parameters())
loss_fun = nn.BCELoss()
epoch = 1
while True:
avg = []###
for i, (image,segment_image) in enumerate(data_loader):
image,segment_image = image.to(device),segment_image.to(device)
out_image = net(image)
train_loss = loss_fun(out_image, segment_image)
opt.zero_grad()
train_loss.backward()
opt.step()
if i%5 == 0:
print('--train_loss===>>'.format(epoch,i,train_loss.item()))
if i%50 == 0:
torch.save(net.state_dict(), weight_path)
#为方便看效果将原图、标签图、训练图进行拼接
_image = image[0]
_segment_image = segment_image[0]
_out_image = out_image[0]
img = torch.stack([_image,_segment_image,_out_image],dim=0)
save_image(img, f'save_path/i.jpg')
avg.append(float(train_loss.item()))###
loss_avg = sum(avg)/len(avg)
dic.append(loss_avg)
epoch += 1
print(dic)

可见代码成功运行~上面的损失率是在训练4天后的效果,刚开始肯定很大很差,需要有耐心!
4.6 test.py
测试代码,对图片进行智能分割~
from net import *
from utils import keep_image_size_open
import os
import torch
from data import *
from torchvision.utils import save_image
from PIL import Image
import numpy as np
net = UNet().cpu() #或者放在cuda上
weights = 'params/unet.pth' #导入网络
if os.path.exists(weights):
net.load_state_dict(torch.load(weights))
print('success')
else:
print('no loading')
_input = 'xxxx.jpg' #导入测试图片
img = keep_image_size_open(_input)
img_data = transform(img)
print(img_data.shape)
img_data = torch.unsqueeze(img_data, dim=0)
print(img_data)
out = net(img_data)
save_image(out, 'result/result.jpg')
save_image(img_data, 'result/orininal.jpg')
print(out)
#E:\\ITEM_TIME\\UNET\\ordata\\4292.jpg
img_after = Image.open(r"result\\result.jpg")
img_before = Image.open(r"result\\orininal.jpg")
#img.show()
img_after_array = np.array(img_after)#把图像转成数组格式img = np.asarray(image)
img_before_array = np.array(img_before)
shape_after = img_after_array.shape
shape_before = img_before_array.shape
print(shape_after,shape_before)
#将分隔好的图片进行对应像素点还原,即将黑白分隔图转化为有颜色的提取图
if shape_after == shape_before:
height = shape_after[0]
width = shape_after[1]
dst = np.zeros((height,width,3))
for h in range(0,height):
for w in range (0,width):
(b1,g1,r1) = img_after_array[h,w]
(b2,g2,r2) = img_before_array[h,w]
if (b1, g1, r1) <= (90, 90, 90):
img_before_array[h, w] = (144,238,144)
dst[h,w] = img_before_array[h,w]
img2 = Image.fromarray(np.uint8(dst))
img2.save(r"result\\blend.png","png")
else:
print("失败!")
结果展示:
(1)原图(orininal.jpg):

(2)模型分割图(result.jpg):

(3)对应像素点还原图(blend.png):就是将(2)中的图白色的部分用原图像素点填充,黑色的部分用绿色填充

至此,舌体分割完成!
以上是关于python-Unet计算机视觉~舌象舌头图片分割~机器学习的主要内容,如果未能解决你的问题,请参考以下文章