java架构知识点-大数据与高并发(学习笔记)
Posted cy629584407
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java架构知识点-大数据与高并发(学习笔记)相关的知识,希望对你有一定的参考价值。
大数据与高并发
一、秒杀架构设计 业务介绍 什么是秒杀?通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动 比如说京东秒杀,就是一种定时定量秒杀,在规定的时间内,无论商品是否秒杀完毕,该场次的秒杀活动都会结 束。这种秒杀,对时间不是特别严格,只要下手快点,秒中的概率还是比较大的。 淘宝以前就做过一元抢购,一般都是限量 1 件商品,同时价格低到「令人发齿」,这种秒杀一般都在开始时间 1 到 3 秒内就已经抢光了,参与这个秒杀一般都是看运气的,不必太强求。


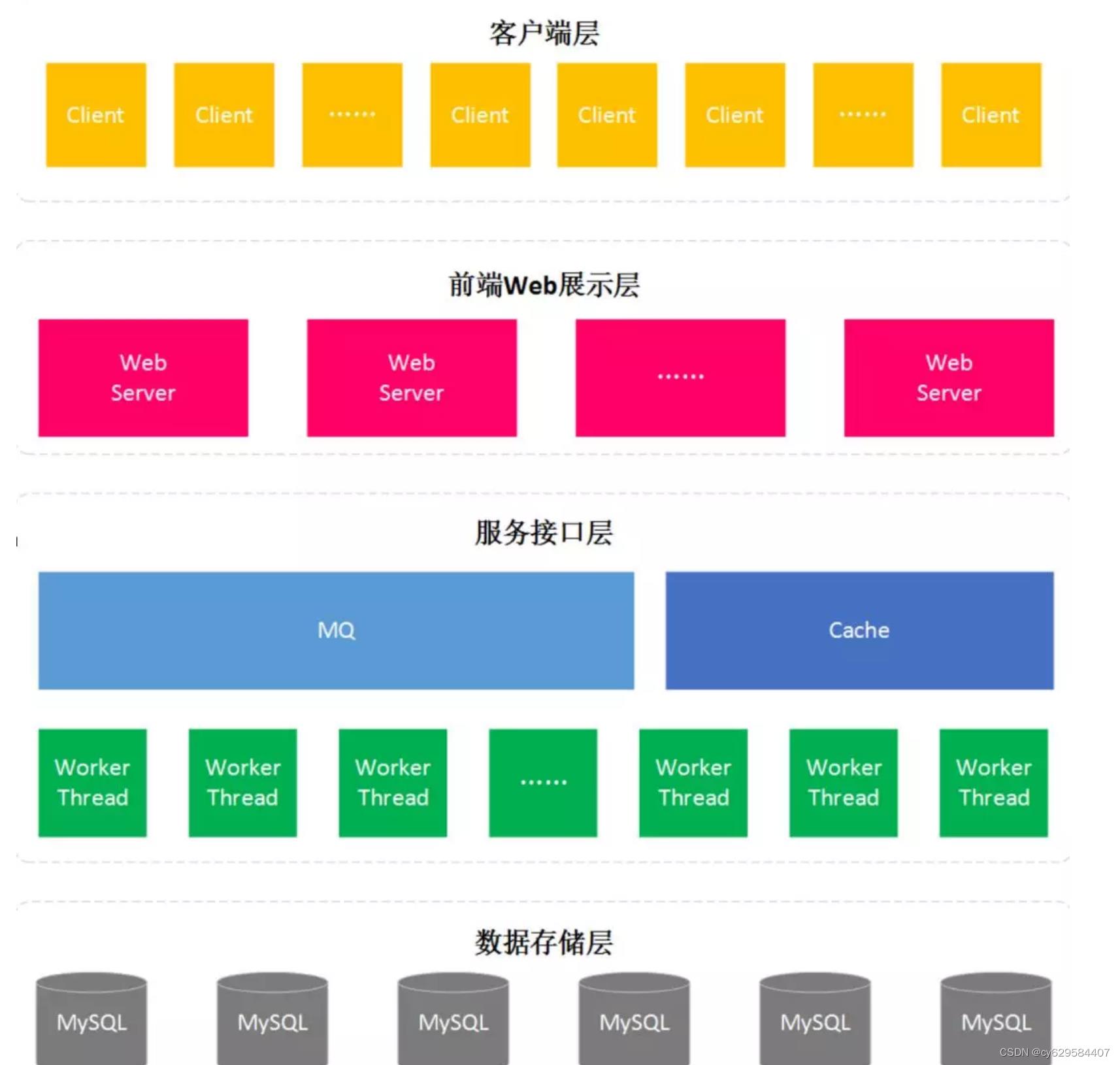
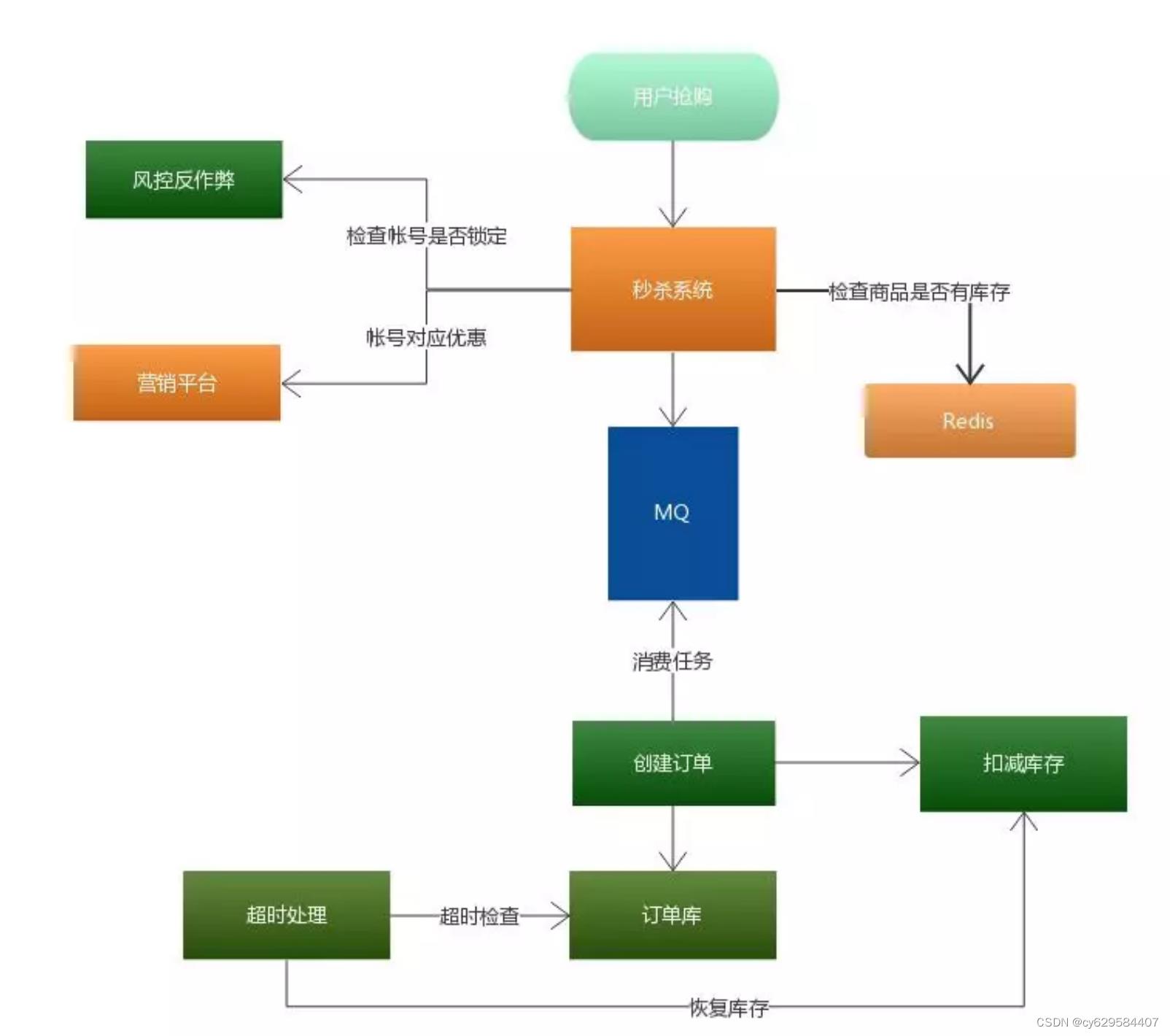 秒杀系统核心在于层层过滤,逐渐递减瞬时访问压力,减少最终对数据库的冲击。通过上面流程图就会发现压力最大的地方在哪里? MQ 排队服务,只要
MQ
排队服务顶住,后面下订单与扣减库存的压力都是自己能控制的,根据数据库的压力,可 以定制化创建订单消费者的数量,避免出现消费者数据量过多,导致数据库压力过大或者直接宕机。 库存服务专门为秒杀的商品提供库存管理,实现提前锁定库存,避免超卖的现象。同时,通过超时处理任务发现已 抢到商品,但未付款的订单,并在规定付款时间后,处理这些订单,将恢复订单商品对应的库存量。
总结
核心思想:层层过滤
尽量将请求拦截在上游,降低下游的压力
充分利用缓存与消息队列,提高请求处理速度以及削峰填谷的作用
二、数据库架构发展历程
秒杀系统核心在于层层过滤,逐渐递减瞬时访问压力,减少最终对数据库的冲击。通过上面流程图就会发现压力最大的地方在哪里? MQ 排队服务,只要
MQ
排队服务顶住,后面下订单与扣减库存的压力都是自己能控制的,根据数据库的压力,可 以定制化创建订单消费者的数量,避免出现消费者数据量过多,导致数据库压力过大或者直接宕机。 库存服务专门为秒杀的商品提供库存管理,实现提前锁定库存,避免超卖的现象。同时,通过超时处理任务发现已 抢到商品,但未付款的订单,并在规定付款时间后,处理这些订单,将恢复订单商品对应的库存量。
总结
核心思想:层层过滤
尽量将请求拦截在上游,降低下游的压力
充分利用缓存与消息队列,提高请求处理速度以及削峰填谷的作用
二、数据库架构发展历程
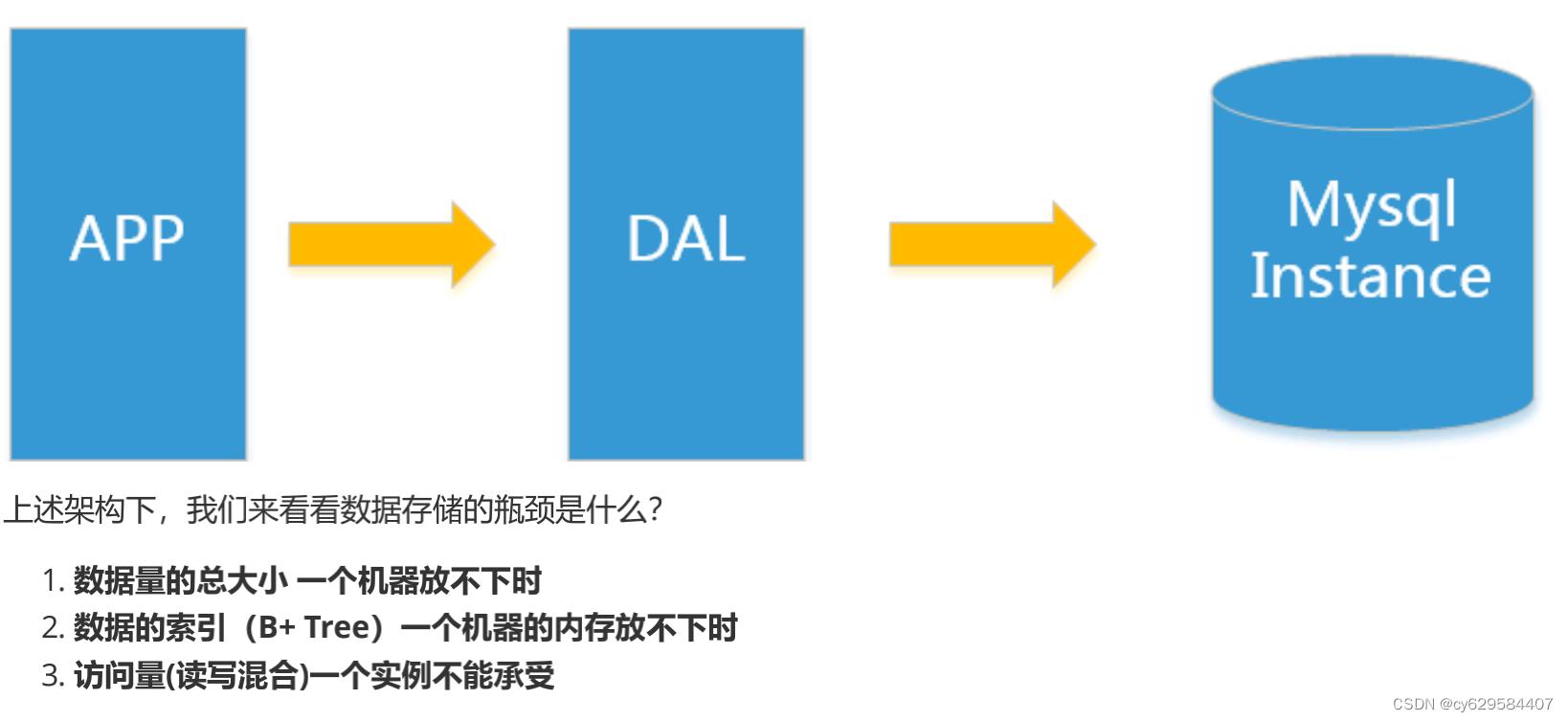 Memcached(
缓存
)+MySQL+
垂直拆分
后来,随着访问量的上升,几乎大部分使用
MySQL
架构的网站在数据库上都开始出现了性能问题,
web
程序不再仅 仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构 和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web
机器通过文 件缓存不能共享,大量的小文件缓存也带了了比较高的IO
压力。在这个时候,
Memcached
就自然的成为一个非常时尚的技术产品。
Memcached(
缓存
)+MySQL+
垂直拆分
后来,随着访问量的上升,几乎大部分使用
MySQL
架构的网站在数据库上都开始出现了性能问题,
web
程序不再仅 仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构 和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web
机器通过文 件缓存不能共享,大量的小文件缓存也带了了比较高的IO
压力。在这个时候,
Memcached
就自然的成为一个非常时尚的技术产品。
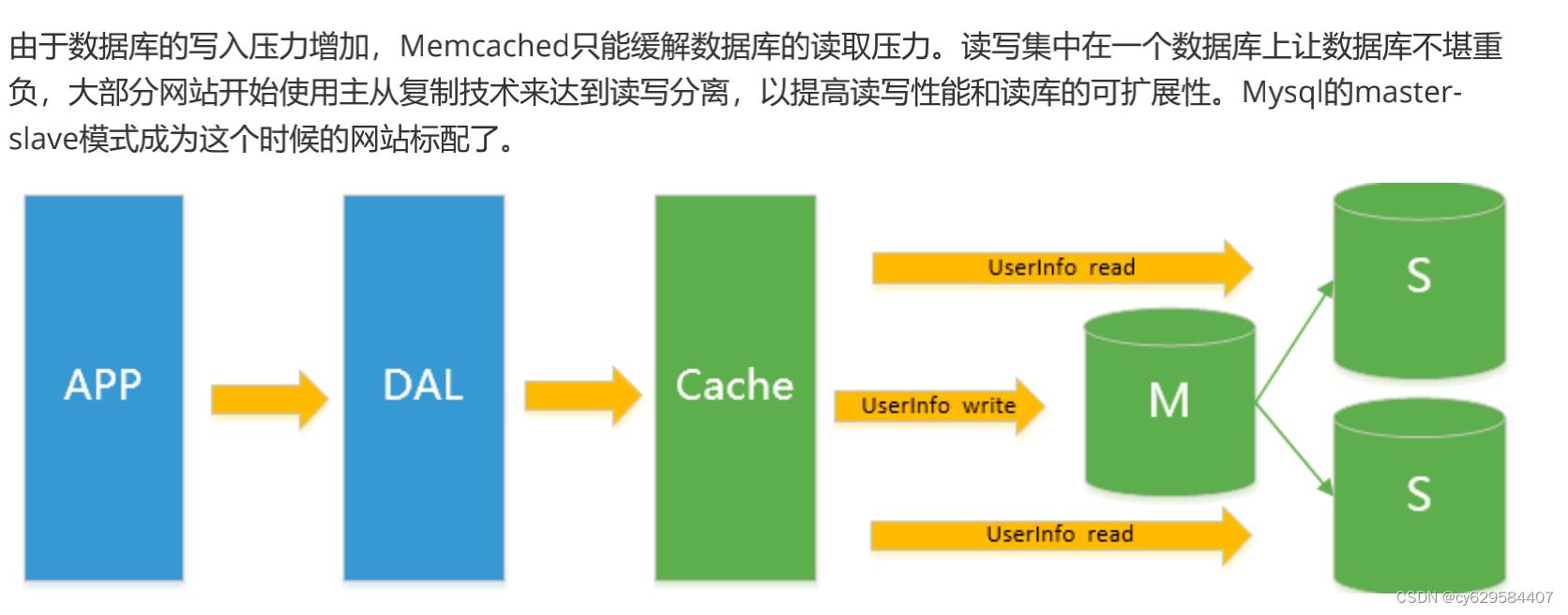
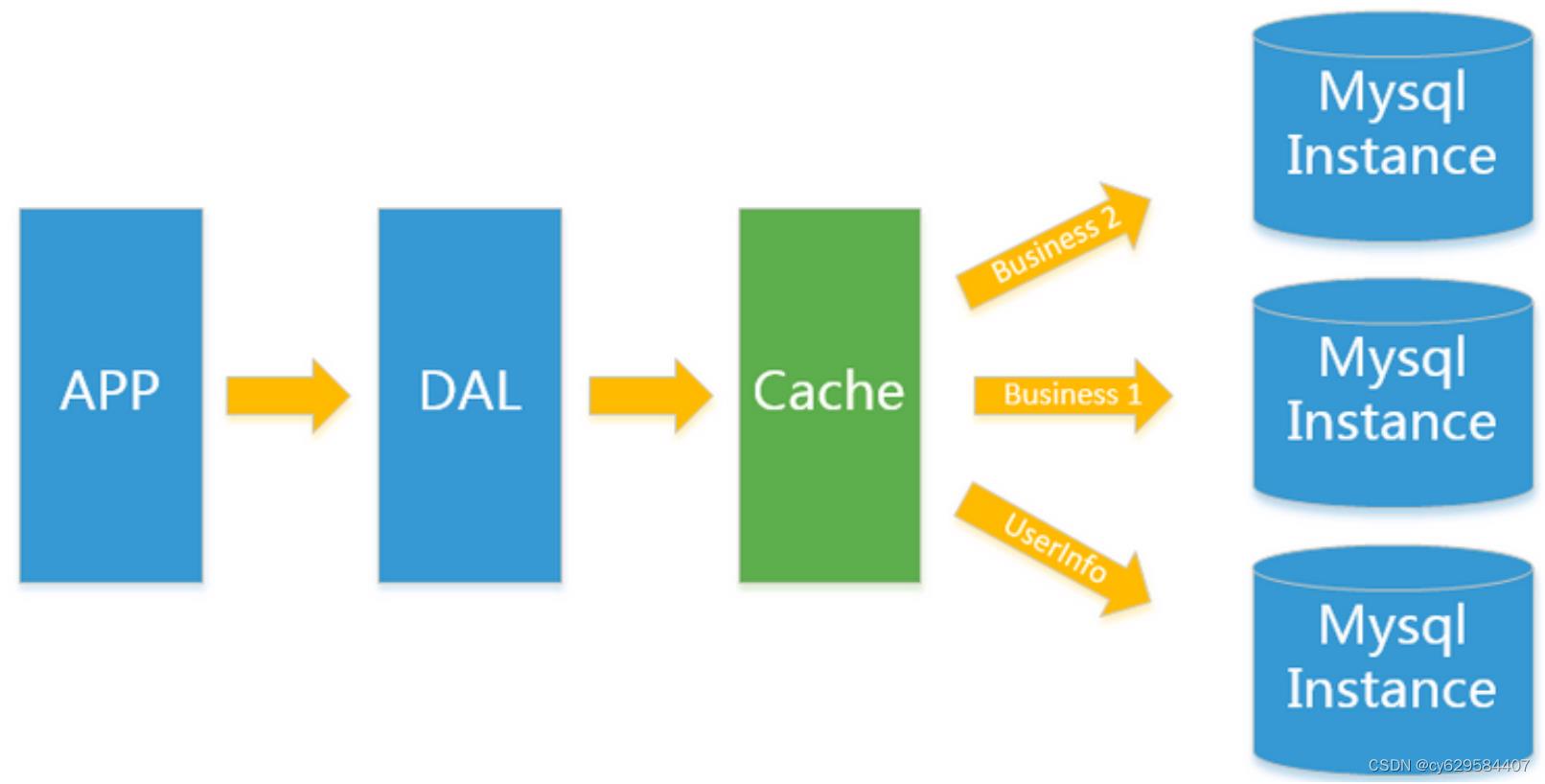 Mysql
主从复制读写分离
Mysql
主从复制读写分离
 三、
MySQL
的扩展性瓶颈
MySQL
数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000
万
4KB
大小的文本就接近
40GB
的大小,如果能把这些数据从
MySQL
省去,
MySQL
将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL
的扩展性差(需要复杂的技术来实现),大数据下IO
压力大,
表结构更改困难
,正是当前使用
MySQL
的开发人员面临的问题。
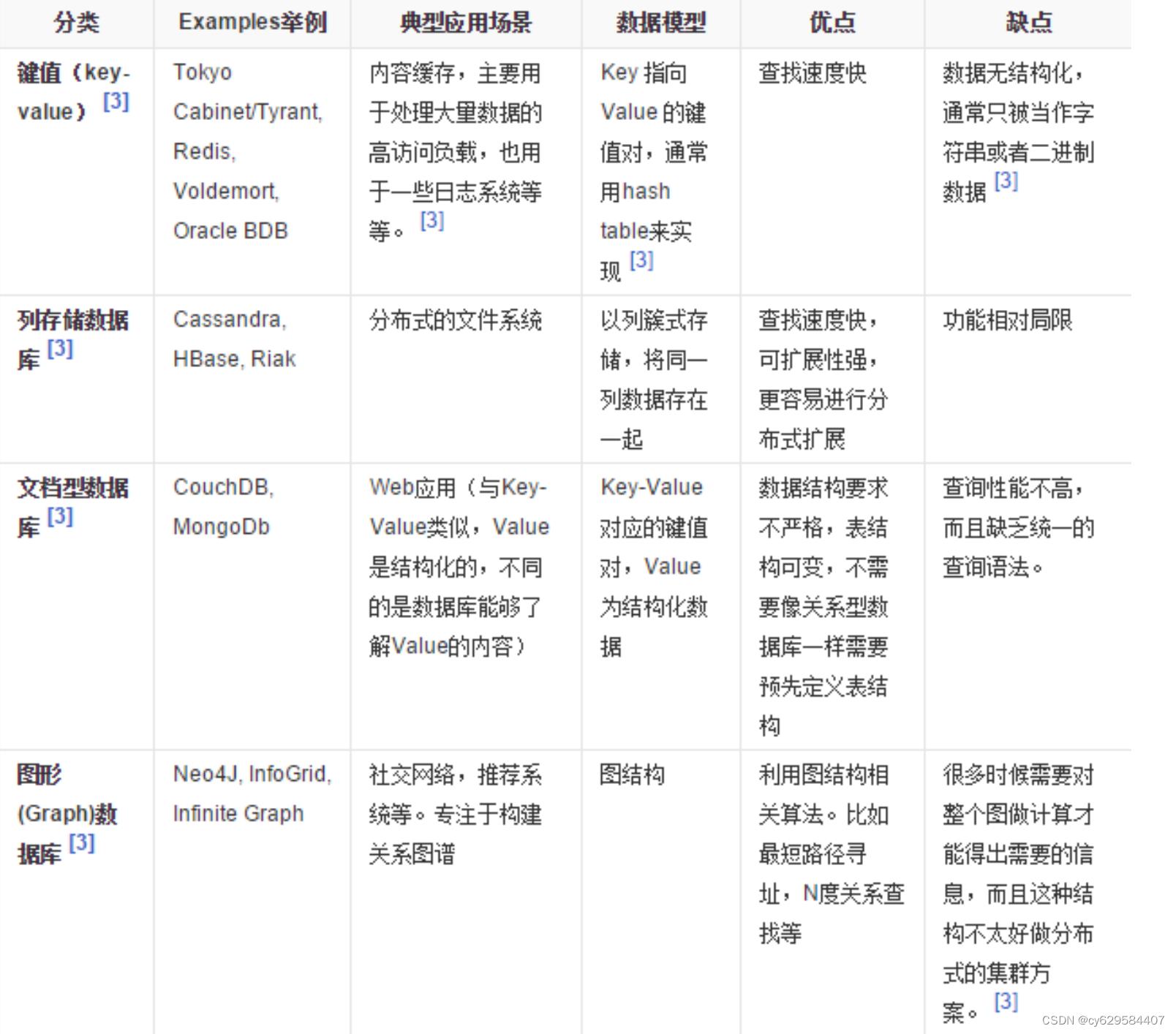
NoSQL(NoSQL = Not Only SQL )
,意即
“
不仅仅是
SQL”
,
泛指非关系型的数据库。随着互联网
web2.0
网站的兴 起,传统的关系数据库在应付web2.0
网站,特别是超大规模和高并发的
SNS
类型的
web2.0
纯动态网站已经显得力 不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL
数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
五、传统
RDBMS VS NOSQL
RDBMS vs NoSQL
RDBMS SQL
高度组织化结构化数据
结构化查询语言(
SQL
)
数据和关系都存储在单独的表中。
数据操纵语言,数据定义语言
严格的一致性
基础事务
NoSQL
代表着不仅仅是
SQL
没有声明性查询语言
没有预定义的模式
-
键
-
值对存储,列存储,文档存储,图形数据库
最终一致性,而非
ACID
属性
非结构化和不可预知的数据
CAP
定理
高性能,高可用性和可伸缩性
三、
MySQL
的扩展性瓶颈
MySQL
数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000
万
4KB
大小的文本就接近
40GB
的大小,如果能把这些数据从
MySQL
省去,
MySQL
将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL
的扩展性差(需要复杂的技术来实现),大数据下IO
压力大,
表结构更改困难
,正是当前使用
MySQL
的开发人员面临的问题。
NoSQL(NoSQL = Not Only SQL )
,意即
“
不仅仅是
SQL”
,
泛指非关系型的数据库。随着互联网
web2.0
网站的兴 起,传统的关系数据库在应付web2.0
网站,特别是超大规模和高并发的
SNS
类型的
web2.0
纯动态网站已经显得力 不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL
数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
五、传统
RDBMS VS NOSQL
RDBMS vs NoSQL
RDBMS SQL
高度组织化结构化数据
结构化查询语言(
SQL
)
数据和关系都存储在单独的表中。
数据操纵语言,数据定义语言
严格的一致性
基础事务
NoSQL
代表着不仅仅是
SQL
没有声明性查询语言
没有预定义的模式
-
键
-
值对存储,列存储,文档存储,图形数据库
最终一致性,而非
ACID
属性
非结构化和不可预知的数据
CAP
定理
高性能,高可用性和可伸缩性
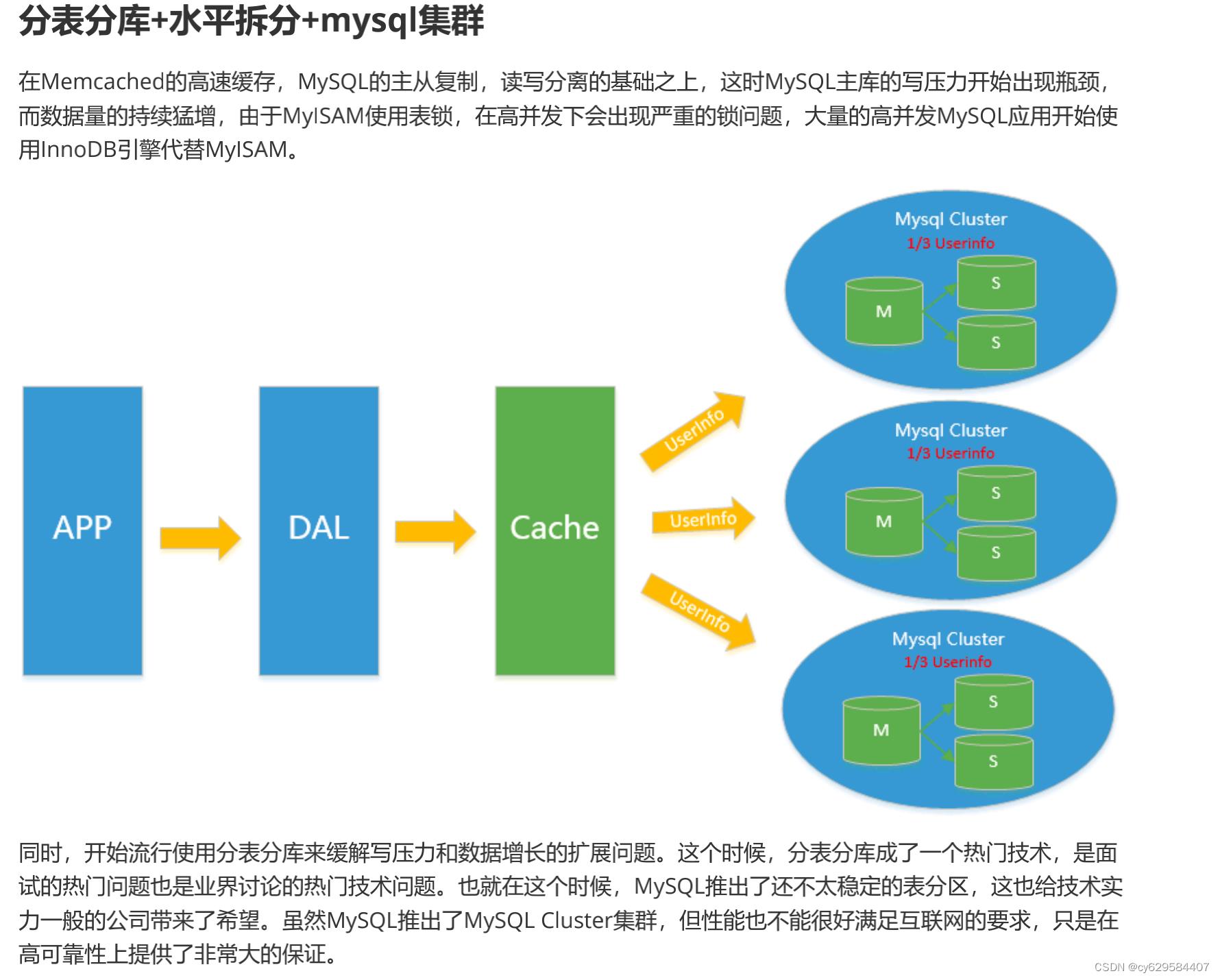
 数据的水平拆分和垂直拆分
当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
数据库拆分简单来说,就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放
到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
切分模式: 垂直(纵向)拆分、水平拆分。
垂直拆分(按业务类型进行拆分)
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据 库上面,这样也就将数据或者说压力分担到不同的库上面
优点:
1.
拆分后业务清晰,拆分规则明确。
2.
系统之间整合或扩展容易。
3.
数据维护简单。
缺点:
1.
部分业务表无法
join
,只能通过接口方式解决,提高了系统复杂度。
2.
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3.
事务处理复杂
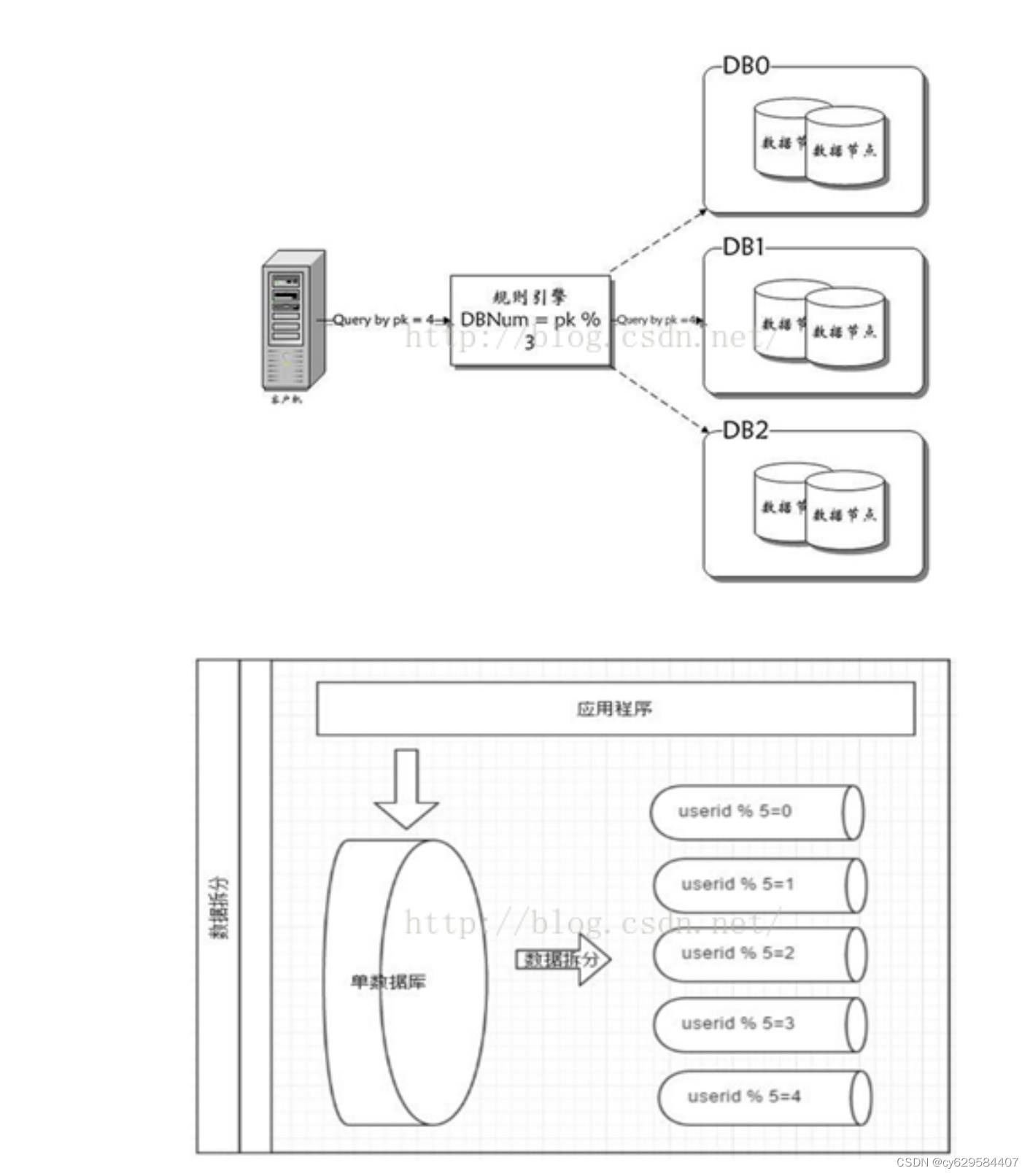
水平拆分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据
库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中
包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到
一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式
数据的水平拆分和垂直拆分
当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了。
数据库拆分简单来说,就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放
到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
切分模式: 垂直(纵向)拆分、水平拆分。
垂直拆分(按业务类型进行拆分)
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据 库上面,这样也就将数据或者说压力分担到不同的库上面
优点:
1.
拆分后业务清晰,拆分规则明确。
2.
系统之间整合或扩展容易。
3.
数据维护简单。
缺点:
1.
部分业务表无法
join
,只能通过接口方式解决,提高了系统复杂度。
2.
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3.
事务处理复杂
水平拆分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据
库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中
包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到
一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式
 优点:
1.
不存在单库大数据,高并发的性能瓶颈。
2.
对应用透明,应用端改造较少。
3.
按照合理拆分规则拆分,
join
操作基本避免跨库。
4.
提高了系统的稳定性跟负载能力。
缺点:
1.
拆分规则难以抽象。
2.
分片事务一致性难以解决。
3.
数据多次扩展难度跟维护量极大。
4.
跨库
join
性能较差。
拆分的处理难点
两张方式共同缺点
1.
引入分布式事务的问题。
2.
跨节点
Join
的问题。
3.
跨节点合并排序分页问题。
针对数据源管理,目前主要有两种思路:
A.
客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个 数据库,在模块内完成数据的整合。
优点:相对简单,无性能损耗。
缺点:不够通用,数据库连接的处理复杂,对业务不够透明,处理复杂。
B.
通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
优点:通用,对应用透明,改造少。
缺点:实现难度大,有二次转发性能损失。
拆分原则
1.
尽量不拆分,架构是进化而来,不是一蹴而就。
(SOA)
2.
最大可能的找到最合适的切分维度。
3.
由于数据库中间件对数据
Join
实现的优劣难以把握,而且实现高性能难度极大,业务读取 尽量少使用多表
Join - 尽量通过数据冗余,分组避免数据垮库多表join
。
4.
尽量避免分布式事务。
5.
单表拆分到数据
1000
万以内。 切分方 范围、枚举、时间、取模、哈希、指定等
案例分析
场景一
建立一个历史
his
系统,将公司的一些历史个人游戏数据保存到这个
his
系统中,主要是写入,还有部分查询,读写比约为1:4
;由于是所有数据的历史存取,所以并发要求比较高;
分析:
历史数据
写多都少
越近日期查询越频繁?
什么业务数据?用户游戏数据
有没有大规模分析查询?
数据量多大?
保留多久?
机器资源有多少?
方案
1
:按照日期每月一个分片
带来的问题:
1.
数据热点问题(压力不均匀)
方案
2
:按照用户取模,
--by Jerome
就这个比较合适了
带来的问题:后续扩容困难
方案
3
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
场景二
建立一个商城订单系统,保存用户订单信息。
分析:
电商系统
一号店或京东类?淘宝或天猫?
实时性要求高
存在瞬时压力
基本不存在大规模分析
数据规模?
机器资源有多少?
维度?商品?用户?商户?
方案
1
:按照用户取模,
带来的问题:后续扩容困难
方案
2
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案
3
:按省份地区或者商户取模
数据分配不一定均匀
场景
3
上海公积金,养老金,社保系统
分析:
社保系统
实时性要求不高
不存在瞬时压力
大规模分析?
数据规模大
数据重要不可丢失
偏于查询?
方案
1
:按照用户取模,
带来的问题:后续扩容困难
方案
2
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案
3
:按省份区县地区枚举
数据分配不一定均匀
分布式事务
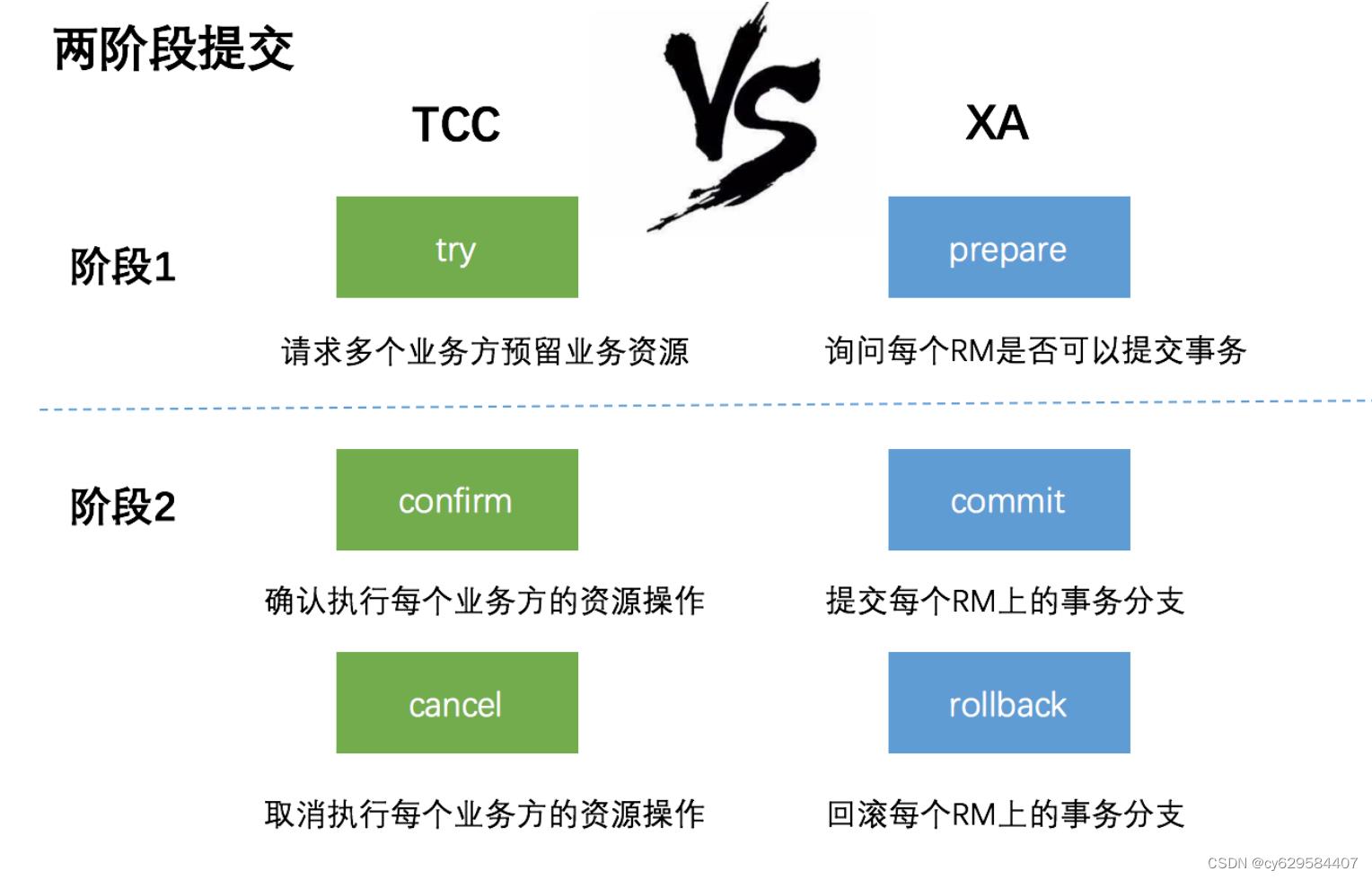
什么是分布式事务?
分布式事务用于在分布式系统中保证不同节点之间的数据一致性。分布式事务的实现有很多种,最具有代表性的是 由Oracle Tuxedo
系统提出的
XA
分布式事务协议。
XA
协议包含
两阶段提交(
2PC
)
和
三阶段提交(
3PC
)
两种实现,这里我们重点介绍两阶段提交的具体过程。
XA
两阶段提交(
2PC
)
在魔兽世界这款游戏中,副本组团打
BOSS
的时候,为了更方便队长与队员们之间的协作,队长可以发起一个
“
就位 确认”
的操作:
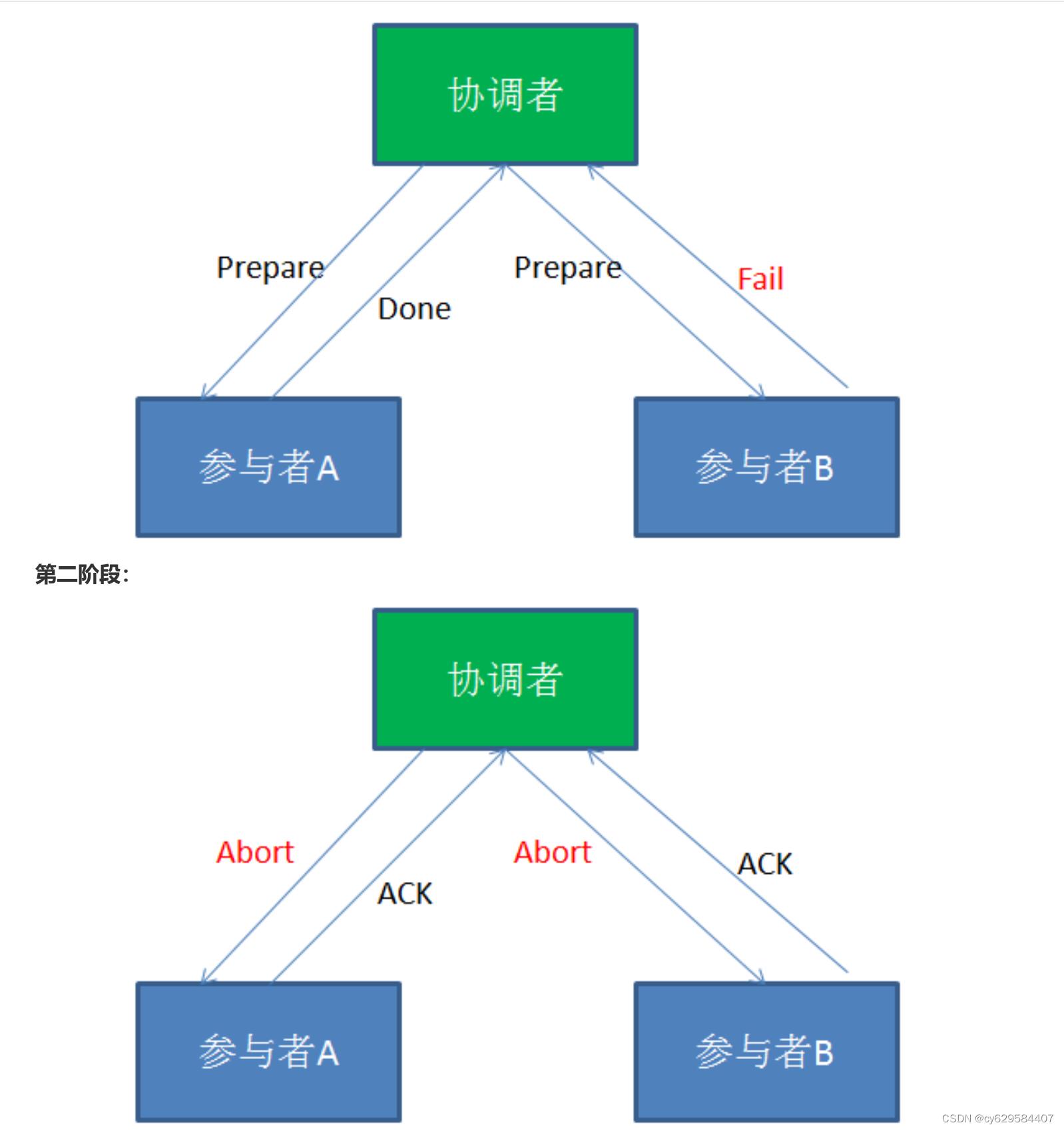
在
XA
分布式事务的第一阶段,作为事务协调者的节点会首先向所有的参与者节点发送
Prepare
请求。 在接到Prepare
请求之后,每一个参与者节点会各自执行与事务有关的数据更新,写入
Undo Log
和
Redo Log
。如 果参与者执行成功,暂时不提交事务,而是向事务协调节点返回“
完成
”
消息。
当事务协调者接到了所有参与者的返回消息,整个分布式事务将会进入第二阶段。
在
XA
分布式事务的第二阶段,如果事务协调节点在之前所收到都是正向返回,那么它将会向所有事务参与者发出 Commit请求。
接到
Commit
请求之后,事务参与者节点会各自进行本地的事务提交,并释放锁资源。当本地事务完成提交后,将 会向事务协调者返回“
完成
”
消息。
当事务协调者接收到所有事务参与者的
“
完成
”
反馈,整个分布式事务完成。
以上所描述的是
XA
两阶段提交的正向流程,接下来我们看一看失败情况的处理流程:
优点:
1.
不存在单库大数据,高并发的性能瓶颈。
2.
对应用透明,应用端改造较少。
3.
按照合理拆分规则拆分,
join
操作基本避免跨库。
4.
提高了系统的稳定性跟负载能力。
缺点:
1.
拆分规则难以抽象。
2.
分片事务一致性难以解决。
3.
数据多次扩展难度跟维护量极大。
4.
跨库
join
性能较差。
拆分的处理难点
两张方式共同缺点
1.
引入分布式事务的问题。
2.
跨节点
Join
的问题。
3.
跨节点合并排序分页问题。
针对数据源管理,目前主要有两种思路:
A.
客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个 数据库,在模块内完成数据的整合。
优点:相对简单,无性能损耗。
缺点:不够通用,数据库连接的处理复杂,对业务不够透明,处理复杂。
B.
通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
优点:通用,对应用透明,改造少。
缺点:实现难度大,有二次转发性能损失。
拆分原则
1.
尽量不拆分,架构是进化而来,不是一蹴而就。
(SOA)
2.
最大可能的找到最合适的切分维度。
3.
由于数据库中间件对数据
Join
实现的优劣难以把握,而且实现高性能难度极大,业务读取 尽量少使用多表
Join - 尽量通过数据冗余,分组避免数据垮库多表join
。
4.
尽量避免分布式事务。
5.
单表拆分到数据
1000
万以内。 切分方 范围、枚举、时间、取模、哈希、指定等
案例分析
场景一
建立一个历史
his
系统,将公司的一些历史个人游戏数据保存到这个
his
系统中,主要是写入,还有部分查询,读写比约为1:4
;由于是所有数据的历史存取,所以并发要求比较高;
分析:
历史数据
写多都少
越近日期查询越频繁?
什么业务数据?用户游戏数据
有没有大规模分析查询?
数据量多大?
保留多久?
机器资源有多少?
方案
1
:按照日期每月一个分片
带来的问题:
1.
数据热点问题(压力不均匀)
方案
2
:按照用户取模,
--by Jerome
就这个比较合适了
带来的问题:后续扩容困难
方案
3
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
场景二
建立一个商城订单系统,保存用户订单信息。
分析:
电商系统
一号店或京东类?淘宝或天猫?
实时性要求高
存在瞬时压力
基本不存在大规模分析
数据规模?
机器资源有多少?
维度?商品?用户?商户?
方案
1
:按照用户取模,
带来的问题:后续扩容困难
方案
2
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案
3
:按省份地区或者商户取模
数据分配不一定均匀
场景
3
上海公积金,养老金,社保系统
分析:
社保系统
实时性要求不高
不存在瞬时压力
大规模分析?
数据规模大
数据重要不可丢失
偏于查询?
方案
1
:按照用户取模,
带来的问题:后续扩容困难
方案
2
:按用户
ID
范围分片(
1-1000
万
=
分片
1
,
xxx
)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案
3
:按省份区县地区枚举
数据分配不一定均匀
分布式事务
什么是分布式事务?
分布式事务用于在分布式系统中保证不同节点之间的数据一致性。分布式事务的实现有很多种,最具有代表性的是 由Oracle Tuxedo
系统提出的
XA
分布式事务协议。
XA
协议包含
两阶段提交(
2PC
)
和
三阶段提交(
3PC
)
两种实现,这里我们重点介绍两阶段提交的具体过程。
XA
两阶段提交(
2PC
)
在魔兽世界这款游戏中,副本组团打
BOSS
的时候,为了更方便队长与队员们之间的协作,队长可以发起一个
“
就位 确认”
的操作:
在
XA
分布式事务的第一阶段,作为事务协调者的节点会首先向所有的参与者节点发送
Prepare
请求。 在接到Prepare
请求之后,每一个参与者节点会各自执行与事务有关的数据更新,写入
Undo Log
和
Redo Log
。如 果参与者执行成功,暂时不提交事务,而是向事务协调节点返回“
完成
”
消息。
当事务协调者接到了所有参与者的返回消息,整个分布式事务将会进入第二阶段。
在
XA
分布式事务的第二阶段,如果事务协调节点在之前所收到都是正向返回,那么它将会向所有事务参与者发出 Commit请求。
接到
Commit
请求之后,事务参与者节点会各自进行本地的事务提交,并释放锁资源。当本地事务完成提交后,将 会向事务协调者返回“
完成
”
消息。
当事务协调者接收到所有事务参与者的
“
完成
”
反馈,整个分布式事务完成。
以上所描述的是
XA
两阶段提交的正向流程,接下来我们看一看失败情况的处理流程:
 常见的限流算法
计数器法
计数器法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于
A
接口来说,我们
1
分钟的访问次数 不能超过100
个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器
counter
,每当一个请求过来 的时候,counter
就加
1
,如果
counter
的值大于
100
并且该请求与第一个 请求的间隔时间还在
1
分钟之内,那么说 明请求数过多;如果该请求与第一个请求的间隔时间大于1
分钟,且
counter
的值还在限流范围内,那么就重置 counter
常见的限流算法
计数器法
计数器法是限流算法里最简单也是最容易实现的一种算法。比如我们规定,对于
A
接口来说,我们
1
分钟的访问次数 不能超过100
个。那么我们可以这么做:在一开 始的时候,我们可以设置一个计数器
counter
,每当一个请求过来 的时候,counter
就加
1
,如果
counter
的值大于
100
并且该请求与第一个 请求的间隔时间还在
1
分钟之内,那么说 明请求数过多;如果该请求与第一个请求的间隔时间大于1
分钟,且
counter
的值还在限流范围内,那么就重置 counter
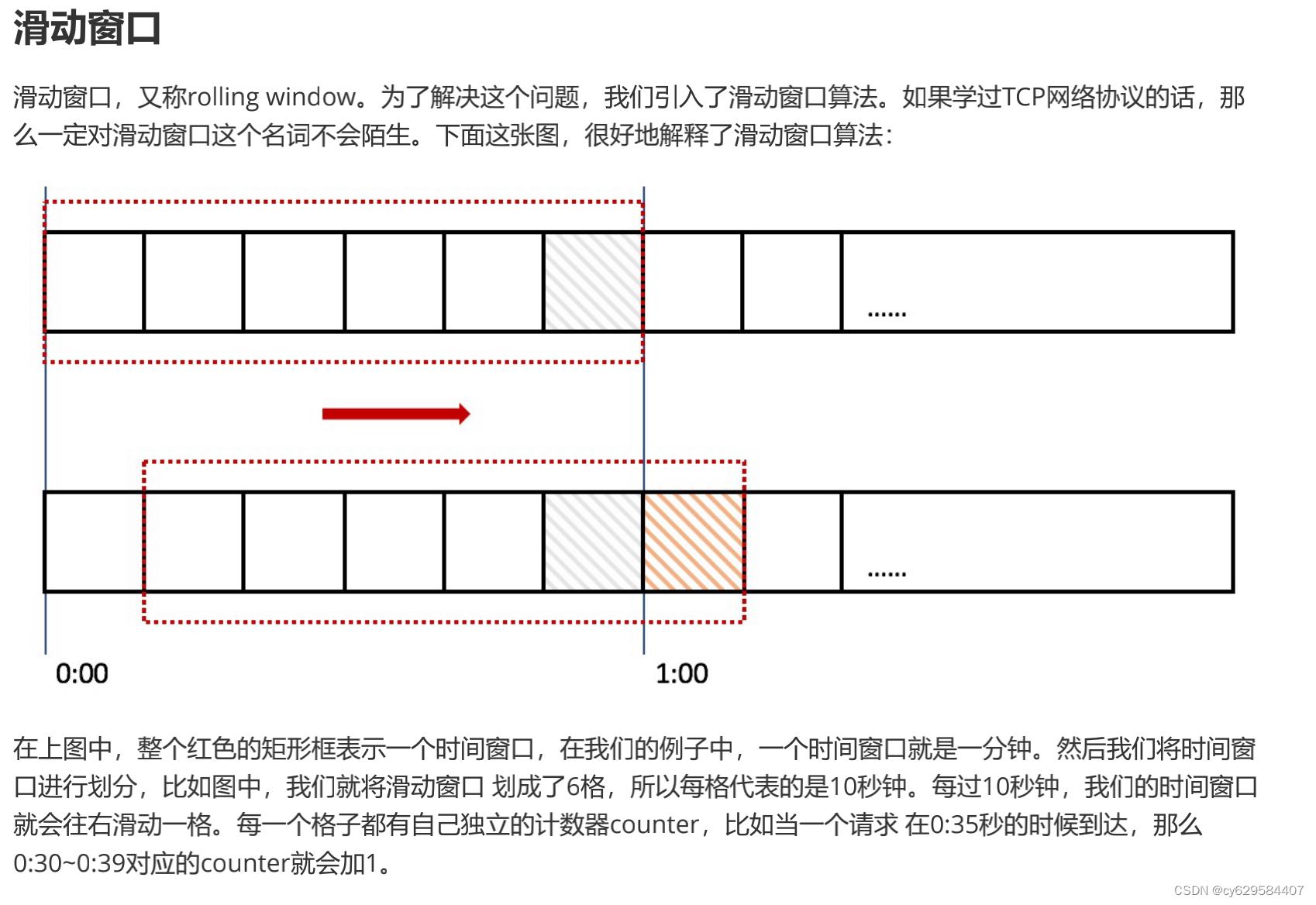 那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,
0:59
到达的
100
个请求会落在灰色的格子中,而 1:00到达的请求会落在橘黄色的格 子中。当时间到达
1:00
时,我们的窗口会往右移动一格,那么此时时间窗口内的 总请求数量一共是200
个,超过了限定的
100
个,所以此时能够检测出来触 发了限流。 我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1
格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,
0:59
到达的
100
个请求会落在灰色的格子中,而 1:00到达的请求会落在橘黄色的格 子中。当时间到达
1:00
时,我们的窗口会往右移动一格,那么此时时间窗口内的 总请求数量一共是200
个,超过了限定的
100
个,所以此时能够检测出来触 发了限流。 我再来回顾一下刚才的计数器算法,我们可以发现,计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1
格。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
 令牌桶算法
令牌桶算法,又称
token bucket
。为了理解该算法,我们再来看一下维基百科上对该算法的示意图:
令牌桶算法
令牌桶算法,又称
token bucket
。为了理解该算法,我们再来看一下维基百科上对该算法的示意图:
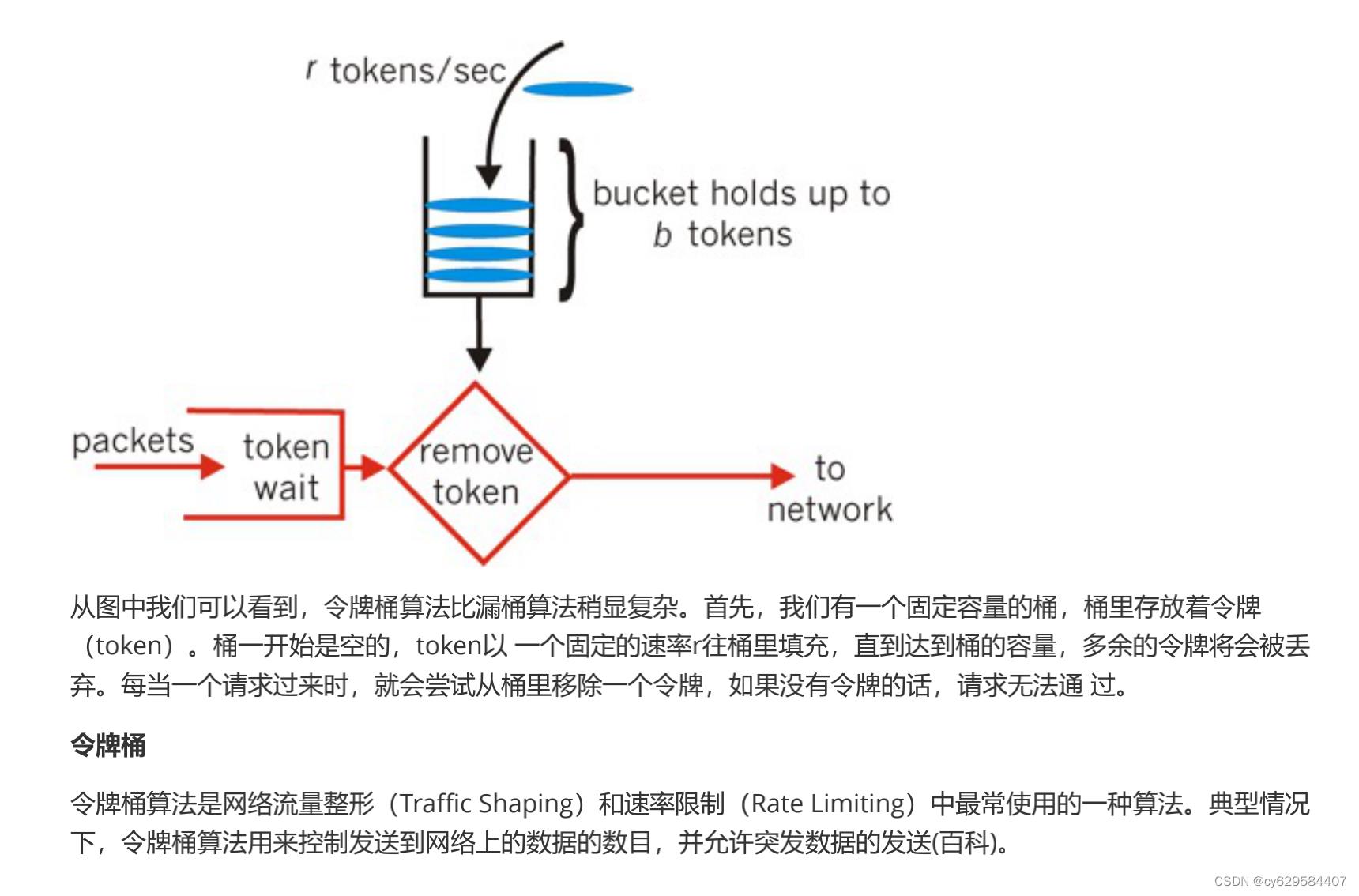
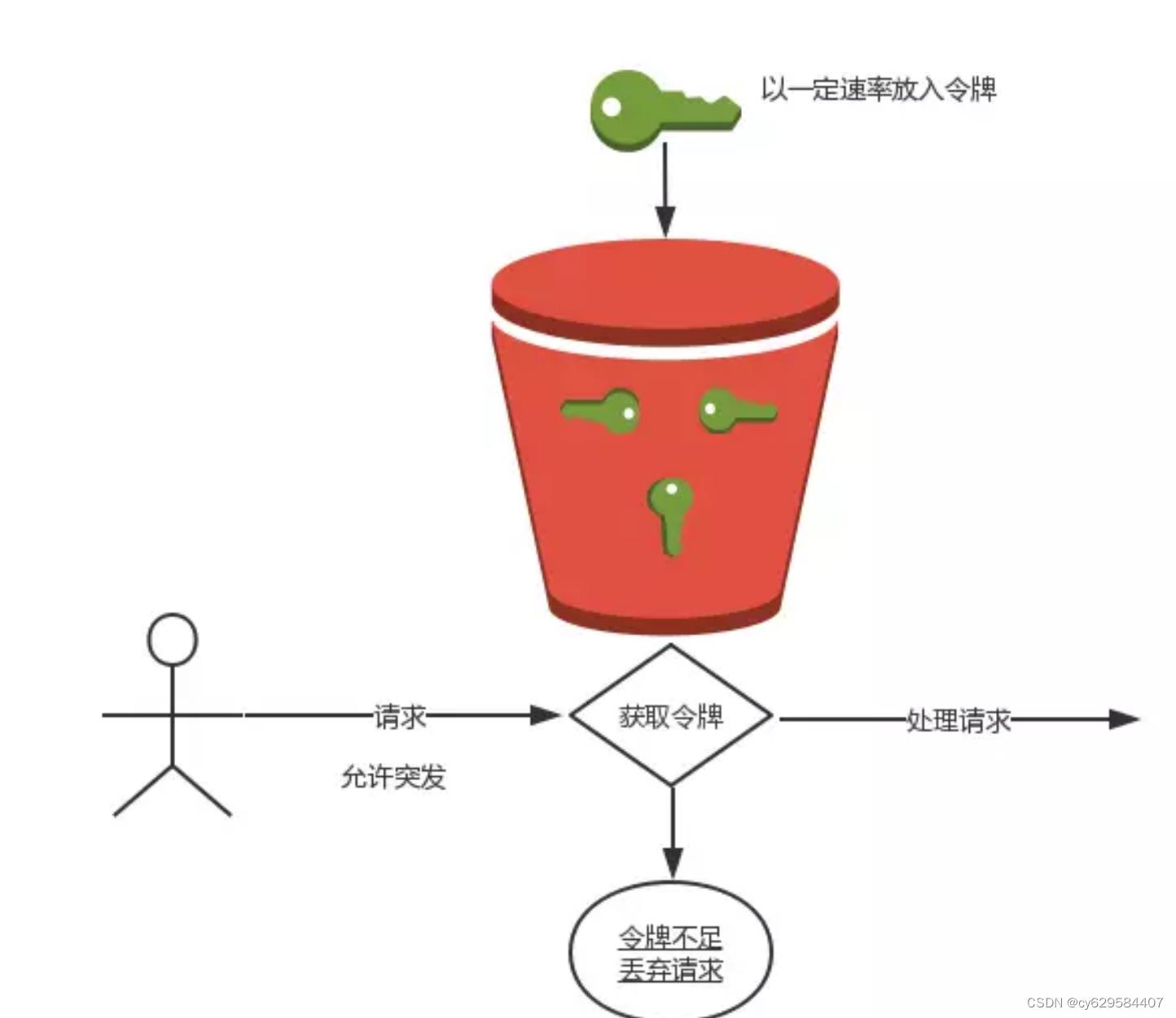
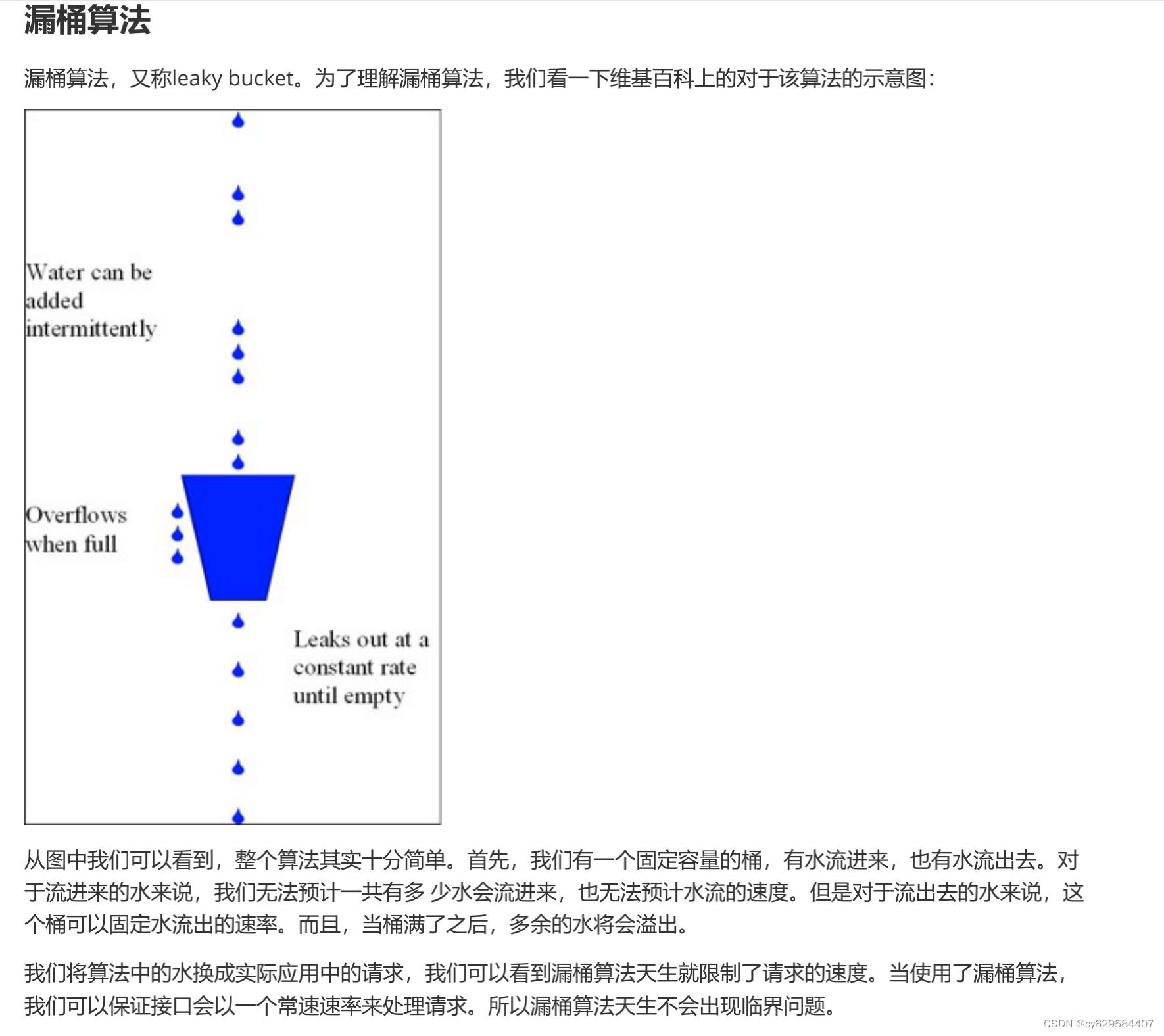
在秒杀活动中,用户的请求速率是不固定的,这里我们假定为10r/s,令牌按照5个每秒的速率放入令牌桶,桶中最
多存放 20 个令牌。仔细想想,是不是总有那么一部分请求被丢弃。 计数器 VS 滑动窗口 计数器算法是最简单的算法,可以看成是滑动窗口的低精度实现。 滑动窗口由于需要存储多份的计数器(每一个格 子存一份),所以滑动窗口在实现上需要更多的存储空间。也就是说,如果滑动窗口的精度越高,需要的存储空间 就越大。 漏桶算法 VS 令牌桶算法 漏桶算法和令牌桶算法最明显的区别是令牌桶算法允许流量一定程度的突发。因为默认的令牌桶算法,取走 token 是不需要耗费时间的,也就是说,假设桶内有100 个 token 时,那么可以瞬间允许 100 个请求通过。令牌桶算法由于实现简单,且允许某些流量的突发,对用户友好,所以被业界采用地较多。当然我们需要具体情具体分析,只有最合适的算法,没有最优的算法。 dns 域名解析负载均衡 原理:在 DNS 服务器上配置多个域名对应 IP 的记录。例如一个域名 www.baidu.com 对应一组 web 服务器 IP 地址, 域名解析时经过DNS 服务器的算法将一个域名请求分配到合适的真实服务器上。 优点:将负载均衡的工作交给了 DNS ,省却了网站管理维护负载均衡服务器的麻烦,同事许多 DNS 还支持基于地理位置的域名解析,将域名解析成距离用户地理最近的一个服务器地址,加快访问速度吗,改善性能。 缺点:目前的 DNS 解析是多级解析,每一级 DNS 都可能化缓存记录 A ,当摸一服务器下线后,该服务器对应的 DNS记录A 可能仍然存在,导致分配到该服务器的用户访问失败。 DNS 负载均衡的控制权在域名服务商手里,网站可能无法做出过多的改善和管理。 不能够按服务器的处理能力来分配负载。 DNS 负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异, 不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。 可能会造成额外的网络问题。为了使本 DNS 服务器和其他 DNS 服务器及时交互,保证 DNS 数据及时更新,使地址 能随机分配,一般都要将DNS 的刷新时间设置的较小,但太小将会使 DNS 流量大增造成额外的网络问题。 反向代理负载均衡 原理:反向代理处于 web 服务器这边,反向代理服务器提供负载均衡的功能,同时管理一组 web 服务器,它根据负载均衡算法将请求的浏览器访问转发到不同的web 服务器处理,处理结果经过反向服务器返回给浏览器。 例如:浏览器访问请求的地址是反向代理服务器的地址 114.100.80.10 ,反向代理服务器收到请求,经过负载均算法后得到一个真实物理地址10.0.03 ,并将请求结果发给真实无服务,真实服务器处理完后通过反向代理服务器 返回给请求用户。 优点:部署简单,处于 http 协议层面。 缺点:使用了反向代理服务器后, web 服务器地址不能直接暴露在外,因此 web 服务器不需要使用外部 IP 地址, 而反向代理服务作为沟通桥梁就需要配置双网卡、外部内部两套IP 地址。 http 重定向协议实现负载均衡 原理:根据用户的 http 请求计算出一个真实的 web 服务器地址,并将该 web 服务器地址写入 http 重定向响应中返回给浏览器,由浏览器重新进行访问。 优点:比较简单 缺点:浏览器需要两次次请求服务器才能完成一次访问,性能较差。 http 重定向服务器自身的处理能力可能成为瓶颈。 使用 http302 响应重定向,有可能使搜索引擎判断为 SEO 作弊,降低搜索排名。 分层的负载均衡算法 一致性 Hash 算法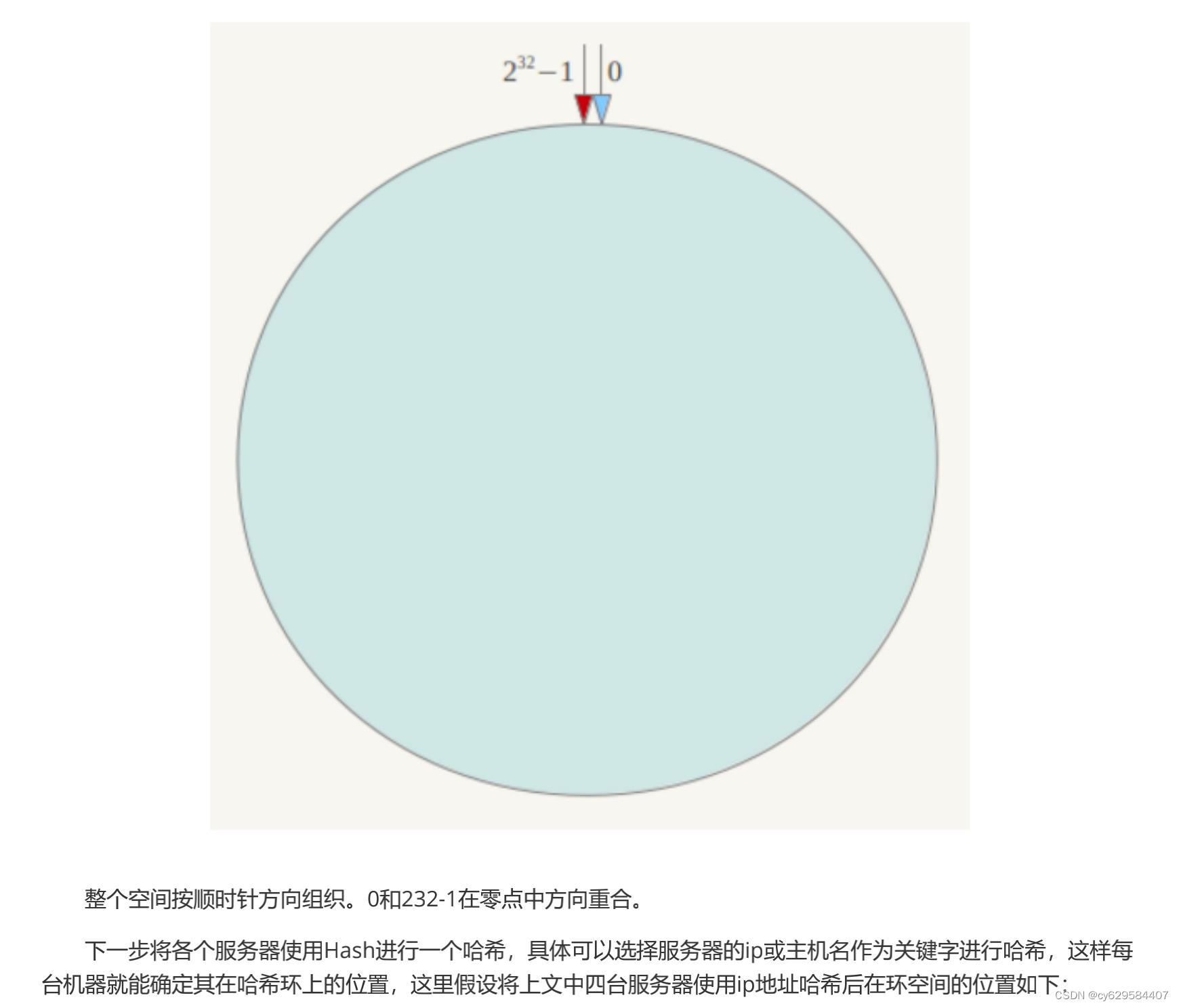
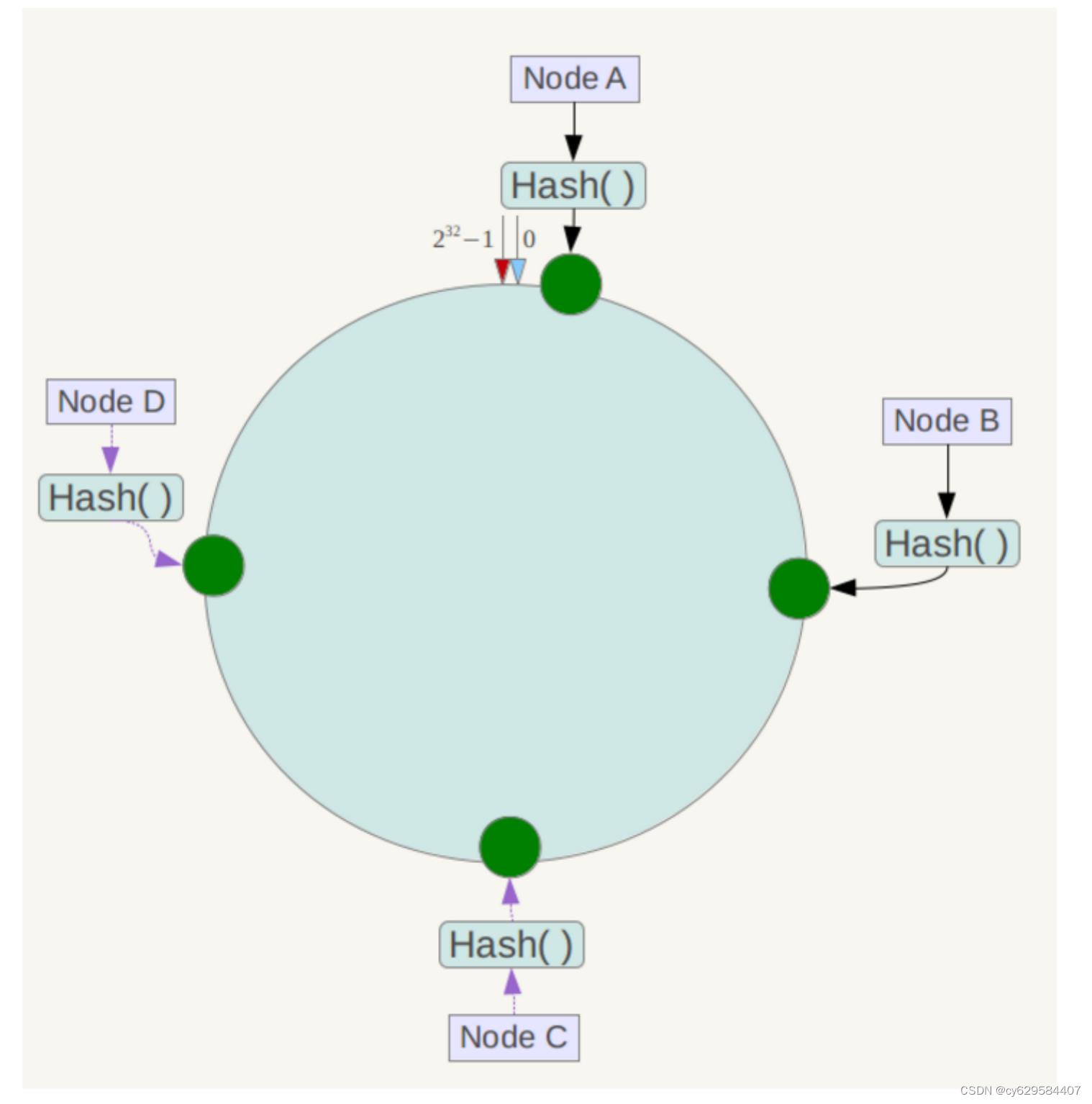 接下来使用如下算法定位数据访问到相应服务器:将数据
key
使用相同的函数
Hash
计算出哈希值,并确定此数据在
环上的位置,从此位置沿环顺时针
“
行走
”
,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有
Object A
、
Object B
、
Object C
、
Object D
四个数据对象,经过哈希计算后,在环空间上的位置如下:
接下来使用如下算法定位数据访问到相应服务器:将数据
key
使用相同的函数
Hash
计算出哈希值,并确定此数据在
环上的位置,从此位置沿环顺时针
“
行走
”
,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有
Object A
、
Object B
、
Object C
、
Object D
四个数据对象,经过哈希计算后,在环空间上的位置如下:
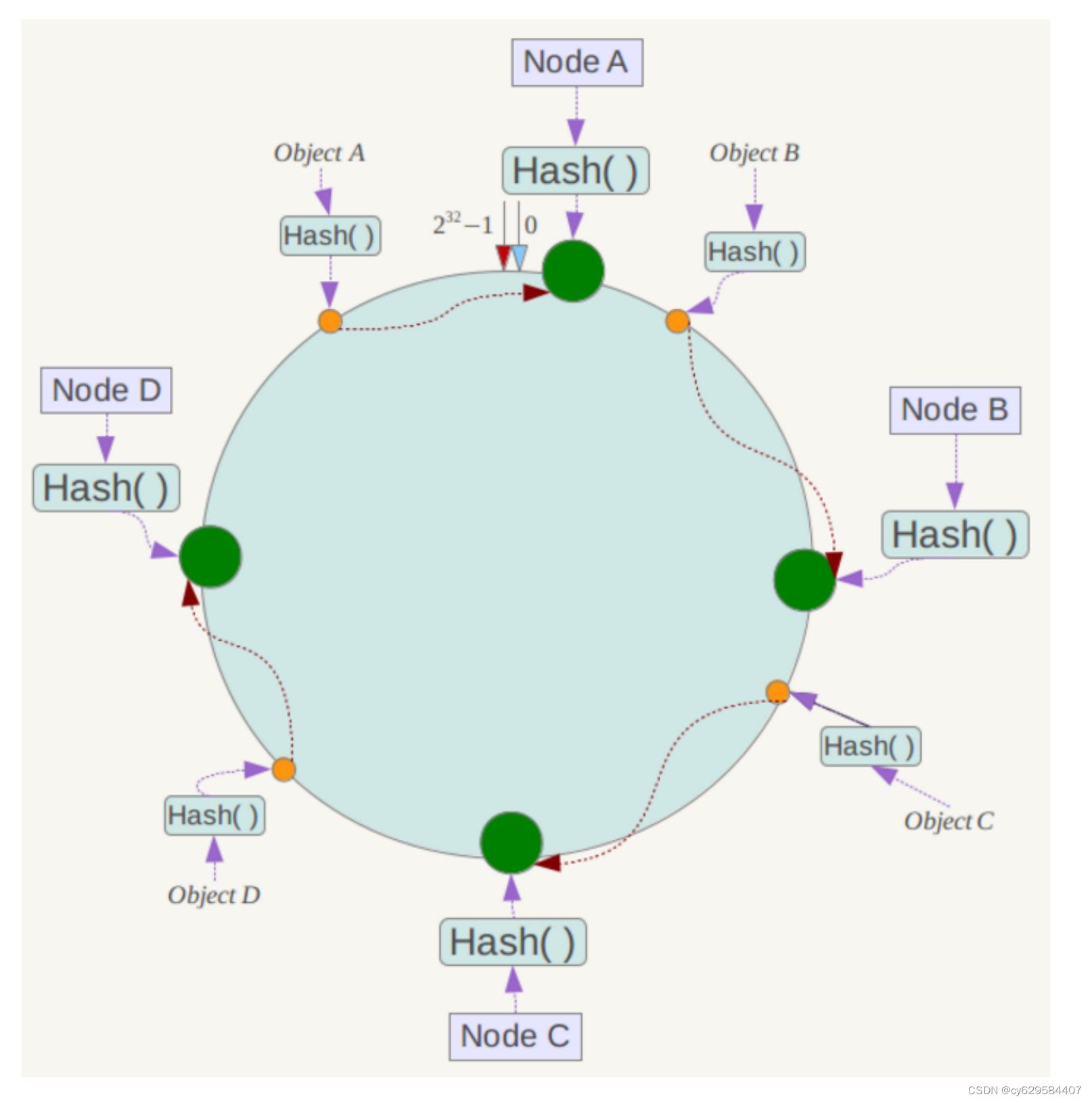 根据一致性哈希算法,数据
A
会被定为到
Node A
上,
B
被定为到
Node B
上,
C
被定为到
Node C
上,
D
被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设
Node C
不幸宕机,可以看到此时对象
A
、
B
、
D
不会受到影响,只有C
对象被重定位到
Node D
。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器
Node X
,如下图所示:
此时对象
Object A
、
B
、
D
不受影响,只有对象
C
需要重定位到新的
Node X
。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
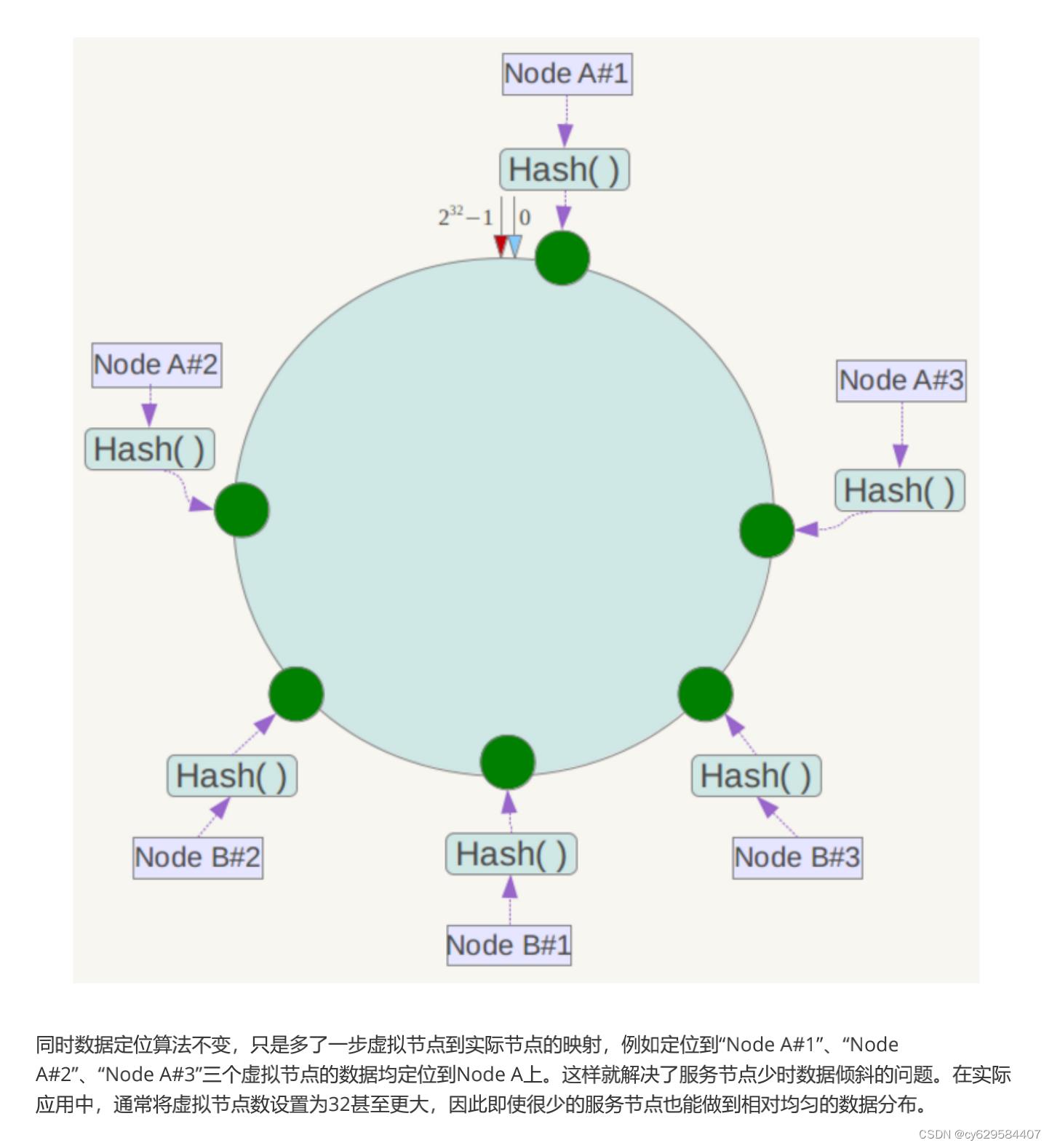
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服 务器,其环分布如下,
根据一致性哈希算法,数据
A
会被定为到
Node A
上,
B
被定为到
Node B
上,
C
被定为到
Node C
上,
D
被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设
Node C
不幸宕机,可以看到此时对象
A
、
B
、
D
不会受到影响,只有C
对象被重定位到
Node D
。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器
Node X
,如下图所示:
此时对象
Object A
、
B
、
D
不受影响,只有对象
C
需要重定位到新的
Node X
。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服 务器,其环分布如下,
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战
对于高并发的场景来说,比如电商类,o2o,门户,等等互联网类的项目,缓存技术是Java项目中最常见的一种应用技术。然而,行业里很多朋友对缓存技术的了解与掌握,仅仅停留在掌握redis/memcached等缓存技术的基础使用,最多了解一些集群相关的知识,大部分人都可以对缓存技术掌握到这个程度。然而,仅仅对缓存相关的技术掌握到这种程度,无论是对于开发复杂的高并发系统,或者是在往Java高级工程师、Java资深工程师、Java架构师这些高阶的职位发展的过程中,都是完全不够用的。技术成长出现瓶颈,在自己公司的项目中,没有任何高并发与高可用的挑战性项目,自己不知道如何成长,自己也不知道如何让自己的技术更上一层楼。这成为了很多同学的职业发展的困惑。
同样的,高可用相关的技术以及架构,对于大型复杂的分布式系统,也是非常的重要。高可用架构中,非常重要的一个环节,就是如何将分布式系统中的各个服务打造成高可用的服务,足以应对分布式系统中各种各样的异常问题,比如服务间调用超时或者失败。这就涉及到了高可用分布式系统中的很多重要的技术,包括资源隔离,限流与过载保护,熔断,优雅降级,容错,超时控制,监控运维,等等。而行业中相当比例的同学,对高可用系统架构以及相关的技术,几乎没有太多的了解。同时也成为了你设计一个复杂的高可用系统架构,包括面试高阶的Java职位时的一个重要的阻碍。
相信很多朋友都会有这种感觉,自己的技术不知道如何成长,在公司里遇到复杂的业务场景时,瞬间又觉得自己的技术储备完全不够用。或者是在面试的时候发现自己没有任何的优势。虽然了解redis/memcached,ActiveMQ,nginx负载均衡等技术,但是了解这些技术就能让你有技术竞争力吗?掌握这些技术就足够你解决各种复杂系统中的高并发与高可用挑战吗?掌握这些技术在Java高阶职位的面试中,就能让你拥有属于自己的技术亮点吗?答案似乎都是否定的。
针对复杂的高并发、高可用相关的技术以及缓存架构,还有大型复杂的分布式系统,龙果学院独家发布的《亿级流量电商详情页系统的大型高并发与高可用缓存架构实战》视频教程中将会提供详细完整的方案供大家学习和应用。
本课程属于全网独家的大型Java高端架构项目实战课程,课程基于真实的每日上亿流量的大型电商网站中的商品详情页系统,作为项目实战。详细讲解如何实现一个复杂的缓存系统架构,去直接支撑电商背景下的高并发与高性能的访问,同时基于缓存架构本身所处的复杂分布式系统架构环境下,如何设计与实现一个高可用的分布式系统架构。期望通过本套课程能帮助大家学习到一些高阶的技术,复杂问题的解决方案,以及应对挑战性场景的大型架构设计思想。熟练掌握亿级流量电商网站的商品详情页架构如何设计与实现,能够应对各种复杂场景与挑战问题的缓存架构如何设计与实现,高阶的缓存架构以及解决方案如何应对各种棘手的高并发场景下的难题,复杂的缓存架构所处的分布式系统本身如何能够设计为一个高可用的分布式系统架构。
下面是本套课程讲解的核心技术要点。同时下面讲解的所有的架构、技术以及解决方案,在课程中,全部会采用大白话,通俗易懂的方式来讲解,同时上面的所有内容全部采用的纯手工敲代码的方式来实现,全部基于linux虚拟机搭建仿真环境来设计、开发、部署以及测试。以保证大家可以跟着课程学习以及动手练习,包括落地所有的技术以及解决方案。
1、亿级流量电商网站的商品详情页系统架构
面临难题:对于每天上亿流量,拥有上亿页面的大型电商网站来说,能够支撑高并发访问,同时能够秒级让最新模板生效的商品详情页系统的架构是如何设计的?
解决方案:异步多级缓存架构+nginx本地化缓存+动态模板渲染的架构
2、redis企业级集群架构
面临难题:如何让redis集群支撑几十万QPS高并发+99.99%高可用+TB级海量数据+企业级数据备份与恢复?
解决方案:redis的企业级备份恢复方案+复制架构+读写分离+哨兵架构+redis cluster集群部署
3、多级缓存架构设计
面临难题:如何将缓存架构设计的能够支撑高性能以及高并发到极致?同时还要给缓存架构最后的一个安全保护层?
解决方案:nginx抗热点数据+redis抗大规模离线请求+ehcache抗redis崩溃的三级缓存架构
4、数据库+缓存双写一致性解决方案
面临难题:高并发场景下,如何解决数据库与缓存双写的时候数据不一致的情况?
解决方案:异步队列串行化的数据库+缓存双写一致性解决方案
5、缓存维度化拆分解决方案
面临难题:如何解决大value缓存的全量更新效率低下问题?
解决方案:商品缓存数据的维度化拆分解决方案
6、缓存命中率提升解决方案
面临难题:如何将缓存命中率提升到极致?
解决方案:双层nginx部署架构+lua脚本实现一致性hash流量分发策略
7、缓存并发重建冲突解决方案
面临难题:如何解决高并发场景下,缓存重建时的分布式并发重建的冲突问题?
解决方案:基于zookeeper分布式锁的缓存并发重建冲突解决方案
8、缓存预热解决方案
面临难题:如何解决高并发场景下,缓存冷启动导致MySQL负载过高,甚至瞬间被打死的问题?
解决方案:基于storm实时统计热数据的分布式快速缓存预热解决方案
9、热点缓存自动降级方案
面临难题:如何解决热点缓存导致单机器负载瞬间超高?
解决方案:基于storm的实时热点发现+毫秒级的实时热点缓存负载均衡降级
10、高可用分布式系统架构设计
面临难题:如何解决分布式系统中的服务高可用问题?避免多层服务依赖因为少量故障导致系统崩溃?
解决方案:基于hystrix的高可用缓存服务,资源隔离+限流+降级+熔断+超时控制
11、复杂的高可用分布式系统架构设计
面临难题:如何针对复杂的分布式系统将其中的服务设计为高可用架构?
解决方案:基于hystrix的容错+多级降级+手动降级+生产环境参数优化经验+可视化运维与监控
12、缓存雪崩解决方案
面临难题:如何解决恐怖的缓存雪崩问题?避免给公司带来巨大的经济损失?
解决方案:全网独家的事前+事中+事后三层次完美缓存雪崩解决方案
13、缓存穿透解决方案
面临难题:如何解决高并发场景下的缓存穿透问题?避免给MySQL带来过大的压力?
解决方案:缓存穿透解决方案
14、缓存失效解决方案
面临难题:如何解决高并发场景下的缓存失效问题?避免给redis集群带来过大的压力?
解决方案:基于随机过期时间的缓存失效解决方案
课程大纲:
| 第01节 | 课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西? |
| 第02节 | 基于大型电商网站中的商品详情页系统贯穿的授课思路介绍 |
| 第03节 | 小型电商网站的商品详情页的页面静态化架构以及其缺陷 |
| 第04节 | 大型电商网站的异步多级缓存构建+nginx数据本地化动态渲染的架构 |
| 第05节 | 能够支撑高并发+高可用+海量数据+备份恢复的redis的重要性 |
| 第06节 | 从零开始在虚拟机中一步一步搭建一个4个节点的CentOS集群 |
| 第07节 | 单机版redis的安装以及redis生产环境启动方案 |
| 第08节 | redis持久化机对于生产环境中的灾难恢复的意义 |
| 第09节 | 图解分析redis的RDB和AOF两种持久化机制的工作原理 |
| 第10节 | redis的RDB和AOF两种持久化机制的优劣势对比 |
| 第11节 | redis的RDB持久化配置以及数据恢复实验 |
| 第12节 | redis的AOF持久化深入讲解各种操作和相关实验 |
| 第13节 | 在项目中部署redis企业级数据备份方案以及各种踩坑的数据恢复容灾演练 |
| 第14节 | redis如何通过读写分离来承载读请求QPS超过10万+? |
| 第15节 | redis replication以及master持久化对主从架构的安全意义 |
| 第16节 | redis主从复制原理、断点续传、无磁盘化复制、过期key处理 |
| 第17节 | redis replication的完整流运行程和原理的再次深入剖析 |
| 第18节 | 在项目中部署redis的读写分离架构(包含节点间认证口令) |
| 第19节 | 对项目的主从redis架构进行QPS压测以及水平扩容支撑更高QPS |
| 第20节 | redis主从架构下如何才能做到99.99%的高可用性? |
| 第21节 | redis哨兵架构的相关基础知识的讲解 |
| 第22节 | redis哨兵主备切换的数据丢失问题:异步复制、集群脑裂 |
| 第23节 | redis哨兵的多个核心底层原理的深入解析(包含slave选举算法) |
| 第24节 | 在项目中以经典的3节点方式部署哨兵集群 |
| 第25节 | 对项目中的哨兵节点进行管理以及高可用redis集群的容灾演练 |
| 第26节 | redis如何在保持读写分离+高可用的架构下,还能横向扩容支撑1T+海量数据 |
| 第27节 | 数据分布算法:hash+一致性hash+redis cluster的hash slot |
| 第28节 | 在项目中重新搭建一套读写分离+高可用+多master的redis cluster集群 |
| 第29节 | 对项目的redis cluster实验多master写入、读写分离、高可用性 |
| 第30节 | redis cluster通过master水平扩容来支撑更高的读写吞吐+海量数据 |
| 第31节 | redis cluster的自动化slave迁移实现更强的高可用架构的部署方案 |
| 第32节 | redis cluster的核心原理分析:gossip通信、jedis smart定位、主备切换 |
| 第33节 | redis在实践中的一些常见问题以及优化思路(包含linux内核参数优化) |
| 第34节 | redis阶段性总结:1T以上海量数据+10万以上QPS高并发+99.99%高可用 |
| 第35节 | 亿级流量商品详情页的多级缓存架构以及架构中每一层的意义 |
| 第36节 | Cache Aside Pattern缓存+数据库读写模式的分析 |
| 第37节 | 高并发场景下的缓存+数据库双写不一致问题分析与解决方案设计 |
| 第38节 | 在linux虚拟机中安装部署MySQL数据库 |
| 第39节 | 库存服务的开发框架整合与搭建:spring boot+mybatis+jedis |
| 第40节 | 在库存服务中实现缓存与数据库双写一致性保障方案(一) |
| 第41节 | 在库存服务中实现缓存与数据库双写一致性保障方案(二) |
| 第42节 | 在库存服务中实现缓存与数据库双写一致性保障方案(三) |
| 第43节 | 在库存服务中实现缓存与数据库双写一致性保障方案(四) |
| 第44节 | 库存服务代码调试以及打印日志观察服务的运行流程是否正确 |
| 第45节 | 商品详情页结构分析、缓存全量更新问题以及缓存维度化解决方案 |
| 第46节 | 缓存数据生产服务的工作流程分析以及工程环境搭建 |
| 第47节 | 完成spring boot整合ehcache的搭建以支持服务本地堆缓存 |
| 第48节 | redis的LRU缓存清除算法讲解以及相关配置使用 |
| 第49节 | zookeeper+kafka集群的安装部署以及如何简单使用的介绍 |
| 第50节 | 基于kafka+ehcache+redis完成缓存数据生产服务的开发与测试 |
| 第51节 | 基于“分发层+应用层”双层nginx架构提升缓存命中率方案分析 |
| 第52节 | 基于OpenResty部署应用层nginx以及nginx+lua开发hello world |
| 第53节 | 部署分发层nginx以及基于lua完成基于商品id的定向流量分发策略 |
| 第54节 | 基于nginx+lua+java完成多级缓存架构的核心业务逻辑(一) |
| 第55节 | 基于nginx+lua+java完成多级缓存架构的核心业务逻辑(二) |
| 第56节 | 基于nginx+lua+java完成多级缓存架构的核心业务逻辑(三) |
| 第57节 | 分布式缓存重建并发冲突问题以及zookeeper分布式锁解决方案 |
| 第58节 | 缓存数据生产服务中的zk分布式锁解决方案的代码实现(一) |
| 第59节 | 缓存数据生产服务中的zk分布式锁解决方案的代码实现(二) |
| 第60节 | 缓存数据生产服务中的zk分布式锁解决方案的代码实现(三) |
| 第61节 | Java程序员、缓存架构以及Storm大数据实时计算之间的关系 |
| 第62节 | 讲给Java工程师的史上最通俗易懂Storm教程:大白话介绍 |
| 第63节 | 讲给Java工程师的史上最通俗易懂Storm教程:大白话讲集群架构与核心概念 |
| 第64节 | 讲给Java工程师的史上最通俗易懂Storm教程:大白话讲并行度和流分组 |
| 第65节 | 讲给Java工程师的史上最通俗易懂Storm教程:纯手敲WordCount程序 |
| 第66节 | 讲给Java工程师的史上最通俗易懂Storm教程:纯手工集群部署 |
| 第67节 | 讲给Java工程师的史上最通俗易懂Storm教程:基于集群运行计算拓扑 |
| 第68节 | 缓存冷启动问题:新系统上线、redis彻底崩溃导致数据无法恢复 |
| 第69节 | 缓存预热解决方案:基于storm实时热点统计的分布式并行缓存预热 |
| 第70节 | 基于nginx+lua完成商品详情页访问流量实时上报kafka的开发 |
| 第71节 | 基于storm+kafka完成商品访问次数实时统计拓扑的开发 |
| 第72节 | 基于storm完成LRUMap中topn热门商品列表的算法讲解与编写 |
| 第73节 | 基于storm+zookeeper完成热门商品列表的分段存储 |
| 第74节 | 基于双重zookeeper分布式锁完成分布式并行缓存预热的代码开发 |
| 第75节 | 将缓存预热解决方案的代码运行后观察效果以及调试和修复所有的bug |
| 第76节 | 热点缓存问题:促销抢购时的超级热门商品可能导致系统全盘崩溃的场景 |
| 第77节 | 基于nginx+lua+storm的热点缓存的流量分发策略自动降级解决方案 |
| 第78节 | 在storm拓扑中加入热点缓存实时自动识别和感知的代码逻辑 |
| 第79节 | 在storm拓扑中加入nginx反向推送缓存热点与缓存数据的代码逻辑 |
| 第80节 | 在流量分发+后端应用双层nginx中加入接收热点缓存数据的接口 |
| 第81节 | 在nginx+lua中实现热点缓存自动降级为负载均衡流量分发策略的逻辑 |
| 第82节 | 在storm拓扑中加入热点缓存消失的实时自动识别和感知的代码逻辑 |
| 第83节 | 将热点缓存自动降级解决方案的代码运行后观察效果以及调试和修复bug |
| 第84节 | hystrix与高可用系统架构:资源隔离+限流+熔断+降级+运维监控 |
| 第85节 | hystrix要解决的分布式系统可用性问题以及其设计原则 |
| 第86节 | 电商网站的商品详情页缓存服务业务背景以及框架结构说明 |
| 第87节 | 基于spring boot快速构建缓存服务以及商品服务 |
| 第88节 | 快速完成缓存服务接收数据变更消息以及调用商品服务接口的代码编写 |
| 第89节 | 商品服务接口故障导致的高并发访问耗尽缓存服务资源的场景分析 |
| 第90节 | 基于hystrix的线程池隔离技术进行商品服务接口的资源隔离 |
| 第91节 | 基于hystrix的信号量技术对地理位置获取逻辑进行资源隔离与限流 |
| 第92节 | hystrix的线程池+服务+接口划分以及资源池的容量大小控制 |
| 第93节 | 深入分析hystrix执行时的8大流程步骤以及内部原理 |
| 第94节 | 基于request cache请求缓存技术优化批量商品数据查询接口 |
| 第95节 | 开发品牌名称获取接口的基于本地缓存的fallback降级机制 |
| 第96节 | 深入理解hystrix的短路器执行原理以及模拟接口异常时的短路实验 |
| 第97节 | 深入理解线程池隔离技术的设计原则以及动手实战接口限流实验 |
| 第98节 | 基于timeout机制来为商品服务接口的调用超时提供安全保护 |
| 第99节 | 基于hystrix的高可用分布式系统架构项目实战课程的总结 |
| 第100节 | 基于request collapser请求合并技术进一步优化批量查询 |
| 第101节 | hystirx的fail-fast与fail-silient两种最基础的容错模式 |
| 第102节 | 为商品服务接口调用增加stubbed fallback降级机制 |
| 第103节 | 基于双层嵌套command开发商品服务接口的多级降级机制 |
| 第104节 | 基于facade command开发商品服务接口的手动降级机制 |
| 第105节 | 生产环境中的线程池大小以及timeout超时时长优化经验总结 |
| 第106节 | 生产环境中的线程池自动扩容与缩容的动态资源分配经验 |
| 第107节 | hystrix的metric统计相关的各种高阶配置讲解 |
| 第108节 | hystrix dashboard可视化分布式系统监控环境部署 |
| 第109节 | 生产环境中的hystrix分布式系统的工程运维经验总结 |
| 第110节 | 高并发场景下恐怖的缓存雪崩现象以及导致系统全盘崩溃的后果 |
| 第111节 | 缓存雪崩的基于事前+事中+事后三个层次的完美解决方案 |
| 第112节 | 基于hystrix完成对redis访问的资源隔离以避免缓存服务被拖垮 |
| 第113节 | 为redis集群崩溃时的访问失败增加fail silent容错机制 |
| 第114节 | 位redis集群崩溃时的场景部署定制化的熔断策略 |
| 第115节 | 基于hystrix限流完成源服务的过载保护以避免流量洪峰打死MySQL |
| 第116节 | 为源头服务的限流场景增加stubbed fallback降级机制 |
| 第117节 | 高并发场景下的缓存穿透导致MySQL压力倍增问题以及其解决方案 |
| 第118节 | 在缓存服务中开发缓存穿透的保护性机制以及代码测试 |
| 第119节 | 高并发场景下的nginx缓存失效导致redis压力倍增问题以及解决方案 |
| 第120节 | 在nginx lua脚本中开发缓存失效的保护性机制以及代码测试 |
| 第121节 | 支撑高并发与高可用的大型电商详情页系统的缓存架构课程总结 |
| 第122节 | 如何将课程中的东西学以致用在自己目前的项目中去应用? |
| 第123节 | 如何带着课程中讲解的东西化为自己的技术并找一份更好的工作? |
以上是关于java架构知识点-大数据与高并发(学习笔记)的主要内容,如果未能解决你的问题,请参考以下文章