利用C++行程编码编写一款压缩软件,思路:读取,编码,解码。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用C++行程编码编写一款压缩软件,思路:读取,编码,解码。相关的知识,希望对你有一定的参考价值。
求大神,解决问题给悬赏
用哈夫曼压缩文件(C语言)利用哈夫曼编码制作压缩软件,内容如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <conio.h>
struct head
unsigned char b; //记录字符在数组中的位置
long count; //字符出现频率(权值)
long parent,lch,rch; //定义哈夫曼树指针变量
char bits[256]; //定义存储哈夫曼编码的数组
header[512],tmp;
/*压缩*/
void compress()
char filename[255],outputfile[255],buf[512];
unsigned char c;
long i,j,m,n,f;
long min1,pt1,flength,length1,length2;
double div;
FILE *ifp,*ofp;
printf("\\t请您输入需要压缩的文件:");
gets(filename);
ifp=fopen(filename,"rb");
if(ifp==NULL)
printf("\\n\\t文件打开失败!\\n\\n");
return;
printf("\\t请您输入压缩后的文件名:");
gets(outputfile);
ofp=fopen(strcat(outputfile,".hub"),"wb");
if(ofp==NULL)
printf("\\n\\t压缩文件失败!\\n\\n");
return;
flength=0;
while(!feof(ifp))
fread(&c,1,1,ifp);
header[c].count++; //字符重复出现频率+1
flength++; //字符出现原文件长度+1
flength--;
length1=flength; //原文件长度用作求压缩率的分母
header[c].count--;
for(i=0;i<512;i++)
if(header[i].count!=0) header[i].b=(unsigned char)i;
/*将每个哈夫曼码值及其对应的ASCII码存放在一维数组header[i]中,
且编码表中的下标和ASCII码满足顺序存放关系*/
else header[i].b=0;
header[i].parent=-1;header[i].lch=header[i].rch=-1; //对结点进行初始化
for(i=0;i<256;i++) //根据频率(权值)大小,对结点进行排序,选择较小的结点进树
for(j=i+1;j<256;j++)
if(header[i].count<header[j].count)
tmp=header[i];
header[i]=header[j];
header[j]=tmp;
for(i=0;i<256;i++) if(header[i].count==0) break;
n=i; //外部叶子结点数为n个时,内部结点数为n-1,整个哈夫曼树的需要的结点数为2*n-1.
m=2*n-1;
for(i=n;i<m;i++) //构建哈夫曼树
min1=999999999; //预设的最大权值,即结点出现的最大次数
for(j=0;j<i;j++)
if(header[j].parent!=-1) continue;
//parent!=-1说明该结点已存在哈夫曼树中,跳出循环重新选择新结点*/
if(min1>header[j].count)
pt1=j;
min1=header[j].count;
continue;
header[i].count=header[pt1].count;
header[pt1].parent=i; //依据parent域值(结点层数)确定树中结点之间的关系
header[i].lch=pt1; //计算左分支权值大小
min1=999999999;
for(j=0;j<i;j++)
if(header[j].parent!=-1) continue;
if(min1>header[j].count)
pt1=j;
min1=header[j].count;
continue;
header[i].count+=header[pt1].count;
header[i].rch=pt1; //计算右分支权值大小
header[pt1].parent=i;
for(i=0;i<n;i++) //哈夫曼无重复前缀编码
f=i;
header[i].bits[0]=0; //根结点编码0
while(header[f].parent!=-1)
j=f;
f=header[f].parent;
if(header[f].lch==j) //置左分支编码0
j=strlen(header[i].bits);
memmove(header[i].bits+1,header[i].bits,j+1);
//依次存储连接“0”“1”编码
header[i].bits[0]=\'0\';
else //置右分支编码1
j=strlen(header[i].bits);
memmove(header[i].bits+1,header[i].bits,j+1);
header[i].bits[0]=\'1\';
fseek(ifp,0,SEEK_SET); //从文件开始位置向前移动0字节,即定位到文件开始位置
fwrite(&flength,sizeof(int),1,ofp);
/*用来将数据写入文件流中,参数flength指向欲写入的数据地址,
总共写入的字符数以参数size*int来决定,返回实际写入的int数目1*/
fseek(ofp,8,SEEK_SET);
buf[0]=0; //定义缓冲区,它的二进制表示00000000
f=0;
pt1=8;
/*假设原文件第一个字符是"A",8位2进制为01000001,编码后为0110识别编码第一个\'0\',
那么我们就可以将其左移一位,看起来没什么变化。下一个是\'1\',应该|1,结果00000001
同理4位都做完,应该是00000110,由于字节中的8位并没有全部用完,我们应该继续读下一个字符,
根据编码表继续拼完剩下的4位,如果字符的编码不足4位,还要继续读一个字符,
如果字符编码超过4位,那么我们将把剩下的位信息拼接到一个新的字节里*/
while(!feof(ifp))
c=fgetc(ifp);
f++;
for(i=0;i<n;i++)
if(c==header[i].b) break;
strcat(buf,header[i].bits);
j=strlen(buf);
c=0;
while(j>=8) //对哈夫曼编码位操作进行压缩存储
for(i=0;i<8;i++)
if(buf[i]==\'1\') c=(c<<1)|1;
else c=c<<1;
fwrite(&c,1,1,ofp);
pt1++; //统计压缩后文件的长度
strcpy(buf,buf+8); //一个字节一个字节拼接
j=strlen(buf);
if(f==flength) break;
if(j>0) //对哈夫曼编码位操作进行压缩存储
strcat(buf,"00000000");
for(i=0;i<8;i++)
if(buf[i]==\'1\') c=(c<<1)|1;
else c=c<<1;
fwrite(&c,1,1,ofp);
pt1++;
fseek(ofp,4,SEEK_SET);
fwrite(&pt1,sizeof(long),1,ofp);
fseek(ofp,pt1,SEEK_SET);
fwrite(&n,sizeof(long),1,ofp);
for(i=0;i<n;i++)
fwrite(&(header[i].b),1,1,ofp);
c=strlen(header[i].bits);
fwrite(&c,1,1,ofp);
j=strlen(header[i].bits);
if(j%8!=0) //若存储的位数不是8的倍数,则补0
for(f=j%8;f<8;f++)
strcat(header[i].bits,"0");
while(header[i].bits[0]!=0)
c=0;
for(j=0;j<8;j++) //字符的有效存储不超过8位,则对有效位数左移实现两字符编码的连接
if(header[i].bits[j]==\'1\') c=(c<<1)|1; //|1不改变原位置上的“0”“1”值
else c=c<<1;
strcpy(header[i].bits,header[i].bits+8); //把字符的编码按原先存储顺序连接
fwrite(&c,1,1,ofp);
length2=pt1--;
div=((double)length1-(double)length2)/(double)length1; //计算文件的压缩率
fclose(ifp);
fclose(ofp);
printf("\\n\\t压缩文件成功!\\n");
printf("\\t压缩率为 %f%%\\n\\n",div*100);
return;
/*解压缩*/
void uncompress()
char filename[255],outputfile[255],buf[255],bx[255];
unsigned char c;
long i,j,m,n,f,p,l;
long flength;
FILE *ifp,*ofp;
printf("\\t请您输入需要解压缩的文件:");
gets(filename);
ifp=fopen(strcat(filename,".hub"),"rb");
if(ifp==NULL)
printf("\\n\\t文件打开失败!\\n");
return;
printf("\\t请您输入解压缩后的文件名:");
gets(outputfile);
ofp=fopen(outputfile,"wb");
if(ofp==NULL)
printf("\\n\\t解压缩文件失败!\\n");
return;
fread(&flength,sizeof(long),1,ifp); //读取原文件长度,对文件进行定位
fread(&f,sizeof(long),1,ifp);
fseek(ifp,f,SEEK_SET);
fread(&n,sizeof(long),1,ifp);
for(i=0;i<n;i++)
fread(&header[i].b,1,1,ifp);
fread(&c,1,1,ifp);
p=(long)c; //读取原文件字符的权值
header[i].count=p;
header[i].bits[0]=0;
if(p%8>0) m=p/8+1;
else m=p/8;
for(j=0;j<m;j++)
fread(&c,1,1,ifp);
f=c;
itoa(f,buf,2); //将f转换为二进制表示的字符串
f=strlen(buf);
for(l=8;l>f;l--)
strcat(header[i].bits,"0");
strcat(header[i].bits,buf);
header[i].bits[p]=0;
for(i=0;i<n;i++) //根据哈夫曼编码的长短,对结点进行排序
for(j=i+1;j<n;j++)
if(strlen(header[i].bits)>strlen(header[j].bits))
tmp=header[i];
header[i]=header[j];
header[j]=tmp;
p=strlen(header[n-1].bits);
fseek(ifp,8,SEEK_SET);
m=0;
bx[0]=0;
while(1) //通过哈夫曼编码的长短,依次解码,从原来的位存储还原到字节存储
while(strlen(bx)<(unsigned int)p)
fread(&c,1,1,ifp);
f=c;
itoa(f,buf,2);
f=strlen(buf);
for(l=8;l>f;l--) //在单字节内对相应位置补0
strcat(bx,"0");
strcat(bx,buf);
for(i=0;i<n;i++)
if(memcmp(header[i].bits,bx,header[i].count)==0) break;
strcpy(bx,bx+header[i].count); /*从压缩文件中的按位存储还原到按字节存储字符,
字符位置不改变*/
c=header[i].b;
fwrite(&c,1,1,ofp);
m++; //统计解压缩后文件的长度
if(m==flength) break; //flength是原文件长度
fclose(ifp);
fclose(ofp);
printf("\\n\\t解压缩文件成功!\\n");
if(m==flength) //对解压缩后文件和原文件相同性比较进行判断(根据文件大小)
printf("\\t解压缩文件与原文件相同!\\n\\n");
else printf("\\t解压缩文件与原文件不同!\\n\\n");
return;
/*主函数*/
int main()
int c;
while(1) //菜单工具栏
printf("\\t _______________________________________________\\n");
printf("\\n");
printf("\\t * 压缩、解压缩 小工具 * \\n");
printf("\\t _______________________________________________\\n");
printf("\\t _______________________________________________\\n");
printf("\\t| |\\n");
printf("\\t| 1.压缩 |\\n");
printf("\\t| 2.解压缩 |\\n");
printf("\\t| 0.退出 |\\n");
printf("\\t|_______________________________________________|\\n");
printf("\\n");
printf("\\t 说明:(1)采用哈夫曼编码\\n");
printf("\\t (2)适用于文本文件\\n");
printf("\\n");
do //对用户输入进行容错处理
printf("\\n\\t*请选择相应功能(0-2):");
c=getch();
printf("%c\\n",c);
if(c!=\'0\' && c!=\'1\' && c!=\'2\')
printf("\\t@_@请检查您的输入在0~2之间!\\n");
printf("\\t请再输入一遍!\\n");
while(c!=\'0\' && c!=\'1\' && c!=\'2\');
if(c==\'1\') compress(); //调用压缩子函数
else if(c==\'2\') uncompress(); //调用解压缩子函数
else
printf("\\t欢迎您再次使用该工具^_^\\n");
exit(0); //退出该工具
system("pause"); //任意键继续
system("cls"); //清屏
return 0;
追问
不要哈弗曼编码,要游程编码
参考技术A 很简单:记录第一各字节,然后读取其后面的一个字节,如果和前一个字节相同,合计该字节的个数。继续向后读取,合计...直到读到不同的字节,如果这个字节和前面的不同,则开始计数这个字节的个数。依次读取到文件的末尾。
比如
AAAAABBBBCCCCCCCDDDDD。用行程编码结果为:A5B4C7D5
相信聪明的你对如何解码也胸有成竹了吧!!!!追问
求源代码啊,…我是一点也不懂
图像压缩基于行程编码实现的图像压缩matlab源码
一、简介
1、行程编码概述(RLE)
在图像压缩上,行程编码(RLE)一般用于压缩二值化图像,因为它是基于重复的压缩算法,比如:
二维图像降维后(压缩前):0 0 0 0 0 255 255 255 0 0 255
行程编码压缩后:5 0 3 255 2 0 1 255
(压缩格式为:数量+像素+数量+像素…)
如果有大量的像素连续重复,那么压缩率会更高。
编码是方法建立在图像统计特性的基础上的。例如,在传真通信中的文件大多是二值图像,即每个像素的灰度值只有0和1两种取值。将一行中颜色值相同的相邻象素用一个计数值和该颜色值来代替。例如aaabccccccddeee可以表示为3a1b6c2d3e,,即有3个a,1个b,6个c,2个d,3个e。如果一幅图象是由很多块颜色相同的大面积区域组成,那么采用行程编码的压缩效率是惊人的。然而,该算法也导致了一个致命弱点,如果图象中每两个相邻点的颜色都不同,用这种算法不但不能压缩,反而数据量增加一倍。因此对有大面积色块的图像用行程编码效果比较好。
行程编码的可行性讨论:行程编码的压缩方法对于自然图片来说是不太可行的,因为自然图片像素点错综复杂,同色像素连续性差,如果硬要用行程编码方法来编码就适得其反,图像体积不但没减少,反而加倍。鉴于计算机桌面图,图像的色块大,同色像素点连续较多,所以行程编码对于计算机桌面图像来说是一种较好的编码方法。
2 图像压缩
2.1 图像压缩:图像压缩就是对图像数据按照一定的规则进行变换和组合,用尽可能少的数据量来表示影像,形象的说,就是对影像数据的瘦身。
2.2 图像压缩的必要性:多媒体数据的显著特点就是数据量非常大。例如,一张彩色相片的数据量可达10MB;视频影像和声音由于连续播放,数据量更加庞大。这对计算机的存储以及网络传输都造成了极大的负担。
2.3 图像压缩的可行性:
1)原始图像数据是高度相关的,存在很大的冗余。数据冗余造成比特数浪费,消除这些冗余可以节约码字,也就是达到了数据压缩的目的。大多数图像内相邻像素之间有较大的相关性,这称为空间冗余。序列图像前后帧内相邻之间有较大的相关性,这称为时间冗余。
2)若用相同码长来表示不同出现概率的符号也会造成比特数的浪费,这种浪费称为符号编码冗余。如果采用可变长编码技术,对出现概率高的符号用短码字表示,对出现概率低的符号用长码字表示,这样就可大大消除符号编码冗余。再次,有些图像信息(如色度信息、高频信息)在通常的视感觉过程中与另外一些信息相比来说不那么重要,这些信息可以认为是心里视觉冗余,去除这些信息并不会明显地降低人眼所感受到的图像质量,因此在压缩的过程中可以去除这些人眼不敏感的信息,从而实现数据压缩。
二、源代码
function yc
%%行程编码算法
%例如aaabccccccddeee才可以表示为3a1b6c2d3e
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%读图
I=imread('Lena.jpg');
[m n l]=size(I);
fid=fopen('yc.txt','w');
%yc.txt是行程编码算法的灰度级及其相应的编码表
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%行程编码算法
sum=0;
for k=1:l
for i=1:m
num=0;
J=[];
value=I(i,1,k);
for j=2:n
if I(i,j,k)==value
num=num+1;
%统计相邻像素灰度级相等的个数
if j==n
J=[J,num,value];
end
else J=[J,num,value];
%J的形式是先是灰度的个数及该灰度的值
value=I(i,j,k);
num=1;
end
end
col(i,k)=size(J,2);
%记录Y中每行行程行程编码数
sum=sum+col(i,k);
Y(i,1:col(i,k),k)=J;
%将I中每一行的行程编码J存入Y的相应行中
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%输出相关数据
[m1,n1,l1]=size(Y);
disp('原图像大小:')
whos('I');
disp('压缩图像大小:')
whos('Y');
disp('图像的压缩比:');
disp(m*n*l/sum);三、运行结果
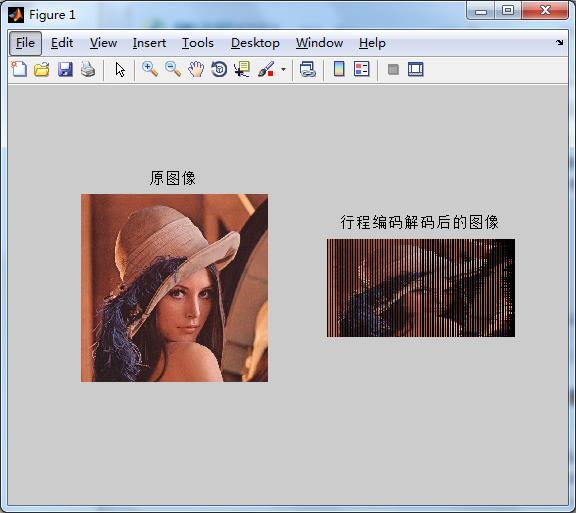
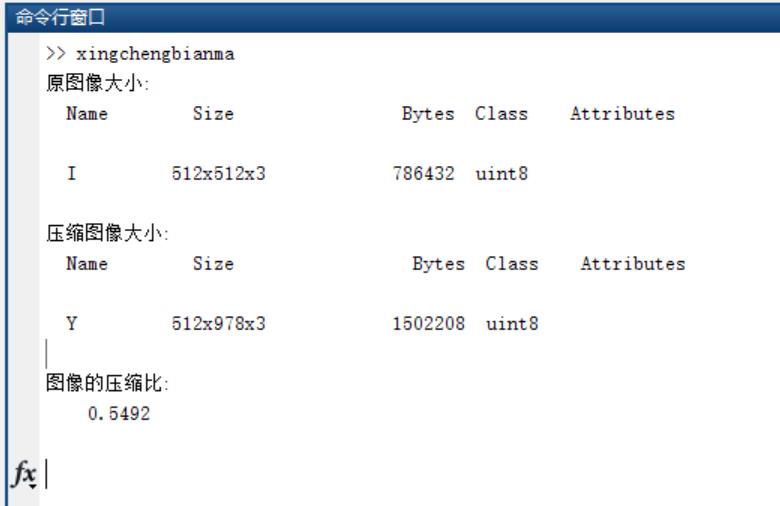
四、备注
完整代码或者仿真咨询添加QQ1575304183
以上是关于利用C++行程编码编写一款压缩软件,思路:读取,编码,解码。的主要内容,如果未能解决你的问题,请参考以下文章