spark 的HA模式
Posted 正义飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark 的HA模式相关的知识,希望对你有一定的参考价值。
hadoop,spark,kafka交流群:459898801
1,ssh无密钥登录
1,生产一对公钥和密钥
$ ssh-keygen -t rsa2,拷贝公钥到各个机器上
$ ssh-copy-id hadoop.learn.com3,ssh连接
$ ssh spark.learn.com
$ ssh hadoop.learn.com
$ ssh tachyon.learn.com2,配置zookeeper
1,在spark-env.sh中添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER "
export SPARK_DAEMON_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS -Dspark.deploy.zookeeper.url=spark.learn.com:2181,hadoop.learn.com:2181,tachyon.learn.com:2181" 2,各个参数的意义
| 参数 | 默认值 | 含义 |
|---|---|---|
| spark.deploy.recoveryMode | NONE | 恢复模式(Master重新启动的模式),有三种:1, ZooKeeper, 2, FileSystem, 3 NONE |
| spark.deploy.zookeeper.url | ZooKeeper的Server地址 | |
| spark.deploy.zookeeper.dir | /spark | ZooKeeper 保存集群元数据信息的文件目录,包括Worker,Driver和Application。 |
Master可以在任何时候添加或移除。如果发生故障切换,新的Master将联系所有以前注册的Application和Worker告知Master的改变。
注意:不能将Master定义在conf/spark-env.sh里了,而是直接在Application中定义。涉及的参数是 export SPARK_MASTER_IP,这项不配置或者为空。否则,无法启动多个master。
1,启动spark的HA
1.zookeeper集群已经启动。
bin/zkServer.sh start
bin/zkServer.sh status2.关闭集群后,重新启动spark集群:
sbin/stop-all.sh
sbin/start-all.sh 3.在另一个节点上,启动新的master:
sbin/start-master.sh 4.运行applition
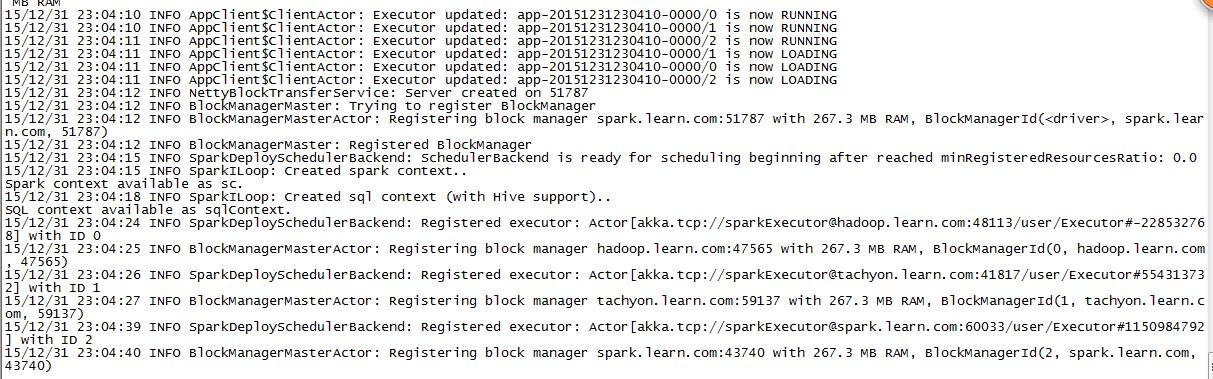
MASTER=spark://spark.learn.com:7077,tachyon.learn.com:7077 bin/spark-shell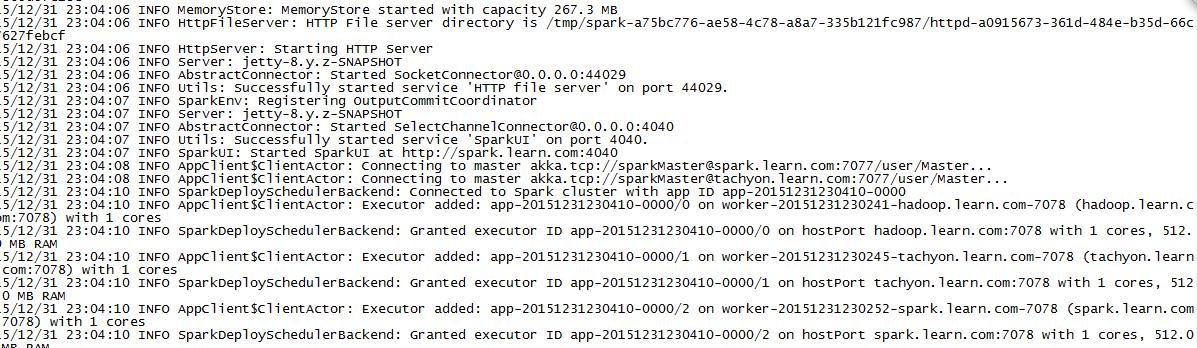


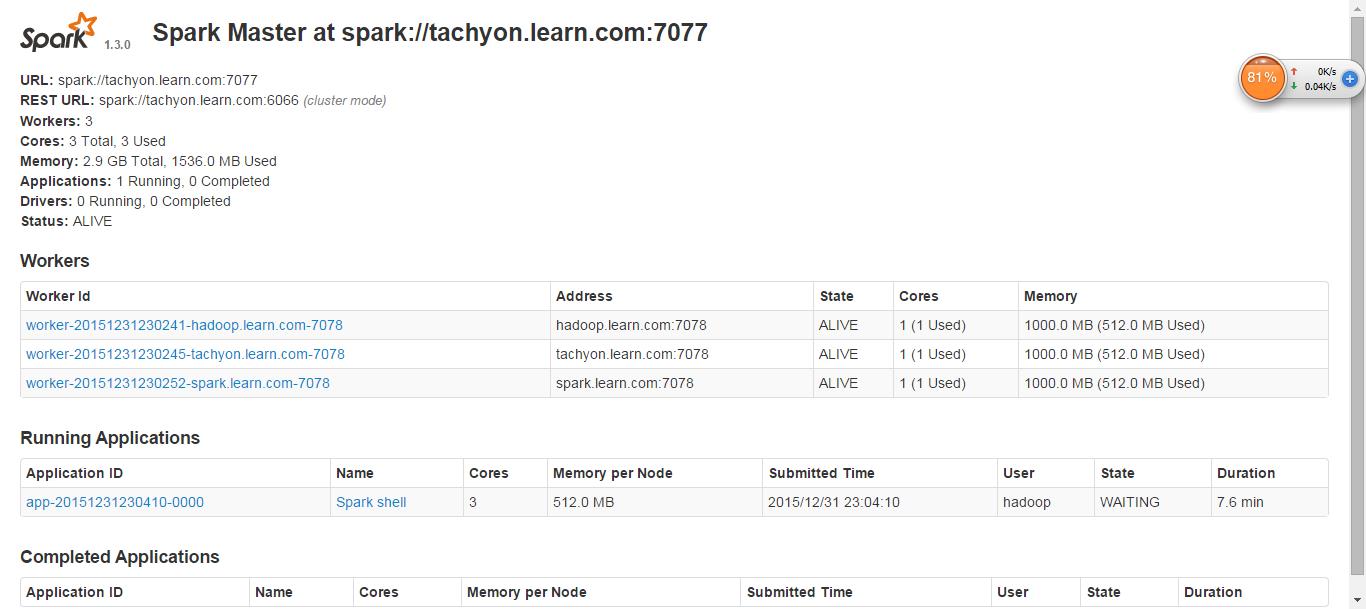
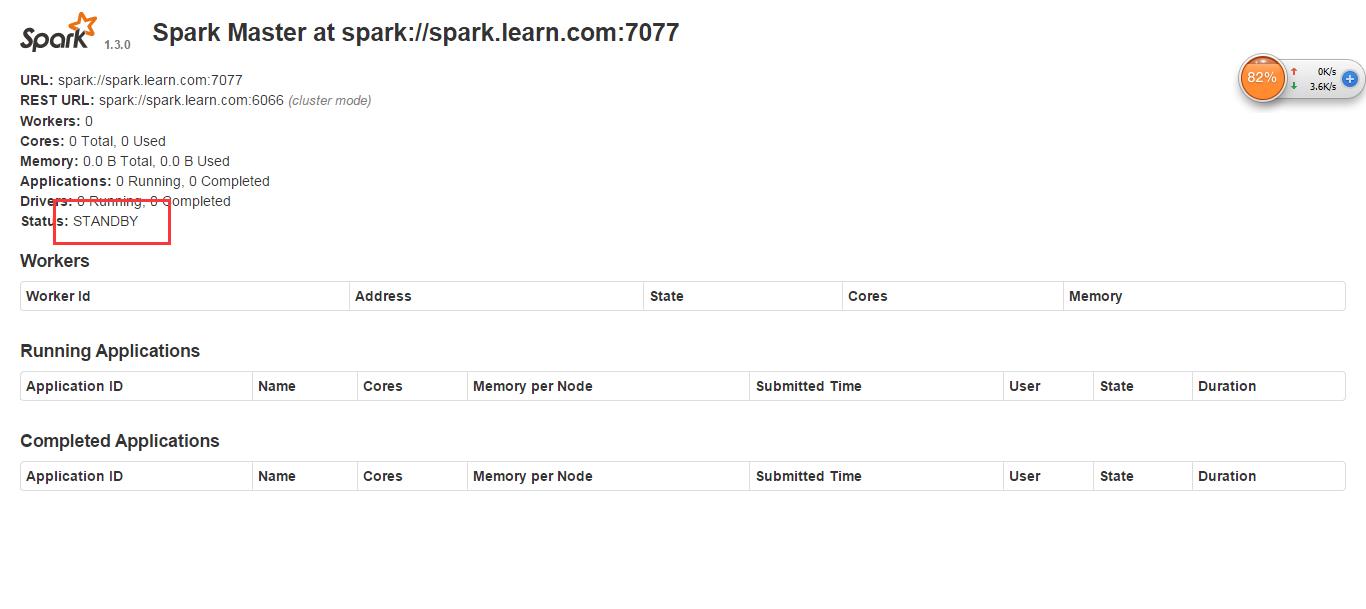
5,kill 掉一个master
kill -9 masterID
以上是关于spark 的HA模式的主要内容,如果未能解决你的问题,请参考以下文章