sharding-jdbc分库分表规则-单表查询
Posted 那个天真的人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sharding-jdbc分库分表规则-单表查询相关的知识,希望对你有一定的参考价值。
前言
当数据量到达一定数量级的时候,一般都会考虑分库分表。sharding-jdbc是一个开源的客户端分库分表基础类库,以一个jar包的形式提供,基于原生的JDBC驱动进行增强,基本能够无缝整合旧代码,非常的便捷。本小节以一个最简单的单表查询浅析概要流程。
建库建表
| 库 | 表 |
|---|---|
| ds_jdbc_0 | t_order_0 , t_order_1 |
| ds_jdbc_1 | t_order_0 , t_order_1 |
订单表逻辑语名:
CREATE TABLE IF NOT EXISTS t_order (order_id INT NOT NULL, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))
配置
为简单起见,使用基本的jdbc进行操作,最精简的代码如下:
public final class SingleSelect
public static void main(final String[] args) throws SQLException
DataSource dataSource = getOrderShardingDataSource();
printSingleSelect(dataSource);
private static ShardingDataSource getOrderShardingDataSource()
DataSourceRule dataSourceRule = new DataSourceRule(createDataSourceMap());
TableRule orderTableRule = TableRule.builder("t_order").actualTables(Arrays.asList("t_order_0", "t_order_1")).dataSourceRule(dataSourceRule).build();
ShardingRule shardingRule = ShardingRule.builder().dataSourceRule(dataSourceRule).tableRules(Arrays.asList(orderTableRule))
.databaseShardingStrategy(new DatabaseShardingStrategy("user_id", new ModuloDatabaseShardingAlgorithm()))
.tableShardingStrategy(new TableShardingStrategy("order_id", new ModuloTableShardingAlgorithm())).build();
return new ShardingDataSource(shardingRule);
private static void printSingleSelect(final DataSource dataSource) throws SQLException
String sql = "SELECT * FROM t_order where user_id=? and order_id=?";
try (
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql))
preparedStatement.setInt(1, 10);
preparedStatement.setInt(2, 1001);
try (ResultSet rs = preparedStatement.executeQuery())
while (rs.next())
System.out.println(rs.getInt(1));
System.out.println(rs.getInt(2));
System.out.println(rs.getInt(3));
private static DataSource createDataSource(final String dataSourceName)
BasicDataSource result = new BasicDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setUrl(String.format("jdbc:mysql://127.0.0.1:3306/%s", dataSourceName));
result.setUsername("root");
result.setPassword("123456");
return result;
private static Map<String, DataSource> createDataSourceMap()
Map<String, DataSource> result = new HashMap<>(2);
result.put("ds_jdbc_0", createDataSource("ds_jdbc_0"));
result.put("ds_jdbc_1", createDataSource("ds_jdbc_1"));
return result;
分库分表最主要有几个配置:
1. 有多少个数据源
2. 每张表的逻辑表名和所有物理表名
3. 用什么列进行分库以及分库算法
4. 用什么列进行分表以及分表算法
本示例定义了两个数据源: ds_jdbc_0 和 ds_jdbc_1,定义了逻辑表:t_order,以及物理表:t_order_0 和 t_order_0。采用 user_id列进行分库,order_id列进行分表。一切准备就绪,我们的目标是执行如下的语句:
SELECT * FROM t_order where user_id=10 and order_id=1001我们想实现如下的目标:
分库:
user_id % 2 = 0 的数据存储到 ds_jdbc_0 ,为1的数据存储到 ds_jdbc_1
分表:
order_id % 2 = 0 的数据存储到 t_order_0 ,为1的数据存储到 t_order_1
这属于业务的范畴,我们必须清楚告知sharding-jdbc我们的意图,所以要提供分库分表策略类,
看看分库策略类:
public final class ModuloDatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Integer>
@Override
public String doEqualSharding(final Collection<String> dataSourceNames, final ShardingValue<Integer> shardingValue)
for (String each : dataSourceNames)
if (each.endsWith(shardingValue.getValue() % 2 + ""))
return each;
throw new IllegalArgumentException();
@Override
public Collection<String> doInSharding(final Collection<String> dataSourceNames, final ShardingValue<Integer> shardingValue)
return null;
@Override
public Collection<String> doBetweenSharding(final Collection<String> dataSourceNames, final ShardingValue<Integer> shardingValue)
return null;
由于我们使用了 = 号条件进行查询,所以只实现了 doEqualSharding 这个方法。代码非常简单,参数dataSourceNames的值为[ds_jdbc_0 , ds_jdbc_1],而shardingValue在执行的时候可以获取到 user_id=10这个值,在doEqualSharding 中,我们自己根据user_id的值返回路由的库的名称。
接下来看看分表策略类:
public final class ModuloTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Integer>
@Override
public String doEqualSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue)
for (String each : tableNames)
if (each.endsWith(shardingValue.getValue() % 2 + ""))
return each;
throw new UnsupportedOperationException();
@Override
public Collection<String> doInSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue)
return null;
@Override
public Collection<String> doBetweenSharding(final Collection<String> tableNames, final ShardingValue<Integer> shardingValue)
return null;
一样实现了 doEqualSharding这个方法,因为我们的条件中有 order_id=1001,在执行回调时,tableNames的值为[t_order_0 ,t_order_1 ],我们可以决定如何路由到真实的表名。
流程浅析
先来看个基本的流程图:
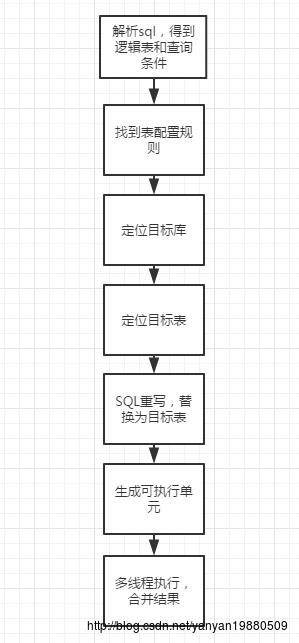
我们再来看看我们的目标sql语句:
SELECT * FROM t_order where user_id=10 and order_id=1001通过sql解析发现有一张逻辑表名称:t_order
发现两个条件: t_order.userId = 10 和 t_order.order_id = 1001
通过 t_order 找到对应的表配置规则 TableRule,这里定义了两个物理表: t_order_0和t_order_1
根据 TableRule找出目标数据源集合
通过TableRule找到DatabaseShardingStrategy,得到分库列:user_id
通过t_order 和 user_id联合为key从条件中查找,找到了t_order.userId = 10,
再结合参数值(10),得到分片值
ShardingValue(logicTableName=t_order, columnName=user_id, value=10),
调用自定义分库策略类(传输[ds_jdbc_0 , ds_jdbc_1],ShardingValue),得到最终的数据源名称集合[ds_jdbc_0]根据TableRule和数据源 [ds_jdbc_0] 找到物理表
通过TableShardingStrategy找到表的分片列: order_id
通过t_order 和 order_id联合为key从条件中查找,找到了order_id=1001,再结合参数值(1001),得到分片值
ShardingValue(logicTableName=t_order, columnName=order_id, value=1001),
调用自定义分表策略类(传输[t_order_0,t_order_1],ShardingValue),得到[ds_jdbc_0]下的最终物理表集合[t_order_1]根据数据源和物理表,得到 DataNode的集合
根据得到的[ds_jdbc_0] 和 [t_order_1],构建 DataNode集合,每一个DataNode表示 xx库.xx表,此示例下得到一个DataNode实体: [ds_jdbc_0].[t_order_1]
根据 DataNode生成TableUnits集合
TableUnit由 逻辑表,物理库,物理表 三个字段组成,
此示例为: t_order 、ds_jdbc_0 、t_order_1SQL重写
构建重写引擎SQLRewriteEngine,根据TableUnits生成对应最终的sql语句执行单元(替换成最终表名),得到执行单元集合(ExecutionUnits),一个执行单元表示在哪个库,执行什么sql语句
ExecutionUnits转换为PreparedStatement,最后又转为PreparedStatementUnit
线程池并发执行PreparedStatementUnit,最后再合并结果返回
多库单表又如何
通过上面的分析,我们已经知道了单库单表的基本查询逻辑,现在把sql简单调整为:
SELECT * FROM t_order where order_id=1001这次,我们发现搜索条件并没有分库键,这时候,引擎并不会调用分库策略类,直接认定目标库为[ds_jdbc_0,ds_jdbc_1],而分表的逻辑是不变的,既然目标库有两个,后面生成的DataNode,TableUnits,PreparedStatementUnit 将是以前数量的两倍,所以这回,引擎最终将会发起多个sql语句的并发执行,并合并最终的结果再返回。
总结
以上基于一个最简单的查询拆解了基本的流程,当然,sql解析的细节还是很复杂的,但不是本文关注的重点,本文主要关注一个简单的sql语句,在sharding-jdbc下是如何达到分库分表的目的的,后续再分析更多的sql语句的执行。
参考
http://shardingjdbc.io/index_zh.html
以上是关于sharding-jdbc分库分表规则-单表查询的主要内容,如果未能解决你的问题,请参考以下文章