Python机器学习及实践——进阶篇5(模型检验)
Posted Lenskit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python机器学习及实践——进阶篇5(模型检验)相关的知识,希望对你有一定的参考价值。
前面时不时提到模型检验或者交叉验证等词汇,特别是在对不同模型的配置,不同的特征组合,在相同的数据和任务下进行评价的时候。究其原因是因为仅仅使用默认配置的模型与不经处理的数据特征,在大多数任务下是无法得到最佳性能表现的。因此在最终交由测试集进行性能评估之前,我们希望可以利用手头现有的数据对模型进行调优,甚至可以粗略地估计测试结果。
这里需要强调的是,前面所使用的测试数据是由原始数据中采样而来,并且多数知晓测试的正确结果;但是这仅仅是为了学习和模拟的需要。一些初学者经常拿着测试集的正确结果反复调优模型与特征,从而可以发现在测试集上表现最佳的模型配置和特征组合。这是极其错误的行为。
正确的做法是对现有数据进行采样分割:一部分用于模型参数训练,叫做训练集;另一部分数据集合用于调优模型配置和特征选择,并且对未知的测试性能做出估计,叫做开发集或验证集。根据验证流程复杂度的不同,模型检验方式分为留一验证与交叉验证。
留一验证:
留一验证最为简单,就是从任务提供的数据中,随机采样一定比例作为训练集,剩下的“留做”验证。通常,我们取这个比例为7:3,即70%作为训练集,剩下的30%用做模型验证。不过,通过这一验证方法优化的模型性能也不稳定,原因在于对验证集合随机采样的不确定性。因此,这一方法被使用在计算能力较弱,而相对数据规模较大的机器学习发展的早期,这一验证的方法进化成为更加高级的版本:交叉验证。
交叉验证:
交叉验证可以理解为做了多次留一验证的过程。只是需要强调的是,每次检验所使用的验证集之间是互斥的,并且要保证每一条可用数据都被模型验证过。以10折交叉验证为例,如下图所示(图片来自网络):
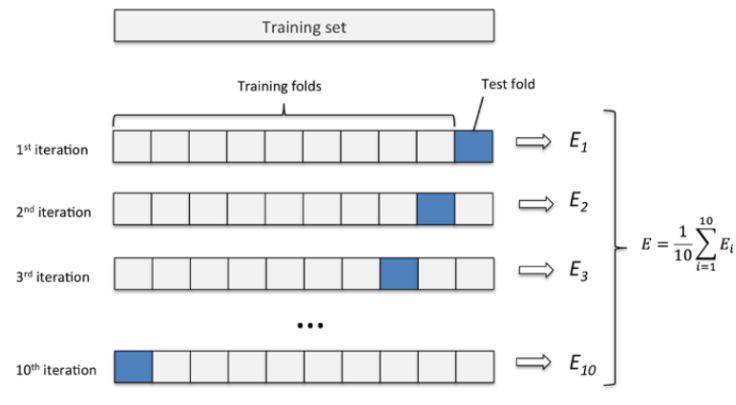
全部可用数据被随机分割为评价数量的10组,每次迭代都选取其中1组数据作为验证集,其他9组作为训练集。
交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现得更加可信。
以上是关于Python机器学习及实践——进阶篇5(模型检验)的主要内容,如果未能解决你的问题,请参考以下文章