单目稠密深度图(vins mono可用)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了单目稠密深度图(vins mono可用)相关的知识,希望对你有一定的参考价值。
参考技术A在本文中,我们提出了一种新的机器人导航建图方法。通过使用单目局部移动相机 ,高质量的稠密深度图被实时估计及融合到3D重建中。 光强图像的四叉树结构用于通过以多种分辨率估计深度图来减少计算负担。 提出了基于四叉树的像素选择和动态置信传播以加速建图过程:根据四叉树中的水平,利用计算资源选择和优化像素。 求解的深度估计被进一步插值并在时间上融合到全分辨率深度图中,并使用截断的带符号距离函数(TSDF)融合到密集的3D图中。我们使用公共数据集将我们的方法与其他最先进的方法进行比较。 板载无人机自主飞行还用于进一步证明我们的方法在便携式设备上的可用性和效率。 为了大众的利益,该算法开源发布在“ https://github.com/ HKUST-Aerial-Robotics /open_quadtree_mapping”。
摄像机广泛用于机器人系统,因为它们提供有关环境的信息数据,同时保持低功耗并产生小的占地面积。具体来说,我们对单目视觉惯性系统[1] [2]感兴趣,因为它们可以使用单个摄像机和惯性测量单元(IMU)的最小传感器组为机器人提供导航所需的信息。然而,为定位而构建的稀疏或半密集地图不足以完成诸如避障等任务。为了感知周围环境,通常使用RGB-D相机,激光雷达或立体相机等附加传感器。然而,这些传感器的重量,尺寸和功耗使得它们不适用于有效载荷和功率有限的机器人。在本文中,我们提出了一种单目稠密建图方法,可以使用单个局部移动摄像机实时估计高质量深度图并实时建立稠密3D模型,如图1所示。
生成高质量稠密深度图是单目稠密建图系统的关键步骤。 为了应用于机器人,深度图估计必须在时间上有效并且密集地覆盖包括低纹理区域的图像。 我们的方法受到单目深度估计的两个观察的启发:
(1)考虑到块匹配成本和深度图平滑度,通常需要通过最小化一个能量函数来估计低纹理区域的深度并平滑深度图的全局优化[5],[6]。然而,昂贵的计算使它们无法在实时应用中广泛使用。
(2)在强度图像的相同四叉树块内的像素共享相似的光强和深度值。四叉树结构被广泛使用(例如,在图像编码[7]中),像素根据其局部纹理以树结构组织:具有相似强度值的像素可以通过将它们分配到相同的四叉树块并且在相应的决议。如图2所示,在大多数情况下,强度图像中的像素的四叉树水平等于或者比深度图像中的更高。这意味着在强度图像中共享相同四叉树块的像素也属于深度图像中的相同块,因此共享相似的深度值,但反之亦然。换句话说,像素的深度可以以与强度图像中的四叉树水平相对应的分辨率来表示。
受这两个观察的启发,我们提出了一种新颖的单目稠密建图方法,该方法使用单个局部移动摄像机估计稠密深度图并构建3D重建。 通过全局优化改善了深度密度和精度,并且通过估计与强度图像的四叉树结构相对应的多个分辨率中的深度图来减少计算负担。 具体而言,根据它们的四叉树水平选择像素,其密度与它们需要估计的分辨率成比例。 动态置信传播(Dynamic belief propagation)用于以粗到细的方式估计所选像素的深度,其中以相应的分辨率提取深度以获得效率。 所有深度估计都被内插到完整的密集深度图中,并在时间上与前深度图融合。 最后,深度图融合成高质量的全局3D地图。
我们使用公共数据集将我们的工作与其他最先进的单目稠密建图方法进行比较。 不同环境下的机载自主飞行也用于证明我们的方法在无人机应用中的可用性。 我们的方法的贡献如下:
①一种新颖的像素选择方法,根据图像的四叉树结构中的水平选择像素来估计深度。 所选像素分布在整个图像上,并引起对高纹理区域的更多关注。
②动态信任传播,以粗略到精细的方式估计所选像素的深度。 像素根据其四叉树水平利用计算资源进行优化。 优化产生高质量深度估计,同时通过跳过粗分辨率像素来保持效率。
③一种单目稠密建图系统,仅使用局部移动摄像机即可实时生成高质量的密集深度图。 如实验和补充视频所示,深度图可以直接融合到3D地图中,用于3D重建和无人机自主飞行。 该系统也作为社区的开源发布。
已经提出了许多方法来解决单目稠密建图问题。
在计算机视觉中,使用图像重建环境的问题也称为运动结构(SfM)。 给定一系列图像,SfM重建环境结构并估计相机运动。 虽然取得了令人瞩目的成果,但结果通常很少,需要离线处理。 另一方面,我们的方法使用图像和相应的相机运动来实时地密集地重建环境。
DTAM [8],VI-MEAN [9]和REMODE [10]是使用全局或半全局信息解决稠密建图问题的方法。 DTAM [8]通过累积多个帧来构建成本量,并使用总变差优化来提取深度图。 VI-MEAN [9]使用半全局匹配[11](SGM)来规范成本量。 然而,4路径优化导致VI-MEAN估计深度图中的“条纹”伪像[9]。 REMODE [10]使用总变差来平滑通过概率更新估计的深度图像。 由于优化不像DTAM [8]那样在成本量中搜索深度,因此REMODE [10]无法很好地处理低纹理区域。
MonoFusion [12],MobileFusion [13]和3D建模[14]从双视图立体匹配构建稠密地图。 将每个输入图像与选定的测量帧进行比较。 尽管双视图匹配很快,但这些方法在单目情况下包含许多异常值。 后处理技术,例如左右一致性检查,大量成本消除,随时间的一致性,用于处理问题。
多级映射(Multi-level mapping)[15]是与我们的工作最相似的方法。 在多级映射[15]中,四叉树结构用于增加补丁的局部纹理,以便可以使用本地信息估计更多像素。 然后执行总变差优化以从多分辨率平滑深度图。 该方法是有效的并且增加了深度图的密度。 多级映射[15]和我们的方法之间最重要的区别是估计深度图的密度。 使用全局优化,我们的方法可以恢复纹理低,甚至没有纹理的区域的深度。 另一方面,多级映射[15]使用局部强度信息估计像素的深度。 因此,仅可以估计具有足够梯度的像素的深度。 估计的深度图的密度对于机器人应用的安全性和3D重建的完整性是重要的。
受到图像的四叉树结构与相应深度图之间的关系的启发,我们的方法解决了多分辨率的深度估计,并将它们融合成高质量的全分辨率深度图和稠密网格。
定义T w,k ∈SE(3)为世界坐标系w下拍摄第k张图像时相机的位置(pose)。
定义第k张光强图像为I k :Ω⊂R 2 →R
通过相机投影公式π(x c )=u,一个相机坐标系下的3D点x c =(x,y,z) T 可以投影成图像上的一个像素u:=(u,v) T ∈Ω
一个像素可以反投影回相机坐标系c到点x c =π -1 (u,d),其中d是像素的深度(depth)
在接下来的部分中,T w,k 由单目-惯性系统或数据集提供,我们假设相机姿势是准确的并且对于每个帧都是固定的,将来不会改变,这是典型的视觉测距系统的情况。 用闭环系统重建环境超出了本文的范围。
系统的输入为I i 及其对应的相机位置T w,i ,对于每张输入图像I k ,使用I k 作为参考图像和多个之前输入的图像来估计深度图(depth map)。
我们使用四叉树为每个像素找到最合适的分辨率表示。 对于每个输入图像I k ,我们计算3级四叉树结构,其中最精细的级别对应于4×4像素块,最粗糙的级别对应于16×16像素块。 如图2所示,四叉树的同一块中的像素共享相似的强度,因此可以一起估计深度值。 选择四叉树块中的第一个像素以构建匹配成本向量并使用动态置信传播来估计深度(construct the matching cost vector and estimate the depth using dynamic belief propagation)。 图4示出了基于图像的四叉树结构选择像素的示例。
对于在该步骤中未选择的像素,将通过第IV-E部分中的内插和融合来获得它们的深度估计。 根据强度图像的四叉树结构选择像素使我们能够以高效率求解深度图而不会牺牲很多精度。
计算四叉树选择像素的匹配成本向量以用于动态置信传播。 我们的方法选择五个先前的附近帧作为测量帧。 在这项工作中,我们采样均匀分布在逆深度空间上的N d 深度值。 采样深度d和相应的深度索引l具有以下关系:
P1和P2控制深度图的平滑度,如SGM中所示。 注意,虽然公式6与SGM [11]中的公式相同,但消息更新和传递是不同的。 SGM沿着几个预定义的1D路径迭代成本,而我们的方法在2D图像网格上传递消息。 2D全局优化使我们的方法能够在SGM中生成没有“条纹”伪像的平滑深度图。 在并行缩减操作的帮助下,将消息从像素p更新到像素q可以加速到O(log(Nd))时间。 算法1显示了在O(log(Nd))时间内更新像素消息的方法。 使用算法1并行更新消息。
尽管四叉树选择像素的深度估计在图像上扩散,但它不是完全密集深度估计。 在本节中,我们首先将估计内插到完整的密集深度图中,然后以概率方式将它们与之前的结果在时间上融合。
1)深度插值:在插值期间,为了进一步利用包含高梯度纹理但不是四叉树采样的像素,我们使用类似于Eigen等人的方法估计这些像素的深度[16]。 高梯度估计在GPU上完全并行化,并且需要大约2ms来更新一帧。
来自动态置信传播和来自高梯度估计的深度估计被组合并在空间上内插到对应于输入帧Ik的全分辨率深度图Dk中。 通过动态置信传播和高梯度估计估计的深度覆盖整个图像并且更多地关注纹理丰富的区域。 插值估计得到完全密集的结果是解决光流的常用方法[17]。 在这里,我们通过最小化least-square cost来提取全密集深度图。
最小化成本E在计算上是昂贵的。 在这里,我们采用Min等人的方法。 [18]近似于两个一维插值问题中的问题。 通过高斯消元可以有效地解决一维中的深度插值。 我们首先在行方向上插入深度,然后在列方向上插入深度。
2)时间融合:全密集深度图以概率方式与先前的估计进一步融合,以拒绝异常值估计。 使用由Vogiatzis等人提出的异常值鲁棒模型对每个像素的估计进行建模[19]。
使用Klingensmith等人提出的方法将过滤的深度融合到全局图中。[20]。 由于动态可信度传播,插值和时间深度融合,我们的深度估计包含非常少的异常值,因此我们直接融合输出而无需任何额外的滤波器。
我们的方法与GPU加速完全并行化。 即使对于便携式设备,例如Nvidia Jetson TX1,效率也使得3D重建能够实时运行。 下面列出的参数值是根据经验找到的,我们发现它们在所有实验中都能很好地工作。 这可以解释为使用对不同图像内容稳健的全局优化来估计深度图。
输入图像强度在0和1之间缩放,以避免潜在的数字问题。 在IV-C部分中计算匹配成本矢量期间,计算Nd = 64深度值,dmin = 0.5m,dmax = 50.0m。 在第IV-D节中,P1和P2分别设置为0:003和0:01,以平衡估计的深度图的平滑度和不连续性。
VINS简介与代码结构
VINS-Mono和VINS-Mobile是香港科技大学沈劭劼团队开源的单目视觉惯导SLAM方案。是基于优化和滑动窗口的VIO,使用IMU预积分构建紧耦合框架。并且具备自动初始化,在线外参标定,重定位,闭环检测,以及全局位姿图优化功能。
方案最大的贡献是构建了效果很好的融合算法,视觉闭环等模块倒是使用了较为常见的算法。
系列博客将结合课题组发表的paper,从代码层面,逐步剖析系统的各个模块,达到对单目VIO整体的把握,帮助自己理解各类算法,并开发出针对应用场景的视觉惯导SLAM系统。最终目标是使用在AR应用中(Android)。
系统pipeline

主要分为五部分
1. 传感器数据处理:
- 单目相机Monocular Camera: Feature detection and Tracking
- IMU: Pre-integration
2. 初始化:
- 仅使用视觉构建SfM
- 将SfM结果和IMU预积分结果对齐
3. 基于滑动窗口的非线性优化:
4. 闭环检测:
5. 4自由度全局位姿图优化:
主要依赖的库只有OpenCV, Eigen和Ceres Solver,代码目录如下
核心算法都在feature_tracker和vins_estimator包中。
按照REDEME步骤跑EuRoC/MH_05_difficult.bag录好的数据结果如下:
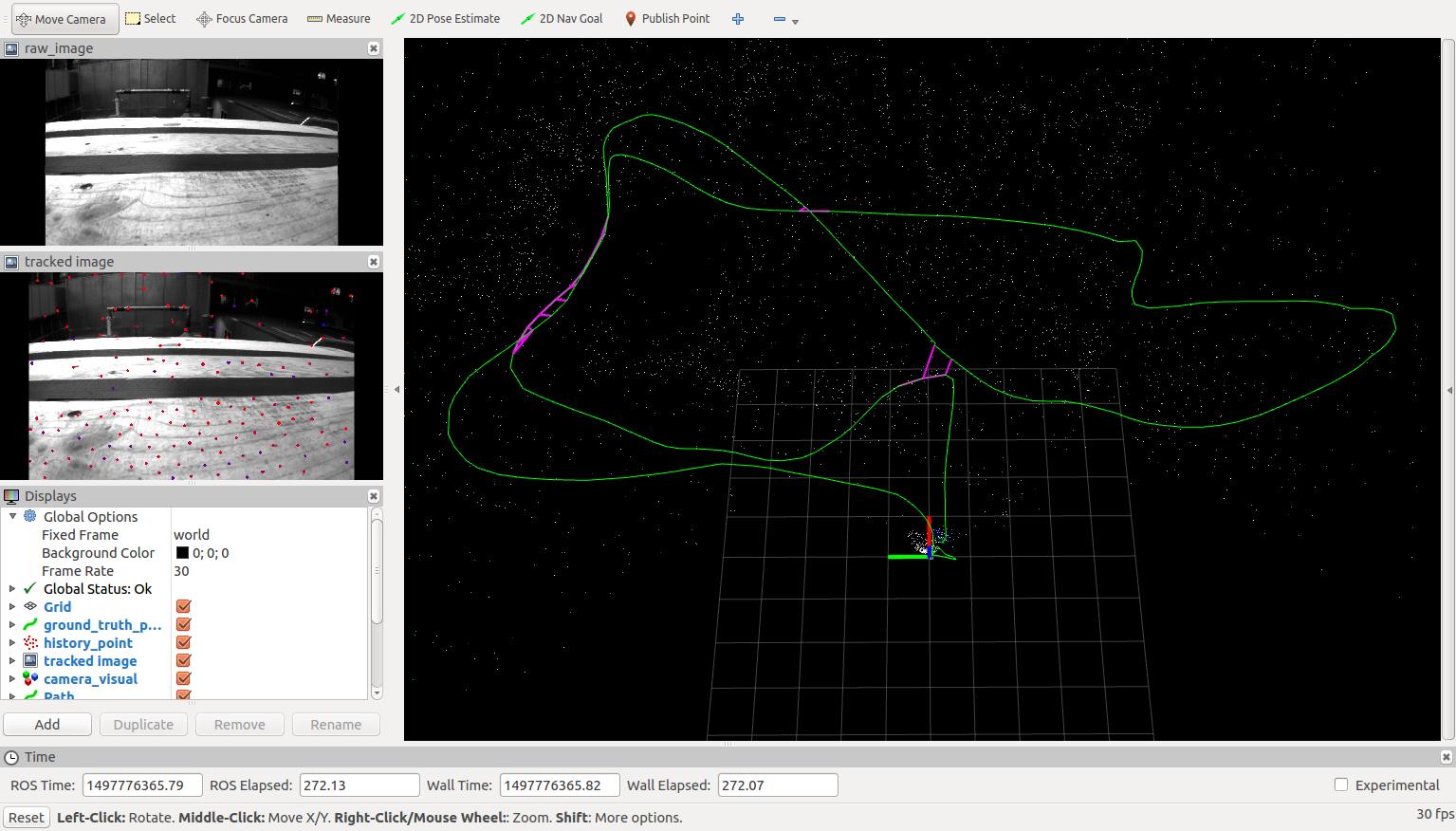
使用rqt_graph得到系统的node和topic关系:

rosbag将记录好的imu数据和单目相机获取的图像数据分别发布到/imu0和/cam0/image_raw话题;/feature_tracker节点通过订阅/cam0/image_raw话题获取图像数据,/vins_estimator节点通过订阅/imu0话题获取imu数据,同时/feature_tracker节点将提取出的图像特征发布到/feature_tracker/feature话题,由/vins_estimator订阅获取。
因此,/feature_tracker节点负责视觉提取和跟踪,/vins_estimator则是融合系统的主要部分。
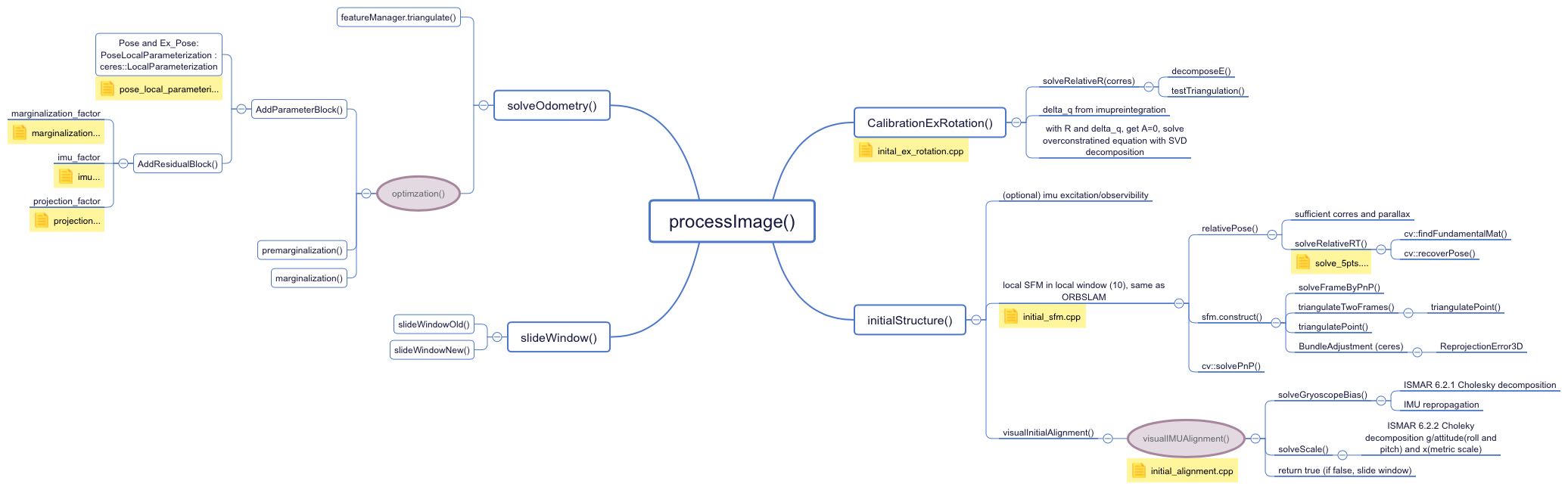
为了方便看代码,整理了一下各个部分架构图(更新中):
processImage():
以上是关于单目稠密深度图(vins mono可用)的主要内容,如果未能解决你的问题,请参考以下文章