paddle detection 配置文件怎么实例化的 代码梳理 -----(regiester)
Posted 东东就是我
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paddle detection 配置文件怎么实例化的 代码梳理 -----(regiester)相关的知识,希望对你有一定的参考价值。
继续上一篇我们讲了通过yaml配置文件实例化类,其中配置文件要加上“!”这个符号,如果没有这个符号的其他类是怎么注册实例化的呢?
我们看到代码workspace.py中
def register(cls):
"""
Register a given module class.
Args:
cls (type): Module class to be registered.
Returns: cls
"""
if cls.__name__ in global_config:
raise ValueError("Module class already registered: ".format(
cls.__name__))
if hasattr(cls, '__op__'):
cls = make_partial(cls)
global_config[cls.__name__] = extract_schema(cls)
return cls
这个函数就是每个类的装饰器,他干啥了呢,一句话就是他把类名和类的地址放在全局变量的字典里了
下面具体分析
1.类上加上装饰器

我们发现每个类上都有这个装饰器register,
装饰器获取cls名, cls.name 那么extract_schema是干嘛
2.根据类名和参数保存在另一个类schemadict中
def extract_schema(cls):
"""
Extract schema from a given class
Args:
cls (type): Class from which to extract.
Returns:
schema (SchemaDict): Extracted schema.
"""
ctor = cls.__init__
# python 2 compatibility
if hasattr(inspect, 'getfullargspec'):
argspec = inspect.getfullargspec(ctor)
annotations = argspec.annotations
has_kwargs = argspec.varkw is not None
else:
argspec = inspect.getfullargspec(ctor)
# python 2 type hinting workaround, see pep-3107
# however, since `typeguard` does not support python 2, type checking
# is still python 3 only for now
annotations = getattr(ctor, '__annotations__', )
has_kwargs = argspec.varkw is not None
names = [arg for arg in argspec.args if arg != 'self']
defaults = argspec.defaults
num_defaults = argspec.defaults is not None and len(argspec.defaults) or 0
num_required = len(names) - num_defaults
docs = cls.__doc__
if docs is None and getattr(cls, '__category__', None) == 'op':
docs = cls.__call__.__doc__
try:
docstring = doc_parse(docs)
except Exception:
docstring = None
if docstring is None:
comments =
else:
comments =
for p in docstring.params:
match_obj = re.match('^([a-zA-Z_]+[a-zA-Z_0-9]*).*', p.arg_name)
if match_obj is not None:
comments[match_obj.group(1)] = p.description
schema = SchemaDict()
schema.name = cls.__name__
schema.doc = ""
if docs is not None:
start_pos = docs[0] == '\\n' and 1 or 0
schema.doc = docs[start_pos:].split("\\n")[0].strip()
# XXX handle paddle's weird doc convention
if '**' == schema.doc[:2] and '**' == schema.doc[-2:]:
schema.doc = schema.doc[2:-2].strip()
schema.category = hasattr(cls, '__category__') and getattr(
cls, '__category__') or 'module'
schema.strict = not has_kwargs
schema.pymodule = importlib.import_module(cls.__module__)
schema.inject = getattr(cls, '__inject__', [])
schema.shared = getattr(cls, '__shared__', [])
for idx, name in enumerate(names):
comment = name in comments and comments[name] or name
if name in schema.inject:
type_ = None
else:
type_ = name in annotations and annotations[name] or None
value_schema = SchemaValue(name, comment, type_)
if name in schema.shared:
assert idx >= num_required, "shared config must have default value"
default = defaults[idx - num_required]
value_schema.set_default(SharedConfig(name, default))
elif idx >= num_required:
default = defaults[idx - num_required]
value_schema.set_default(default)
schema.set_schema(name, value_schema)
return schema
这段代码就是获取cls的参数和地址,也就是cls.model 保存在schema 这个类中
这个类的定义在下面
class SchemaDict(dict):
def __init__(self, **kwargs):
super(SchemaDict, self).__init__()
self.schema =
self.strict = False
self.doc = ""
self.update(kwargs)
def __setitem__(self, key, value):
# XXX also update regular dict to SchemaDict??
if isinstance(value, dict) and key in self and isinstance(self[key],
SchemaDict):
self[key].update(value)
else:
super(SchemaDict, self).__setitem__(key, value)
def __missing__(self, key):
if self.has_default(key):
return self.schema[key].default
elif key in self.schema:
return self.schema[key]
else:
raise KeyError(key)
def copy(self):
newone = SchemaDict()
newone.__dict__.update(self.__dict__)
newone.update(self)
return newone
def set_schema(self, key, value):
assert isinstance(value, SchemaValue)
self.schema[key] = value
def set_strict(self, strict):
self.strict = strict
def has_default(self, key):
return key in self.schema and self.schema[key].has_default()
def is_default(self, key):
if not self.has_default(key):
return False
if hasattr(self[key], '__dict__'):
return True
else:
return key not in self or self[key] == self.schema[key].default
def find_default_keys(self):
return [
k for k in list(self.keys()) + list(self.schema.keys())
if self.is_default(k)
]
def mandatory(self):
return any([k for k in self.schema.keys() if not self.has_default(k)])
def find_missing_keys(self):
missing = [
k for k in self.schema.keys()
if k not in self and not self.has_default(k)
]
placeholders = [k for k in self if self[k] in ('<missing>', '<value>')]
return missing + placeholders
def find_extra_keys(self):
return list(set(self.keys()) - set(self.schema.keys()))
def find_mismatch_keys(self):
mismatch_keys = []
for arg in self.schema.values():
if arg.type is not None:
try:
check_type(".".format(self.name, arg.name),
self[arg.name], arg.type)
except Exception:
mismatch_keys.append(arg.name)
return mismatch_keys
def validate(self):
missing_keys = self.find_missing_keys()
if missing_keys:
raise ValueError("Missing param for class<>: ".format(
self.name, ", ".join(missing_keys)))
extra_keys = self.find_extra_keys()
if extra_keys and self.strict:
raise ValueError("Extraneous param for class<>: ".format(
self.name, ", ".join(extra_keys)))
mismatch_keys = self.find_mismatch_keys()
if mismatch_keys:
raise TypeError("Wrong param type for class<>: ".format(
self.name, ", ".join(mismatch_keys)))
他继承了dict类

最重要的两个操作,importlib.import_module 是动态获取cls的地址。
这样全局变量global_config 里面就存储了很多键值对,

每个valu就是schemadict类型,里存放文件的地址
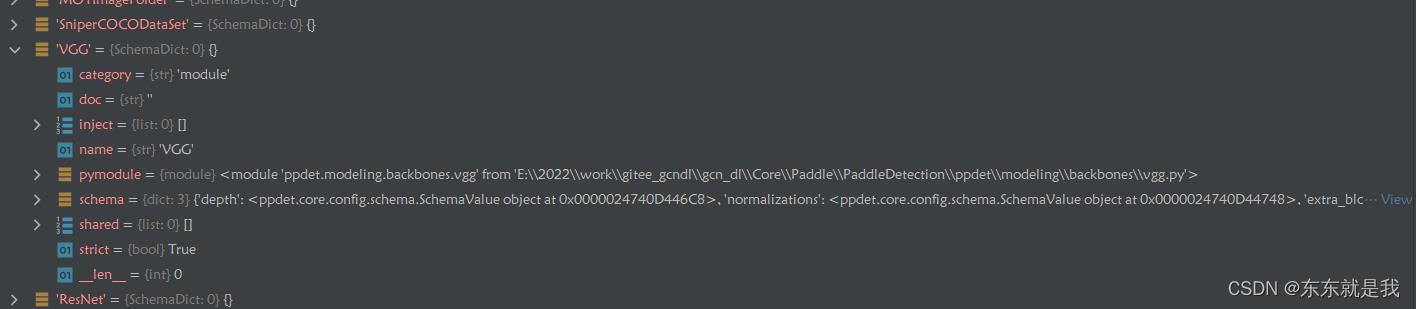
3.实例话
那么在什么时候实例化的
1,首先train.py 中的
cfg = load_config(FLAGS.config) 这句会把yaml配置文件中带!的类实例化放进global_config中。其他的200多的类在文件运行的时候就放进global_config中,也就是上面的部分。那么剩下的类只是放进global_config中,并没有实例化。

在 trainer.py中

也就是在create中 执行了,

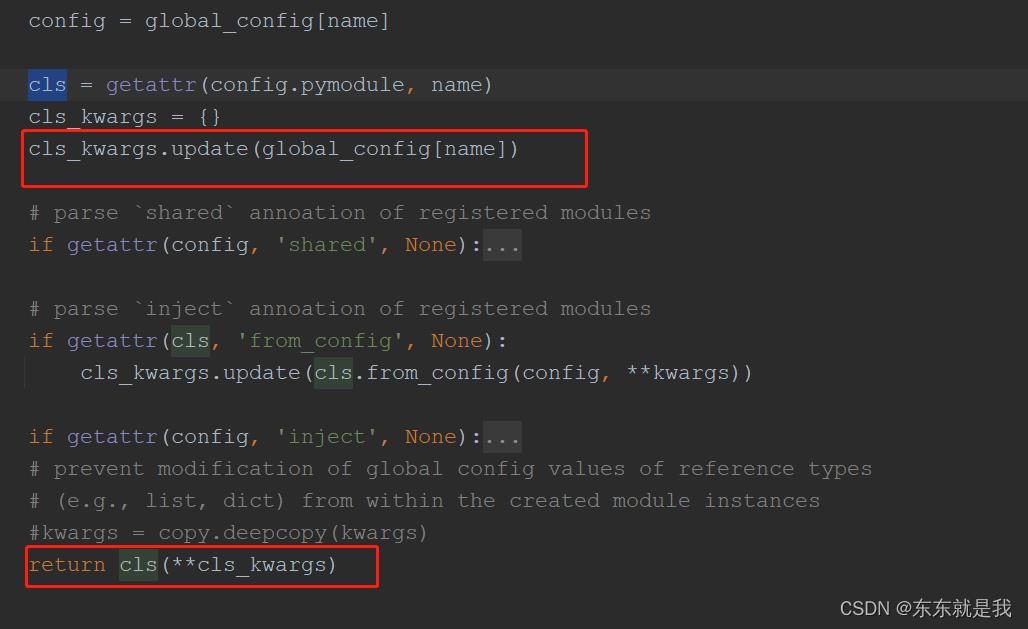
那么参数里面包含另一个类怎么实例化呢,比如yolov3 包含了 resnet 、ppyolofpn、head等

yolov3类中有一个变量叫做 inject = [‘post_process’] ,这个保存在shemdict的inject中


还是在creat函数中,上面我隐藏的getattr中
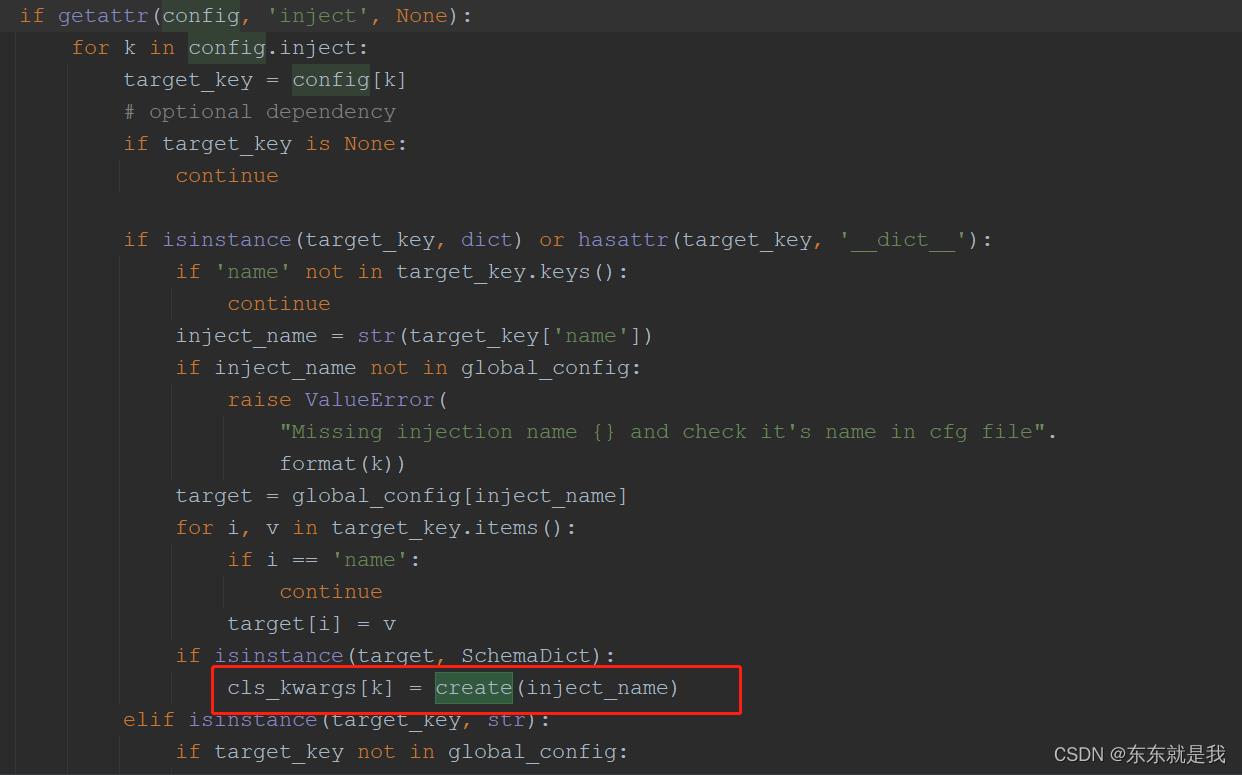
他会循环调用creat函数 ,把需要的成员变量也实例化注册进实例类中。
以上是关于paddle detection 配置文件怎么实例化的 代码梳理 -----(regiester)的主要内容,如果未能解决你的问题,请参考以下文章