毕设扫描器参数Fuzz第二篇:动态爬虫的创建启动和协程池
Posted 区块链市场观察家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了毕设扫描器参数Fuzz第二篇:动态爬虫的创建启动和协程池相关的知识,希望对你有一定的参考价值。
文章目录
前言
在 《第一篇:数据的定义、读取和装配(爬虫数据和Payload数据)》文章中,我们完成了 URL 数据的读取、以及 Payload 的加载部分。
接下来要做的是发送请求对象,根据响应对象判断是否存在漏洞。
本篇文章要探究的,就是 CrawlerGo 动态爬虫发送请求和处理的过程,以求为参数 Fuzz 发送请求和处理响应提供参考和借鉴。
Crawlergo发送请求的代码节点
CrawlerGo 为动态爬虫装配数据的代码,前面我们基本阅读完毕。接下来看创建爬虫任务、以及启动爬虫部分的代码,查看具体的实现细节。
// crawlergo_cmd.go 代码 311 行
// 开始爬虫任务
task, err := pkg.NewCrawlerTask(targets, taskConfig)
if err != nil
logger.Logger.Error("create crawler task failed.")
os.Exit(-1)
……
go handleExit(task)
logger.Logger.Info("Start crawling.")
task.Run()
result := task.Result
// 追踪 task.Run()
// task_main.go 代码 173行
/*
开始当前任务
*/
func (t *CrawlerTask) Run()
defer t.Pool.Release() // 释放协程池
defer t.Browser.Close() // 关闭浏览器
// 为 Targets 设置 reqsFromRobots 变量
if t.Config.PathFromRobots
reqsFromRobots := GetPathsFromRobots(*t.Targets[0])
logger.Logger.Info("get paths from robots.txt: ", len(reqsFromRobots))
t.Targets = append(t.Targets, reqsFromRobots...)
// 为 Targets 设置 reqsByFuzz 变量
if t.Config.FuzzDictPath != ""
if t.Config.PathByFuzz
logger.Logger.Warn("`--fuzz-path` is ignored, using `--fuzz-path-dict` instead")
reqsByFuzz := GetPathsByFuzzDict(*t.Targets[0], t.Config.FuzzDictPath)
t.Targets = append(t.Targets, reqsByFuzz...)
else if t.Config.PathByFuzz
reqsByFuzz := GetPathsByFuzz(*t.Targets[0])
logger.Logger.Info("get paths by fuzzing: ", len(reqsByFuzz))
t.Targets = append(t.Targets, reqsByFuzz...)
t.Result.AllReqList = t.Targets[:]
// 创建 Request 对象用于 task 的初始化
var initTasks []*model.Request
// 遍历 Targets 数组
for _, req := range t.Targets
if t.smartFilter.DoFilter(req)
logger.Logger.Debugf("filter req: " + req.URL.RequestURI())
continue
initTasks = append(initTasks, req)
t.Result.ReqList = append(t.Result.ReqList, req)
logger.Logger.Info("filter repeat, target count: ", len(initTasks))
for _, req := range initTasks
if !engine2.IsIgnoredByKeywordMatch(*req, t.Config.IgnoreKeywords)
t.addTask2Pool(req)
t.taskWG.Wait()
// 对全部请求进行唯一去重
todoFilterAll := make([]*model.Request, len(t.Result.AllReqList))
for index := range t.Result.AllReqList
todoFilterAll[index] = t.Result.AllReqList[index]
t.Result.AllReqList = []*model.Request
var simpleFilter filter2.SimpleFilter
for _, req := range todoFilterAll
if !simpleFilter.UniqueFilter(req)
t.Result.AllReqList = append(t.Result.AllReqList, req)
// 全部域名
t.Result.AllDomainList = AllDomainCollect(t.Result.AllReqList)
// 子域名
t.Result.SubDomainList = SubDomainCollect(t.Result.AllReqList, t.RootDomain)
设置代理调试寻找(未抓到包)
(1)设置代理参数,开启 Burpsuite,没抓到 HTTP 数据包。
--request-proxy http://127.0.0.1:8080 --output-json debug.json http://127.0.0.1/sqli-labs-master/Less-1/?id=1
(2)尝试内置 request-proxy 参数,添加 Value 字段设置参数默认值,从控制台截图可以看到设置成功了,但 Burp 仍然没有收到 HTTP 数据包。
&cli.StringFlag
Name: "request-proxy",
Usage: "all requests connect through defined proxy server.",
Value: "http://127.0.0.1:8080",
Destination: &taskConfig.Proxy,
,
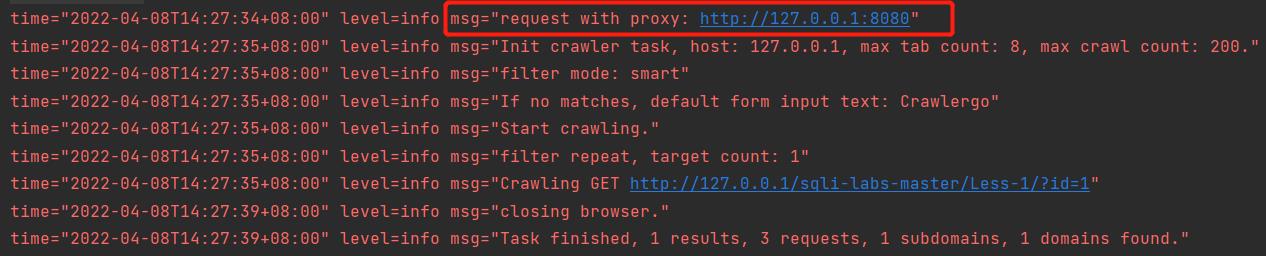
查看 task_main.go 文件,搜索 Proxy,可以看到是在初始化浏览器时加载了代理。
crawlerTask.Browser = engine2.InitBrowser(taskConf.ChromiumPath, taskConf.IncognitoContext, taskConf.ExtraHeaders, taskConf.Proxy, taskConf.NoHeadless)
crawlerTask.RootDomain = targets[0].URL.RootDomain()
WireShark本地抓包(找到代码节点)
参考文章:wireShark抓取本地http包,分析状态。
前往 Npcap官网 下载安装包,安装时记得勾选 Adapter for lookback traffic capture 选项。打开 WireShark 选择该过滤器监听。
调试 CrawlerGo,观察执行哪一部分代码后 HTTP 请求中出现了目标网站的访问记录。

经过简单对比,发现执行 t.taskWG.Wait() 代码后发送HTTP请求。
// 追踪 task.Run()
// task_main.go 代码 173行
/*
开始当前任务
*/
func (t *CrawlerTask) Run()
defer t.Pool.Release() // 释放协程池
defer t.Browser.Close() // 关闭浏览器
// 为 Targets 设置 reqsFromRobots 变量
// 为 Targets 设置 reqsByFuzz 变量
t.Result.AllReqList = t.Targets[:]
// 创建 Request 对象用于 task 的初始化
// 遍历 Targets 数组
// 遍历初始化任务
for _, req := range initTasks
if !engine2.IsIgnoredByKeywordMatch(*req, t.Config.IgnoreKeywords)
t.addTask2Pool(req)
t.taskWG.Wait()
// 对全部请求进行唯一去重
todoFilterAll := make([]*model.Request, len(t.Result.AllReqList))
for index := range t.Result.AllReqList
todoFilterAll[index] = t.Result.AllReqList[index]
CrawlerGo设置多线程爬虫
爬虫调用代码
// crawlergo_cmd.go 代码 312 行
// 开始爬虫任务
task, err := pkg.NewCrawlerTask(targets, taskConfig)
if err != nil
logger.Logger.Error("create crawler task failed.")
os.Exit(-1)
……
go handleExit(task)
logger.Logger.Info("Start crawling.")
task.Run()
result := task.Result
创建爬虫任务
分析代码,该部分主要操作了如下三部分内容:
- 给爬虫任务装配数据
- 以无头模式启动浏览器
- 创建协程池并设置最大协程数量
// 开始爬虫任务
task, err := pkg.NewCrawlerTask(targets, taskConfig)
// task_main.go 代码 70 行
/**新建爬虫任务
接收配置好的 Request 、TaskConfig 对象
*/
func NewCrawlerTask(targets []*model.Request, taskConf TaskConfig) (*CrawlerTask, error)
// 定义爬虫任务的数据类型:字典
crawlerTask := CrawlerTask
Result: &Result,
Config: &taskConf,
smartFilter: filter2.SmartFilter
SimpleFilter: filter2.SimpleFilter
HostLimit: targets[0].URL.Host,
,
,
// 单个目标,测试也使用单目标站点
// 定义 newReq 接收 targets[0],确定通信协议
if len(targets) == 1
_newReq := *targets[0]
newReq := &_newReq
_newURL := *_newReq.URL
newReq.URL = &_newURL
// 首先确定站点使用的通信协议
if targets[0].URL.Scheme == "http"
newReq.URL.Scheme = "https"
else
newReq.URL.Scheme = "http"
// 把配置好的 newReq 再添加到 targets,此时 Targets 有两个目标信息的元素
targets = append(targets, newReq)
// 把 Targets 添加到 crawlerTask/爬虫任务的字典
crawlerTask.Targets = targets[:]
// 设置请求对象的 source 为常量 "Target"
for _, req := range targets
req.Source = config.FromTarget
// 装配形式参数变量 Taskconfig
// 设置 TaskConfig 即 taskConf 的变量,如果未设置则使用默认值
设置 taskConf 的 变量
.TabRunTimeout
.MaxTabsCount
.FilterMode
.MaxCrawlCount
.DomContentLoadedTimeout
.EventTriggerInterval
.BeforeExitDelay
.EventTriggerMode
.IgnoreKeywords
// 设置请求头变量
if taskConf.ExtraHeadersString != ""
err := json.Unmarshal([]byte(taskConf.ExtraHeadersString), &taskConf.ExtraHeaders)
if err != nil
logger.Logger.Error("custom headers can't be Unmarshal.")
return nil, err
// 以无头模式开启 chrome.exe
crawlerTask.Browser = engine2.InitBrowser(taskConf.ChromiumPath, taskConf.IncognitoContext, taskConf.ExtraHeaders, taskConf.Proxy, taskConf.NoHeadless)
// 设置爬虫任务的根域名
crawlerTask.RootDomain = targets[0].URL.RootDomain()
// 初始化智能过滤器
crawlerTask.smartFilter.Init()
// 创建协程池
// 创建协程池,并且把协程池保存到爬虫任务的 Pool 键
p, _ := ants.NewPool(taskConf.MaxTabsCount)
crawlerTask.Pool = p
// 爬虫任务完成数据装配、无头模式启动浏览器、创建协程池
return &crawlerTask, nil
启动爬虫任务
代码把请求对象添加到线程池,然后等待异步线程执行结束。
task_main.go 代码 210 行的函数 t.addTask2Pool(req),继续追溯。
// crawlergo_cmd.go
task.Run()
/*
开始当前任务
*/
func (t *CrawlerTask) Run()
defer t.Pool.Release() // 释放协程池
defer t.Browser.Close() // 关闭浏览器
是否从 robots.txt 获取信息,如果是则把信息添加到 t.Targets 对象
是否 Fuzz 目录,如果是则读取字典文件并添加到 t.Targets 对象
// 创建数组对象 AllReqList
t.Result.AllReqList = t.Targets[:]
// 创建 Request 类型的初始化任务变量
var initTasks []*model.Request
for _, req := range t.Targets
if t.smartFilter.DoFilter(req)
logger.Logger.Debugf("filter req: " + req.URL.RequestURI())
continue
// 从 t.Targets 对象中获取请求对象
initTasks = append(initTasks, req)
t.Result.ReqList = append(t.Result.ReqList, req)
logger.Logger.Info("filter repeat, target count: ", len(initTasks))
// 遍历初始化任务数组的请求对象,逐个添加到协程池
for _, req := range initTasks
if !engine2.IsIgnoredByKeywordMatch(*req, t.Config.IgnoreKeywords)
t.addTask2Pool(req)
// 运行则发送请求
// 等待异步线程执行完成
t.taskWG.Wait()
// 对全部请求进行唯一去重
todoFilterAll := make([]*model.Request, len(t.Result.AllReqList))
for index := range t.Result.AllReqList
todoFilterAll[index] = t.Result.AllReqList[index]
t.Result.AllReqList = []*model.Request
var simpleFilter filter2.SimpleFilter
for _, req := range todoFilterAll
if !simpleFilter.UniqueFilter(req)
t.Result.AllReqList = append(t.Result.AllReqList, req)
// 全部域名
t.Result.AllDomainList = AllDomainCollect(t.Result.AllReqList)
// 子域名
t.Result.SubDomainList = SubDomainCollect(t.Result.AllReqList, t.RootDomain)
把任务添加到线程池
// task_main.go,t.addTask2Pool()位于 210 行
/*开始当前任务*/
func (t *CrawlerTask) Run()
……
// 遍历初始化任务数组的请求对象,逐个添加到协程池
for _, req := range initTasks
if !engine2.IsIgnoredByKeywordMatch(*req, t.Config.IgnoreKeywords)
t.addTask2Pool(req)
// 追溯 t.addTask2Pool(req),同文件代码 240 行
/**
添加任务到协程池
添加之前实时过滤
*/
func (t *CrawlerTask) addTask2Pool(req *model.Request)
// 协程相关代码
t.taskCountLock.Lock()
if t.crawledCount >= t.Config.MaxCrawlCount
t.taskCountLock.Unlock()
return
else
t.crawledCount += 1
t.taskCountLock.Unlock()
t.taskWG.Add(1)
// 传入请求对象(字典类型),追溯 t.generateTabTask(req) ,发现根据请求列表生成tabTask协程任务列表
/* 实际上又嵌套了一层字典,字典结构如下所示
task := tabTask
crawlerTask: t,
browser: t.Browser,
req: req,
*/
task := t.generateTabTask(req)
// 测试时F7单步调试,发现跳过了该部分代码
// 查询资料发现,该部分代码作用是:以并发的方式调用匿名函数func
go func()
// 提交协程任务执行
err := t.Pool.Submit(task.Task)
if err != nil
t.taskWG.Done()
logger.Logger.Error("addTask2Pool ", err)
()
// 追溯关键代码 t.Pool.submit(task.Task)
在 t.Pool.submit(task.Task) 后添加打印提示信息的代码,发现打印了提示信息
在该处下断点,进行单步调试
发现使用F7或F8进行单步调试时,不会在该段代码的断点停留
使用"运行到光标处",才会在该段代码的断点停留,
然后就会执行 Run() 里面的代码:t.taskWG.Wait(),此时请求已经发送
单步调试跟踪 t.taskWG.Wait(),发现的函数调用如下:
task.Run() crawlergo_cmd.go
->t.taskWG.Wait() task_main.go
-> Wait() src/sync/waitgroup.go
->runtime_Semacquire(semap) src/sync/waitgroup.go
->sync_runtime_Semacquire() src/runtime/sema.go
F7步入执行该代码,此时会运行t.Pool.submit()并发送请求。
也就是说,执行 t.taskWG.Wait()函数过程中,会执行 t.Pool.submit(),然后会执行协程任务。
插个眼:注意func (t *tabTask) Task()
重要函数表格
创建爬虫任务
| 所属文件 | 函数 | 说明 |
|---|---|---|
| crawlergo_cmd.go | task, err := pkg.NewCrawlerTask(targets, taskConfig) | 创建爬虫任务 |
| task_main.go | engine2.InitBrowser(xx) | 以无头模式启动浏览器 chrome.exe |
| - | ants.NewPool(taskConf.MaxTabsCount) | 创建协程池 |
接着梳理协程任务的执行
关键代码:task_main.go 文件 代码 253 行。
go func()
// 每个 goroutine 调用 task.Task() 函数,目前不清楚为什么不是使用 task.Task(),可能是语法
err := t.Pool.Submit(task.Task)
fmt.Println(task.Task)
fmt.Println("t.Pool.Submit")
if err != nil
t.taskWG.Done()
logger.Logger.Error("addTask2Pool ", err)
()
启动 goroutine 执行操作
参考《Go in Action》第二章:一个 goroutine 是一个独立于其他函数运行的函数。使用关键字 go 启动一个 goroutine,并对这个 goroutine 做并发调度。代码使用关键字 go 启动了一个匿名函数作为 goroutine,这样可以并发地独立处理每个数据源的数据。
匿名函数内部包含了每个 goroutine 要完成的任务,此处是 t.Pool.Submit(task.Task)。
参考文章:ants:在Submit中再调用当前Pool的Submit可能导致阻塞,关于协程池 Pool。
goroutine pool减小开销的主要思路就是复用。即创建出的goroutine在做完一个task后不退出,而是等待下一个task,这样来减少goroutine反复创建和销毁带来的开销。
goroutine 的操作:task.Task
查看每个 goroutine 执行的操作,分析代码部分见注释内容。
// task_main.go 代码 264 行
/**
单个运行的tab标签任务,实现了workpool的接口
*/
func (t *tabTask) Task()
// 《Go in Action》第二章: