完美解决RuntimeError: one of the variables needed for gradient computation has been modified by an inp
Posted LiBiGo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了完美解决RuntimeError: one of the variables needed for gradient computation has been modified by an inp相关的知识,希望对你有一定的参考价值。
正文在后面,往下拉即可~~~~~~~~~~~~
欢迎各位深度学习的小伙伴订阅的我的专栏
Pytorch深度学习·理论篇+实战篇(2023版)专栏地址:
💛Pytorch深度学习·理论篇(2023版) https://blog.csdn.net/qq_39237205/category_12077968.html
https://blog.csdn.net/qq_39237205/category_12077968.html
💚Pytorch深度学习·动手篇(2023版)https://blog.csdn.net/qq_39237205/category_12077994.html
正文开始
【就看这一篇就行】RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [256]] is at version 4; expected version 3 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
针对网上搜到的以下办法均无效的情况:
1)找到网络模型中的 inplace 操作,将inplace=True改成 inplace=False,例如torch.nn.ReLU(inplace=False)
2)将代码中的“a+=b”之类的操作改为“c = a + b”
3)将loss.backward()函数内的参数retain_graph值设置为True, loss.backward(retain_graph=True),如果retain_graph设置为False,计算过程中的中间变量使用完即被释放掉。
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑以上方案无效↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓正确解决方案如下↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1、问题描述:
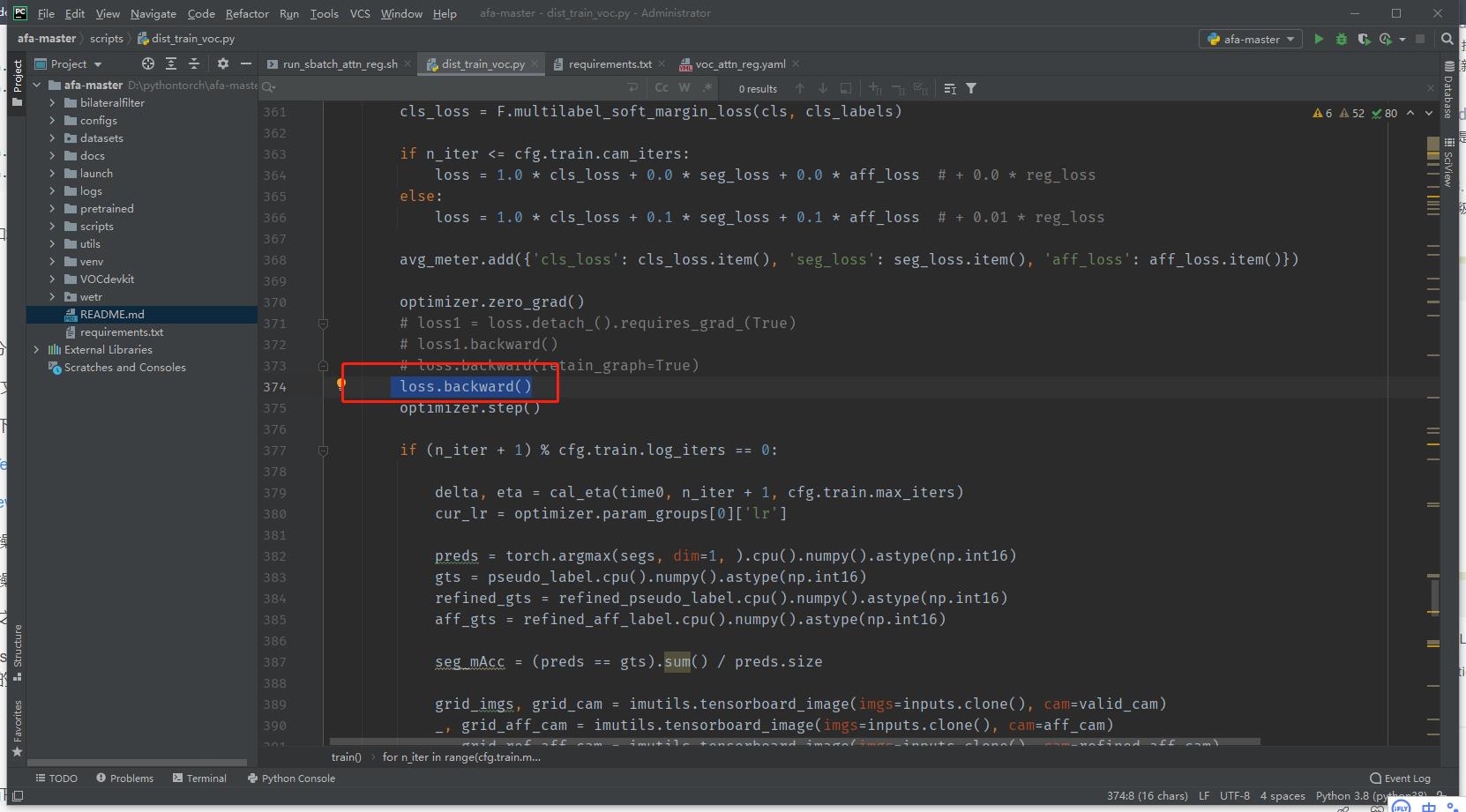
提示在 loss.backward()报错
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [256]] is at version 4; expected version 3 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
2、问题分析
在用PyTorch进行分布式训练时,遇到以上错误。
日志的大概意思是用于梯度计算的变量通过inplace操作被修改。网上的一些解决方法基本是检查模型定义中是否有inplace=True 设置以及+=操作符。但是这两种方案都不能解决遇到的问题。
经过一些调试发现,只有当某些特定情况下才会触发此报错。下面结合一个对比学习的例子(并不是完整的脚本)来简单描述:
import torch
import torch.nn as nn
from torchvision.models import resnet50
def main():
model = resnet50(num_classes=256).cuda()
model = nn.parallel.DistributedDataParallel(model,
device_ids=[args.local_rank],
find_unused_parameters=True)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),
lr=0.001,
momentum=0.99,
weight_decay=1e-4)
for i in range(10):
input0 = torch.randn((4, 3, 224, 224), dtype=torch.float32).cuda()
input2 = torch.randn((4, 3, 224, 224), dtype=torch.float32).cuda()
out1 = model(input0)
out2 = model(input1)
loss = criterion(out1, out2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if __name__ == '__main__':
main()经过调试发现,当使用nn.DataParallel并行训练或者单卡训练均可正常运行;另外如果将两次模型调用集成到model中,即通过out1, out2 = model(input0, input1) 的方式在分布式训练下也不会报错。
由此可以猜测:在分布式训练中,如果对同一模型进行多次调用则会触发以上报错,即
nn.parallel.DistributedDataParallel方法封装的模型,forword()函数和backward()函数必须交替执行,如果执行多个(次)forward()然后执行一次backward()则会报错。
那么解决此问题的入手点则可以聚焦到nn.parallel.DistributedDataParallel接口上。 通过查询PyTorch官方文档发现此接口下的两个参数:
- find_unused_parameters: 如果模型的输出有不需要进行反向传播的,此参数需要设置为True;
若你的代码运行后卡住不动,基本上就是该参数的问题。
- broadcast_buffers: 该参数默认为True,设置为True时,在模型执行forward之前,gpu0会把
buffer中的参数值全部覆盖到别的gpu上。
问题基本可以定位出来了,即broadcast_buffers=True导致参数被覆盖修改。
3、解决办法
# 在该出错文件上找到被调用的DistributedDataParallel(),将broadcast_buffers设置为False
model = nn.parallel.DistributedDataParallel(model,
device_ids=[args.local_rank],
broadcast_buffers=False,
find_unused_parameters=True)RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [2048]] is at version 4; expected version 3 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
使用VGG网络训练发生错误RuntimeError: CUDA out of memory解决方案:
问题
在使用VGG网络训练Mnisist数据集时,发生错误RuntimeError: CUDA out of memory. Tried to allocate 392.00 MiB (GPU 0; 2.00 GiB total capacity; 1.45 GiB already allocated; 0 bytes free; 1.47 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF。
网络
class VGG(nn.Module): # 适用于(128,3,224,224)
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=512 * 7 * 7, out_features=4096),
nn.Linear(in_features=4096, out_features=4096),
nn.Linear(in_features=4096, out_features=1000),
nn.Linear(in_features=1000, out_features=10),
)
def forward(self, x):
out = self.net(x)
return out
报错截图:

方法
尝试1 关闭显卡占用
根据报错(CUDA out of memory.),说明显卡内存不够。于是进入终端查一下memory现在的状态。没有在运行的进程,运行程序错误仍然存在。
尝试2 定时清理内存
在每个训练周期处插入以下代码(定时清内存):
import torch, gc
for epoch in range(100):
...............
gc.collect()
torch.cuda.empty_cache()
尝试3 设置锁页内存pin_memory
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。因为pin_memory与电脑硬件性能有关,pytorch开发者不能确保每一个人都有高端设备,因此pin_memory默认为False。
尝试4 修改batch_size (问题解决)
最简单最直接的方法就是修改batch_size的大小,从而降低对显卡内存的占用。当将batch_size=4时,程序成功运行。
总结
当网路变得复杂的时候,对计算机硬件资源的要求也会随之变高。在本实验之中,就出现了因为VGG网络模型较为复杂,对计算机GPU的资源要求和消耗也随之变大,于是便出现了CUDA out of memory.GPU内存不够而报错的情况。在计算机硬件资源有限的情况下,只有选择降低batch_size的大小,从而达到计算机处理数据的能力之类。但是当batch_size过低训练出来的模型也会因为实际模型的需求出现一定的问题。简而言之batch size过小,需要花费更多时间,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
这里提供一个免费使用高性能GPU的路径,在计算机资源有限前提下,如果能够使用上Google服务器可以将代码上传到Google Calab(Google colab是一个免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。并且可以免费使用Google的GPU)训练,再将训练好结果下载。
以上是关于完美解决RuntimeError: one of the variables needed for gradient computation has been modified by an inp的主要内容,如果未能解决你的问题,请参考以下文章