大数据处理技术实验8
Posted 小手の冰凉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据处理技术实验8相关的知识,希望对你有一定的参考价值。
目录
一、Sparkの安装及配置。使用 Spark shell 实现 file8.txt 文件的词频统 计(WordCount)。
二、使用sbt编译打包Scale程序,统计 file8.txt 文件中包含字母 c 和字母 e 的行数。
2.1.3 设置源,vim ~/.sbt/repositories
2.2 统计 file8.txt 文件中包含字母 c 和字母 e 的行数
一、Sparkの安装及配置。使用 Spark shell 实现 file8.txt 文件的词频统 计(WordCount)。
打开清华大学下载站 https://mirrors.tuna.tsinghua.edu.cn/
先进入Apache文件在选择spark文件
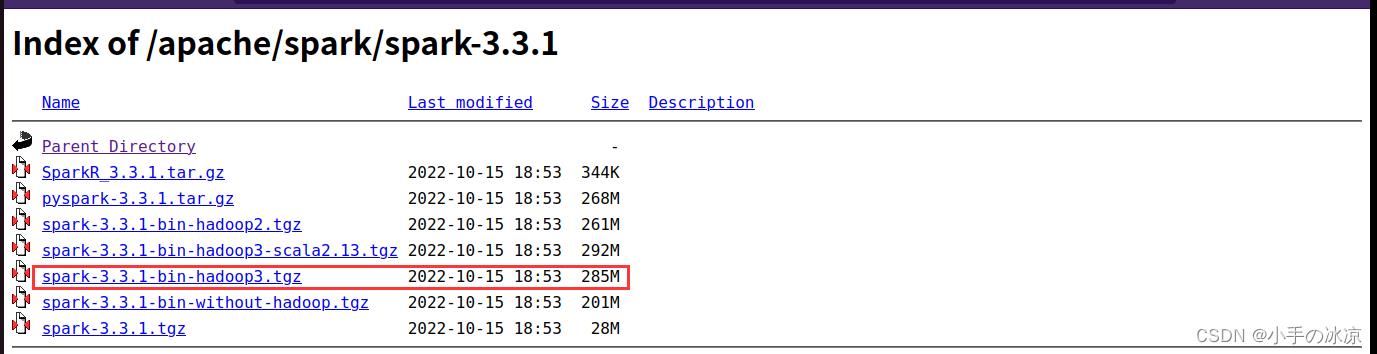
解压,如果提示没权限,加sudo chmod 777 -R
解压位置:/media/liuhao/sda4/spark
配置环境变量


简单测试,词频统计
新建文件test8.file

进入spark-shell

简单测试(词频统计)
 from pyspark import SparkConf,SparkContext as sc
from pyspark import SparkConf,SparkContext as sc
conf = SparkConf().setMaster("local").setAppName("wordcount")
sc=SparkContext.getOrCreate(conf)
lines = sc.textFile("/usr/local/hadoop/file8.txt")
words = lines.flatMap(lambda line:line.split(" "))
count = words.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
print(count.collect())

二、使用sbt编译打包Scale程序,统计 file8.txt 文件中包含字母 c 和字母 e 的行数。
2.1 安装sbt:
sbt - The interactive build toole

解压位置:/opt/scala/sbt
配置环境变量:vim ~./bshrc

2.1.1 建立启动sbt的脚本文件
建立启动sbt的脚本文本文件,如/opt/scala/sbt/ $ vim sbt ,在sbt文本文件中添加:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" java $SBT_OPTS -jar /opt/scala/sbt/bin/sbt-launch.jar "$@"

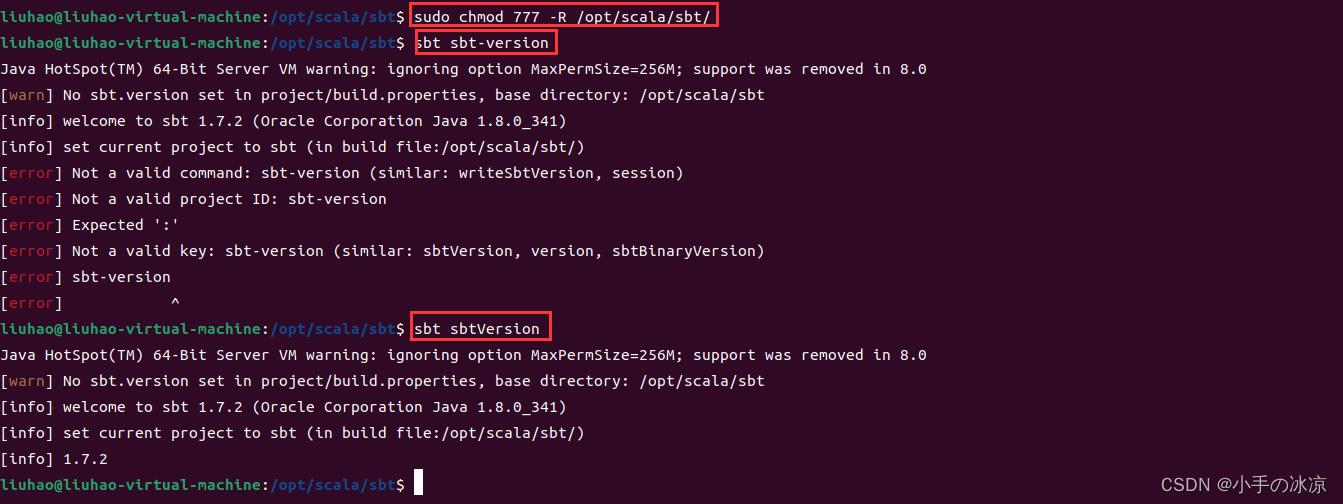
·修改sbt文件权限

2.1.2 测试sbt是否安装成功
/*第一次执行时,会下载一些文件包,然后才能正常使用,要确保联网了,安装成功后显示如下*/ $ sbt sbt-version [info] Set current project to sbt (in build file:/opt/scala/sbt/) [info] 0.13.5
2.1.3 设置源,vim ~/.sbt/repositories
[repositories] local huaweicloud-maven: https://repo.huaweicloud.com/repository/maven/ maven-central: https://repo1.maven.org/maven2/ huaweicloud-ivy: https://repo.huaweicloud.com/repository/ivy/, [organization]/[module]/(scala_[scalaVers
2.2 统计 file8.txt 文件中包含字母 c 和字母 e 的行数
1. 创建文件夹
mkdir ./sparkapp
mkdir -p ./sparkapp/src/main/scala
2. 在~/sparkapp/src/main/scala文件夹下编辑SimpleApp.scala
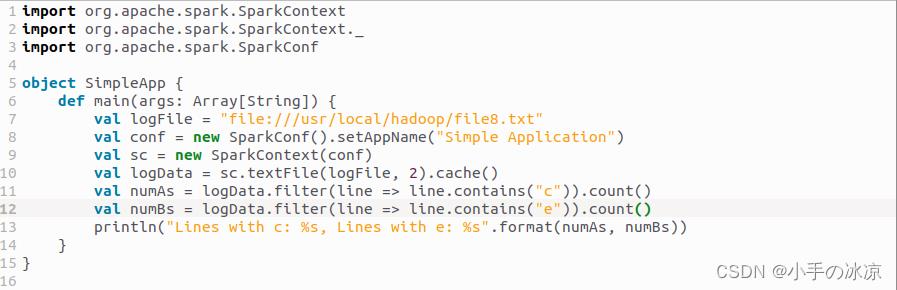
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp
def main(args: Array[String])
val logFile = "file:///usr/local/hadoop/file8.txt"
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("c")).count()
val numBs = logData.filter(line => line.contains("e")).count()
println("Lines with c: %s, Lines with e: %s".format(numAs, numBs))
3. 编译打包
vim ./sparkapp/simple.sbt
文件内容(在安装过程中注意查看版本):
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.15"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.3.1"
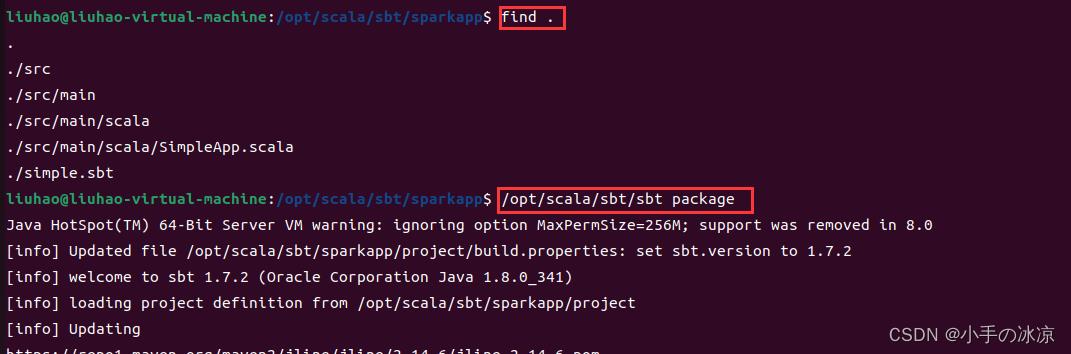
检查应用程序文件结构:
find .
应用程序打包
sbt package
4. 通过spark-submit运行程序
/media/liuhao/sda4/spark/bin/spark-submit --class "SimpleApp" /opt/scala/sbt/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "Lines with"
 如果无输出,请查看问题所在:
如果无输出,请查看问题所在:
/media/liuhao/sda4/spark/bin/spark-submit --class "SimpleApp" /opt/scala/sbt/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1
【参考资料】
ubuntu上安装spark详细步骤_大广-全栈开发的博客-CSDN博客_ubuntu安装spark
以上是关于大数据处理技术实验8的主要内容,如果未能解决你的问题,请参考以下文章