(02)Cartographer源码无死角解析-(54) 2D后端优化→PoseGraphInterfacePoseGraphPoseGraph2D::AddNode()
Posted 江南才尽,年少无知!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(02)Cartographer源码无死角解析-(54) 2D后端优化→PoseGraphInterfacePoseGraphPoseGraph2D::AddNode()相关的知识,希望对你有一定的参考价值。
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解(02)Cartographer源码无死角解析-链接如下:
(02)Cartographer源码无死角解析- (00)目录_最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/127350885
文末正下方中心提供了本人
联系方式,
点击本人照片即可显示
W
X
→
官方认证
\\colorblue文末正下方中心提供了本人 \\colorred 联系方式,\\colorblue点击本人照片即可显示WX→官方认证
文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证
一、前言
通过上一篇博客,再次对 global_trajectory_builder.cc 文件中的 AddSensorData() 进行了分析,同时简要提及位姿图。在Cartographer 中,位姿图优化核心类为 src/cartographer/cartographer/mapping/internal/2d/pose_graph_2d.cc 文件中的 PoseGraph2D。其函数 PoseGraph2D::AddNode() 起到了前端与后端交互作用。
对于接下来的讲解,本人比较纠结,①先讲整体流程,再梳理细节;②按照源码执行过程,见招拆招,按顺序讲解;这两种方式,最终选择了后者。因为如果直接讲整体流程,没有基础的情况下是很难看懂的。所示,接下来按照源码执行过程,一一进行讲解,类似于本人分析代码的过程。等把细节都梳理清楚之后,再反过来做一个总结,这样应该理解就比较深刻了。这里复制一下 PoseGraph2D::AddNode() 被调用过程,即 GlobalTrajectoryBuilder::AddSensorData() 函数中代码段如下:
// 将匹配后的结果 当做节点 加入到位姿图中
auto node_id = pose_graph_->AddNode(
matching_result->insertion_result->constant_data, //子图相关的
trajectory_id_, //轨迹id
matching_result->insertion_result->insertion_submaps); //子图
该些变量都再前面进行分析过,其上 constant_data 为 const TrajectoryNode::Data 类型的智能指针:
struct Data
common::Time time; //点云数据时间戳
// Transform to approximately gravity align the tracking frame as
// determined by local SLAM.
Eigen::Quaterniond gravity_alignment; //重力校正旋转四元数
// Used for loop closure in 2D: voxel filtered returns in the
// 'gravity_alignment' frame.
sensor::PointCloud filtered_gravity_aligned_point_cloud; //经过滤波之后的点云数据
// Used for loop closure in 3D.用于3D回环检测,
sensor::PointCloud high_resolution_point_cloud; //高分辨率点云数据
sensor::PointCloud low_resolution_point_cloud; //低分辨率点云数据
Eigen::VectorXf rotational_scan_matcher_histogram; //旋转扫描匹配直方图
// The node pose in the local SLAM frame.
transform::Rigid3d local_pose; //节点相对于local SLAM frame(可以理解为lcoal地图)的位姿,MatchingResult::local_pose是一致的
;
在了解这些之后,下面就开始对PoseGrap2D继续进行一个详细分析了。首先其继承关系如下:
PoseGraph2D:PoseGraph:PoseGraphInterface
根据继承关系, 首先要理解PoseGraphInterface,其在 src/cartographer/cartographer/mapping/pose_graph_interface.h 定义。
二、PoseGraphInterface
首先其是定义了一个结构提体类型struct Constraint,代码注释之前,可以看下图,有助于后续的理解(
用于参考,并不一定完全正确
\\colorred用于参考,并不一定完全正确
用于参考,并不一定完全正确)

1、黑色坐标系: 表示Global全局坐标系,O表示原点
2、红色坐标系: 子图坐标系,O表示原点
3、紫色矩形: 子图
4、Submapx: 分别代表子图1、子图2、子图3
5、蓝色虚线:分别表示子图间约束、子图内约束
该图示中有些地方可能是带有疑问的,如Global全局坐标系是否在左上角?子图local坐标系是否在左上角?子图Submap1坐标系与Global全局坐标系是否相同?这些疑问暂时就不解答了,后续如果有时间,再来分析,到时候发现不对的地方再做纠正。
1、结构体Constrain
首先PoseGraphInterface中定义了结构体Constraint,其是用于描述一个约束,也就是图优化中的边,这里先贴一下代码注释:
// 包含了子图的id, 节点的id, 节点j相对于子图i的坐标变换, 以及节点是在子图内还是子图外的标志
struct Constraint
struct Pose
transform::Rigid3d zbar_ij;
double translation_weight;
double rotation_weight;
;
SubmapId submap_id; // 'i' in the paper.
NodeId node_id; // 'j' in the paper.
// Pose of the node 'j' relative to submap 'i'.
Pose pose;
// Differentiates between intra-submap (where node 'j' was inserted into
// submap 'i') and inter-submap constraints (where node 'j' was not inserted
// into submap 'i').
enum Tag INTRA_SUBMAP, INTER_SUBMAP tag;
;
对应于论文中如下内容:

在上一篇文中提到,简单的来说,可以直接把一个位姿变换看作一个约束。其上代码中定义的Constraint就是描述一个位姿变换: Constraint::submap_id对应的子图到Constraint::node_id对应的节点位姿变换, submap_id 等价于论文中
c
i
c_i
ci,node_id等价于论文中
c
j
c_j
cj,如果觉得这里所谓的节点不好理解,直接看成机器人位姿即可。总的来说 Constraint:pose表示节点 j 相对于子图 i 的位姿。
另外,其定义的一个枚举类型Tag,如图1所示,因为机器人位于Submap7中,其蓝色虚线INTRA_SUBMA表示 Submap7(原点)到机器人的位姿变换,等价于机器人在Submap7中的位姿,即机器人与在所属子图的位姿(等价于该子图到机器人位姿变换),称为INTER_SUBMAP 子图内约束。
除此之外,如图1还可以看到Submap2原点与机器人连接的蓝色虚线,其表示Submap2系到机器人系的位姿变换,可机器人并不处于子图Submap2中,所以该属于INTRA_SUBMAP子图间约束。
2、结构体LandmarkNode
除结构体结构体类型 struct Constrain,pose_graph_interface.h中还定义了结构体类型 struct LandmarkNode,其主要用来描述一个Landmark节点,首先机器人在某个时刻位姿下,可能同时观测到多个Landmark,这些被观测到的Landmark数据存储于成员变量 LandmarkNode::landmark_observations 之中,LandmarkNode::global_landmark_pose 表示这帧 Landmark 数据对应的 tracking_frame 在 globa l坐标系下的位姿,如下所示:
struct LandmarkNode
// landmark数据是相对于tracking_frame的相对坐标变换
struct LandmarkObservation
int trajectory_id;
common::Time time;
transform::Rigid3d landmark_to_tracking_transform;
double translation_weight;
double rotation_weight;
;
// 同一时刻可能会观测到多个landmark数据
std::vector<LandmarkObservation> landmark_observations;
// 这帧数据对应的tracking_frame在global坐标系下的位姿
absl::optional<transform::Rigid3d> global_landmark_pose;
bool frozen = false;
;
可以看到单个 landmark 数据是使用 LandmarkNode::LandmarkObservation 类型结构体描述的,首先包含了trajectory_id、time。以及 landmark_to_tracking_transform,其表示单个landmark相对于tracking_frame(机器人)的位姿,另外包含了该位姿旋转与平移的权重 translation_weight、rotation_weight。最后关于参数LandmarkNode::frozen,其含义是冻结,这里猜测其是对 LandmarkNode 进行冻结,即表示其内的成员数据不会被改变了。
3、SubmapPose、SubmapData
struct SubmapPose
int version;
transform::Rigid3d pose;
;
struct SubmapData
std::shared_ptr<const Submap> submap;
transform::Rigid3d pose;
;
这两个结构体类型比较简单,分别用来表述子图的位姿与子图的数据,SubmapData 中实际上存储一个指向于 Submap 类型指针,可以注意到成员变量 SubmapData::pose,目前估计其也是子图的位姿→相对于全局坐标系。
4、TrajectoryData、TrajectoryState
// tag: TrajectoryData
struct TrajectoryData
double gravity_constant = 9.8; //重力常数
std::array<double, 4> imu_calibration1., 0., 0., 0.; //初始默认值,单位四元数
absl::optional<transform::Rigid3d> fixed_frame_origin_in_map; //GPS帧原点相对于map的位姿。
;
enum class TrajectoryState ACTIVE, FINISHED, FROZEN, DELETED ;
TrajectoryData 是用来秒速轨迹数据的、这里看起来不知道给来干嘛的,后续使用到了再做具体分析。枚举类型 TrajectoryState 定义了轨迹4种状态,分别为激活(ACTIVE)、完成(FINISHED)、冻结(FINISHED)、删除(DELETED)。
5、GlobalSlamOptimizationCallback
最后还定义了一个回调函数类型,该类型函数无返回值、输入类型分别为 std::map<int,SubmapId>、 std::map<int, NodeId> 。该类函数的功能是做全局优化。
using GlobalSlamOptimizationCallback =
std::function<void(const std::map<int /* trajectory_id */, SubmapId>&,
const std::map<int /* trajectory_id */, NodeId>&)>;
下面都是一些虚函数了,后续对PoseGraph2D讲解时,再对其进行具体分析。
三、PoseGraph
前面以及提到PoseGraph由PoseGraphInterface派生而来,其声明于src/cartographer/cartographer/mapping/pose_graph.h 文件中,其中定义了结构体类型 struct InitialTrajectoryPose,用来秒速一个轨迹的初始位姿,不过值得注意的是,该初始位姿是一个先对值,相对于 to_trajectory_id 的位置,后续使用到了,再分析一遍,代码如下:
// 相对于to_trajectory_id的初始位姿
struct InitialTrajectoryPose
int to_trajectory_id;
transform::Rigid3d relative_pose;
common::Time time;
;
四、PoseGraph2D::AddNode
那先现在就是关于PoseGraph2D部分了,其继承至PoseGraph。类声明于 src/cartographer/cartographer/mapping/internal/2d/pose_graph_2d.h 文件中,其主要声明一些重写的虚函数,后续一个一个的为大家讲解。该篇不可只对其中的PoseGraph2D::AddNode() 函数进行分析。上一篇博客中提到,该函数中在 src/cartographer/cartographer/mapping/internal/global_trajectory_builder.cc 文件中有被调用。PoseGraph2D::AddNode() 函数总体流程可以说是十分的简单、但是如果深入了解其调用函数,可以说是复杂至极。但是关于 PoseGraph2D::AddNode() 函数的逻辑还是十分简单的。其主要流程如下:
( 01 ) \\colorblue(01) (01) 首先其需要传递三个参数:①参数constant_data就是上面的struct Data类型,主要是关于插入子图中相关的固化信息;②trajectory_id表示轨迹id;③insertion_submaps去通常包含两个活跃子图。
( 02 ) \\colorblue(02) (02)首先调用GetLocalToGlobalTransform() 函数传入 trajectory_id 获得由local系到global系的坐标变换矩阵,然后左乘constant_data->local_pose,其目的是把local坐标系下的节点坐标(把扫描匹配出来的位姿看成一个节点)变换到global系下。
( 03 ) \\colorblue(03) (03) 把变换到global系下的节点(位姿)通过PoseGraph2D::AppendNode()函数加入到节点列表 PoseGraph2D::data_trajectory_nodes 之中,该成员变量的定义为:MapById<NodeId, TrajectoryNode> trajectory_nodes;加入之后会获得一个NodeId node_id,其为整个函数的返回值。
( 04 ) \\colorblue(04) (04) 把计算约束的工作放入workitem中等待执行,需要注意的是,这里并还没有执行计算节点约束函数 ComputeConstraintsForNode(),仅仅是把该函数作为一个任务项添加至线程池→关于线程部分后续再进行详细分析。
/**
* @brief 增加节点, 并计算跟这个节点相关的约束
*
* @param[in] constant_data 节点信息
* @param[in] trajectory_id 轨迹id
* @param[in] insertion_submaps 子地图 active_submaps
* @return NodeId 返回节点的ID
*/
NodeId PoseGraph2D::AddNode(
std::shared_ptr<const TrajectoryNode::Data> constant_data,
const int trajectory_id,
const std::vector<std::shared_ptr<const Submap2D>>& insertion_submaps)
// 将节点在local坐标系下的坐标转成global坐标系下的坐标
const transform::Rigid3d optimized_pose(
GetLocalToGlobalTransform(trajectory_id) * constant_data->local_pose);
// 向节点列表加入节点,并得到节点的id
const NodeId node_id = AppendNode(constant_data, trajectory_id,
insertion_submaps, optimized_pose);
// We have to check this here, because it might have changed by the time we
// execute the lambda.
// 获取第一个submap是否是完成状态
const bool newly_finished_submap =
insertion_submaps.front()->insertion_finished();
// 把计算约束的工作放入workitem中等待执行
AddWorkItem([=]() LOCKS_EXCLUDED(mutex_)
return ComputeConstraintsForNode(node_id, insertion_submaps,
newly_finished_submap);
);
return node_id;
五、结语
到目前为止,对PoseGraph2D继承关系,以及其中包含的结构体定义与成员变量进行了简单讲解。那么下面就是对细节的分析。后续主要围绕 PoseGraph2D::AddNode() 函数进行展开。接下里要讲解的,首先就是其调用代码:
// local系下的位姿变换到global系下
const transform::Rigid3d optimized_pose(
GetLocalToGlobalTransform(trajectory_id) * constant_data->local_pose);
如何把local系下的位姿变换到global系下,其上的 constant_data->local_pose 就表示local系下的位姿,可以理解为机器人Robot位姿。
精通Mybatis之结果集处理流程与映射体系(无死角懒加载讲解)
前言
开始上班了,小编继上篇博客精通Mybatis之结果集处理流程与映射体系(重点mybatis嵌套子查询,循环依赖解决方案)(二),今天讲结果集处理与映射的倒数第二篇,本来以为三篇能结束的结果发现不够用了,先讲懒加载吧。话不多说进入主题。
懒加载
懒加载是为改善解析对象属性时,大量的嵌套子查询的并发问题。设置懒加载后,只有在使用指定属性时才会加载,从而分散SQL请求。mybatis懒加载原理是基于动态代理实现的。
基本配置以及代码示例(小编依旧使用公司下多个部门的嵌套查询,设置部门查询的时候使用懒加载):
<resultMap id="DepartmentMap" type="entity.Department">
<id property="id" column="id"/>
<result property="companyId" column="company_id" />
<result property="departmentName" column="department_name"/>
</resultMap>
<resultMap id="CompanyMap2" type="entity.Company">
<id property="id" column="id"/>
<result property="companyName" column="company_name" jdbcType="VARCHAR"/>
<collection property="departmentList" column="id" select="selectDepartmentByCompanyId" fetchType="lazy"/>
</resultMap>
<select id="selectDepartmentByCompanyId" resultMap="DepartmentMap">
select * from department where company_id = #{companyId}
</select>
<select id="selectCompanyById" resultMap="CompanyMap2" parameterType="java.lang.Long">
select * from company where id = #{id}
</select>
测试代码:
public class LazyLoadTest {
SqlSessionFactory sqlSessionFactory;
Configuration configuration;
@Before
public void init() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
configuration = sqlSessionFactory.getConfiguration();
configuration.setLazyLoadTriggerMethods(new HashSet<>());
}
@Test
public void collectionLazyTest() {
try(SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE)){
CompanyMapper companyMapper = sqlSession.getMapper(CompanyMapper.class);
Company company = companyMapper.selectCompanyById(1L);
System.out.println(company.getDepartmentList().size());
}
}
}
好了小编根据示例先讲一下懒加载的配置和细节:
- 在嵌套子查询中指定 fetchType=“lazy” 即可设置懒加载。在调用company.getDepartmentList时才会真正加载。此外调用company的:“equals”, “clone”, “hashCode”, “toString” 均会触发当前对象所有未执行的懒加载。(“equals”, “clone”, “hashCode”, “toString” 这些方法是在configuration中lazyLoadTriggerMethods的属性,类型为Set,上面小编为了不让company直接懒加载[因为debug下会执行toString方法]从而设置了空hashSet)
- 通过设置全局参数aggressiveLazyLoading=true ,也可指定调用对象任意方法触发所有懒加载。
| 参数 | 描述 |
|---|---|
| lazyLoadingEnabled | 全局懒加载开关 默认false |
| aggressiveLazyLoading | 任意方法触发加载 默认false。 |
| fetchType | 加载方式 eager实时 lazy懒加载。默认eager |
- set方法覆盖,当调用setXXX方法手动设置属性之后,对应的属性懒加载将会被移除,不会覆盖手动设置的值。
- 当对象经过序列化和反序列化之后,默认不在支持懒加载。但如果在全局参数中设置了configurationFactory类,而且采用JAVA原生序列化是可以正常执行懒加载的。其原理是将懒加载所需参数以及配置一起进行序列化,反序列化后在通过configurationFactory获取configuration构建执行环境。需要配置:
public static class ConfigurationFactory {
public static Configuration getConfiguration() {
return configuration; }
}
第三与第四点小编通过代码再次说明一下:
set方法覆盖
//set方法覆盖
@Test
public void collectionLazySetTest() {
try(SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE)){
CompanyMapper companyMapper = sqlSession.getMapper(CompanyMapper.class);
Company company = companyMapper.selectCompanyById(1L);
company.setDepartmentList(new ArrayList<>());
System.out.println(company.getDepartmentList().size());
}
}
测试结果:
set方法覆盖
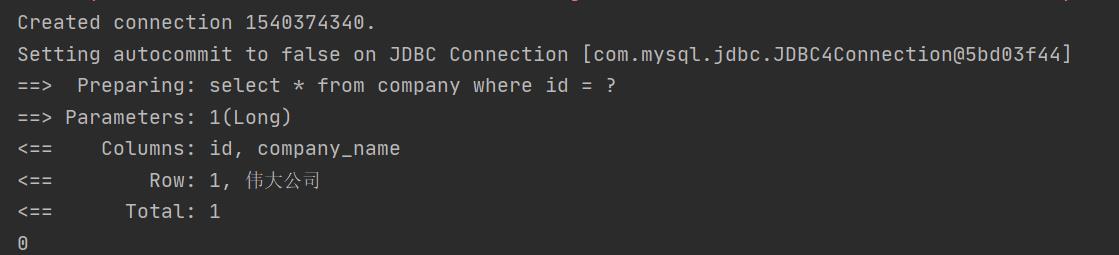
没set方法覆盖:
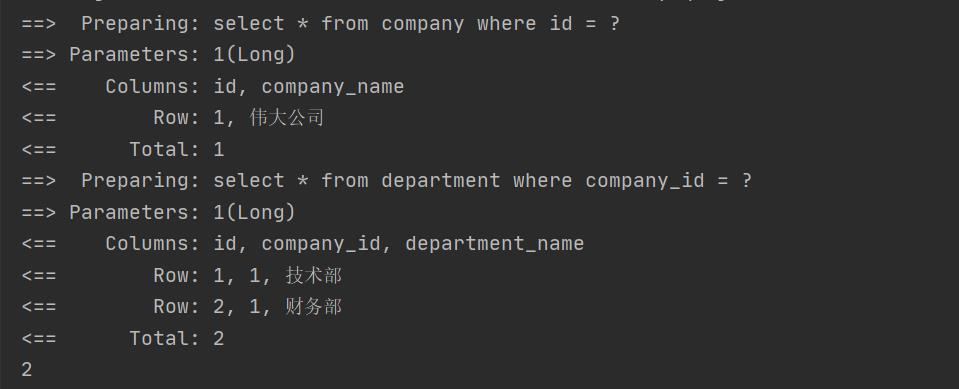
对象序列化反序列化
@Test
public void collectionLazySerializableTest() throws Exception{
try(SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE)){
CompanyMapper companyMapper = sqlSession.getMapper(CompanyMapper.class);
Company company = companyMapper.selectCompanyById(1L);
byte[] bytes = writeObject(company);
Company companySer = (Company)readObject(bytes);
System.out.println(companySer.getDepartmentList());
}
}
private byte[] writeObject(Object obj) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream outputStream = new ObjectOutputStream(out);
outputStream.writeObject(obj);
return out.toByteArray();
}
private Object readObject(byte[] bytes) throws IOException, ClassNotFoundException {
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
ObjectInputStream inputStream = new ObjectInputStream(in);
return inputStream.readObject();
}
测试结果:
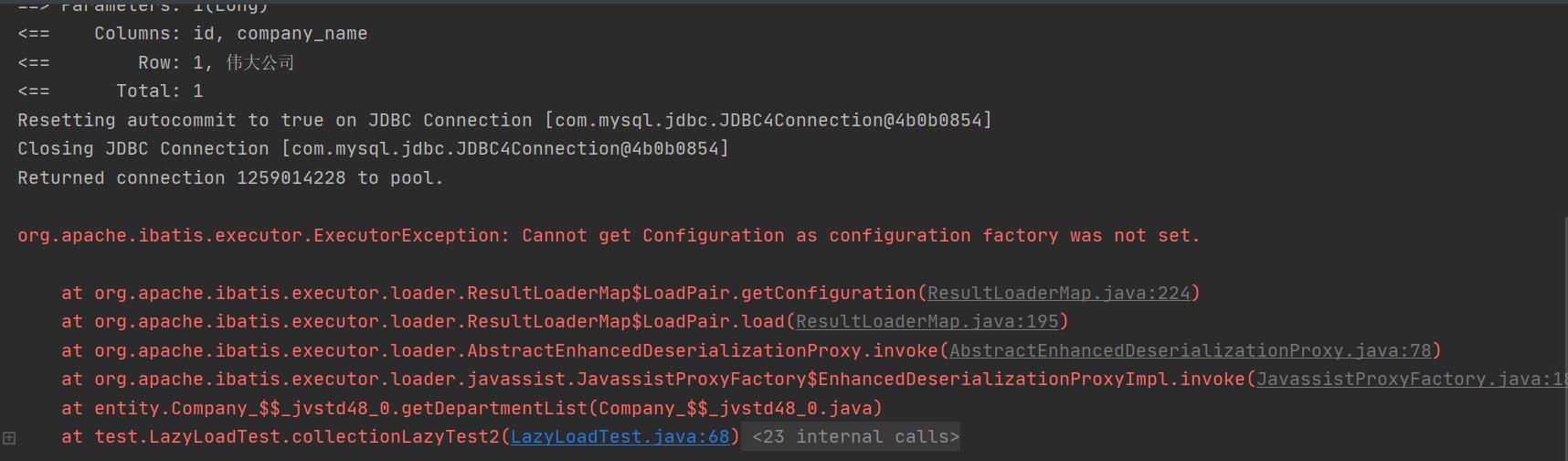
修改完毕后:
<settings>
//这里是内部静太类用$标识
<setting name="configurationFactory" value="test.LazyLoadTest$ConfigurationFactory"/>
</settings>
@Test
public void collectionLazySerializableTest() throws Exception{
try(SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.REUSE)){
CompanyMapper companyMapper = sqlSession.getMapper(CompanyMapper.class);
Company company = companyMapper.selectCompanyById(1L);
byte[] bytes = writeObject(company);
Company companySer = (Company)readObject(bytes);
System.out.println(companySer.getDepartmentList());
}
}
public static class ConfigurationFactory {
public static Configuration getConfiguration() {
return configuration; }
}
测试结果:
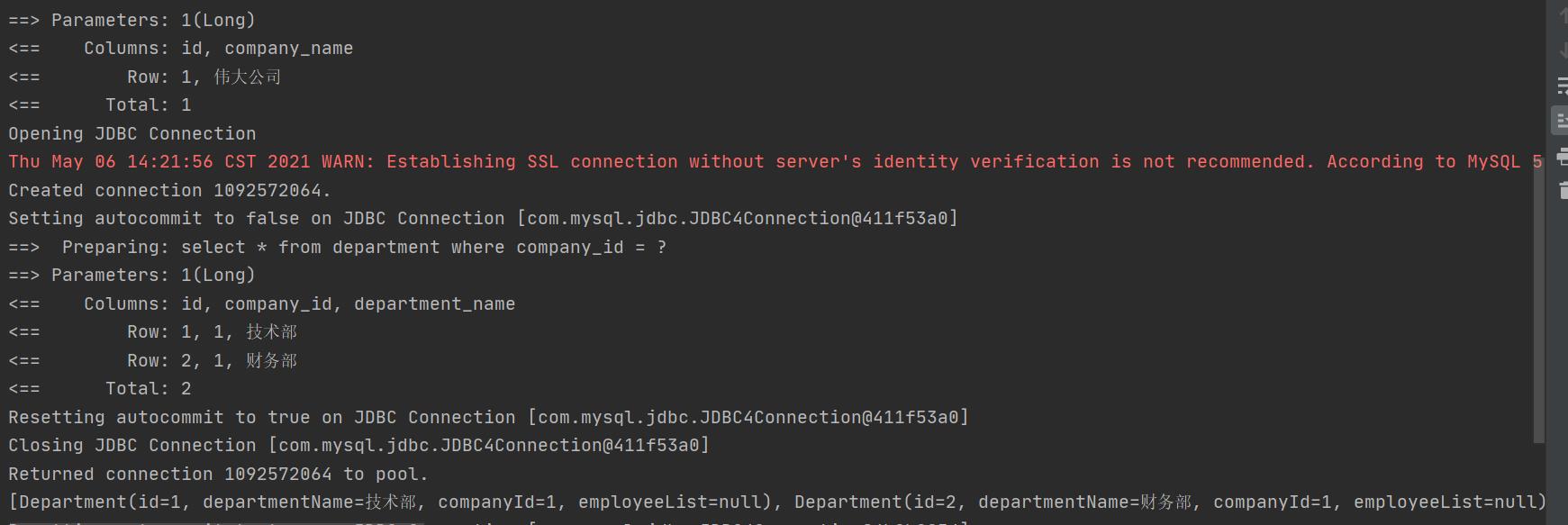
懒加载原理及内部结构
讲完了懒加载的结论,那小编肯定得证明原理,首先根据上面的示例代码,查看一下company的结构:
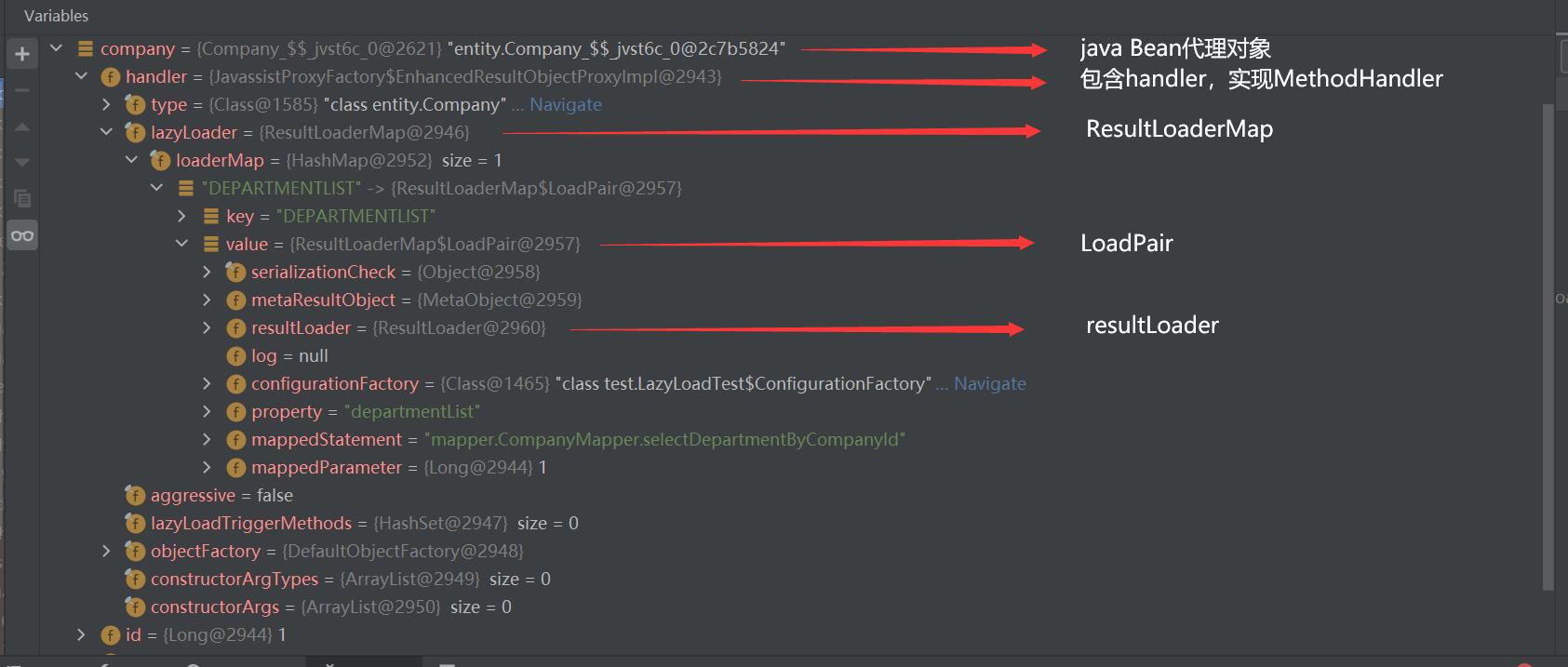
代理之后Bean会包含一个MethodHandler,内部在包含一个Map用于存放待执行懒加载,执行前懒加载前会移除。LoadPair用于针对反序列化的Bean准备执行环境。ResultLoader用于执行加载操作,执行前原执行器如果关闭会创建一个新的执行器(这里会引出一个小编之前没有讲解的Executor => ClosedExecutor)。特定属性如果加载失败,不会在进行二次加载。
内部结构图以及执行流程:
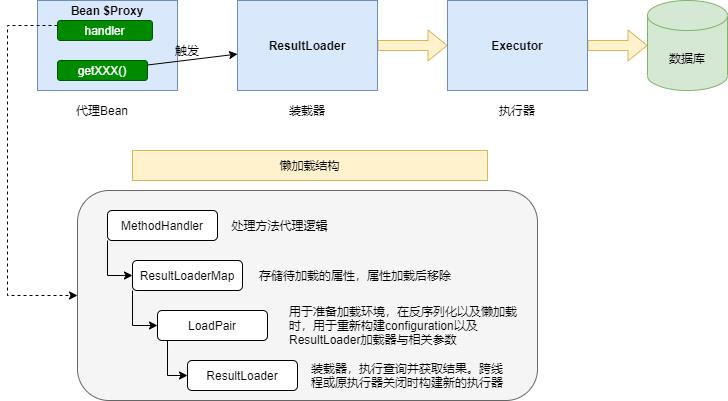
代理bean的创建过程
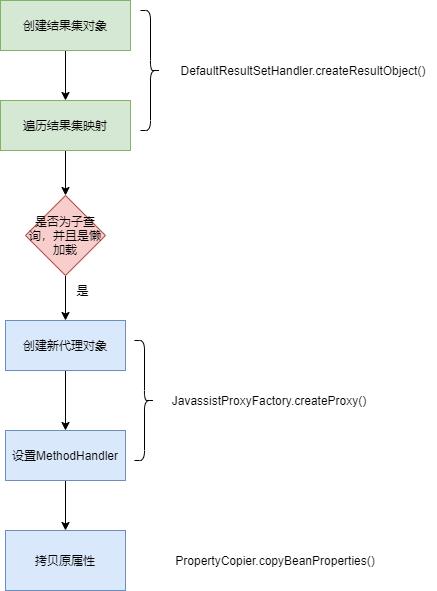
代理过程发生在结果集解析,创建对象之后(DefaultResultSetHandler.createResultObject),如果对应的属性设置了懒加载,则会通过ProxyFactory 创建代理对象,该对象继承自原对象,然后将对象的值全部拷贝到代理对像。并设置相应MethodHandler(原对象直接抛弃)
懒加载源码阅读
接下来小编带大家来一起阅读一下源码:
先是代理对象的创建:
DefaultResultSetHandler#createResultObject方法
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
...
//创建company对象
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
//三个映射 ,再department的时候为子查询且是懒加载
for (ResultMapping propertyMapping : propertyMappings) {
// issue gcode #109 && issue #149
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
//对company对象进行代理
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping result
return resultObject;
}
JavassistProxyFactory#createProxy方法
public static Object createProxy(Object target, ResultLoaderMap lazyLoader, Configuration configuration, ObjectFactory objectFactory, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
final Class<?> type = target.getClass();
//创建EnhancedResultObjectProxyImpl
EnhancedResultObjectProxyImpl callback = new EnhancedResultObjectProxyImpl(type, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
//根据EnhancedResultObjectProxyImpl 创建compay的代理对象
Object enhanced = crateProxy(type, callback, constructorArgTypes, constructorArgs);
//之后是将原对象的属性copy进入代理对象
PropertyCopier.copyBeanProperties(type, target, enhanced);
return enhanced;
}
创建完代理对象后,然后获取:
JavassistProxyFactory#invoke方法
@Override
public Object invoke(Object enhanced, Method method, Method methodProxy, Object[] args) throws Throwable {
//原对象的method方法
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
//不会进这儿
if (WRITE_REPLACE_METHOD.equals(methodName)) {
Object original;
if (constructorArgTypes.isEmpty()) {
original = objectFactory.create(type);
} else {
original = objectFactory.create(type, constructorArgTypes, constructorArgs);
}
PropertyCopier.copyBeanProperties(type, enhanced, original);
if (lazyLoader.size() > 0) {
return new JavassistSerialStateHolder(original, lazyLoader.getProperties(), objectFactory, constructorArgTypes, constructorArgs);
} else {
return original;
}
} else {
//懒加载大于0并且不是finalize方法
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
//是否任意方法就加载或者在"equals", "clone", "hashCode", "toString"方法里面
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
//如果是set方法 则将懒加载移除,直接赋值
} else if (PropertyNamer.isSetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
lazyLoader.remove(property);
//为get方法,根据属性名称获取懒加载器有就加载
} else if (PropertyNamer.isGetter(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
lazyLoader.load(property);
}
}
}
}
}
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
ResultLoaderMap#load
public boolean load(String property) throws SQLException {
//取出LoadPair ,并且移除懒加载属性(懒加载之前所以如果pair.load()失败则不会进行二次加载)
LoadPair pair = loaderMap.remove(property.toUpperCase(Locale.ENGLISH));
if (pair != null) {
//开始加载
pair.load();
return true;
}
return false;
}
ResultLoaderMap$LoadPair#load
public void load(final Object userObject) throws SQLException {
if (this.metaResultObject == null || this.resultLoader == null) {
if (this.mappedParameter == null) {
throw new ExecutorException("Property [" + this.property + "] cannot be loaded because "
+ "required parameter of mapped statement ["
+ this.mappedStatement + "] is not serializable.");
}
final Configuration config = this.getConfiguration();
final MappedStatement ms = config.getMappedStatement(this.mappedStatement);
if (ms == null) {
throw new ExecutorException("Cannot lazy load property [" + this.property
+ "] of deserialized object [" + userObject.getClass()
+ "] because configuration does not contain statement ["
+ this.mappedStatement + "]");
}
this.metaResultObject = config.newMetaObject(userObject);
//这里有个ClosedExecutor 继承BaseExecutor,只是将isClosed设置为true
this.resultLoader = new ResultLoader(config, new ClosedExecutor(), ms, this.mappedParameter,
metaResultObject.getSetterType(this.property), null, null);
}
/* We are using a new executor because we may be (and likely are) on a new thread
* and executors aren't thread safe. (Is this sufficient?)
*
* A better approach would be making executors thread safe. */
//这段代码有点多余,因为上面已经赋值了,即使进去也是一样的
if (this.serializationCheck == null) {
final ResultLoader old = this.resultLoader;
this.resultLoader = new ResultLoader(old.configuration, new ClosedExecutor(), old.mappedStatement,
old.parameterObject, old.targetType, old.cacheKey, old.boundSql);
}
//设置属性值
//this.resultLoader.loadResult()
this.metaResultObject.setValue(property, this.resultLoader.loadResult());
}
ResultLoader#selectList
public Object loadResult() throws SQLException {
//通过executor 直接查询库
List<Object> list = selectList();
//设置值
resultObject = resultExtractor.extractObjectFromList(list, targetType);
return resultObject;
}
private <E> List<E> selectList() throws SQLException {
Executor localExecutor = executor;
if (Thread.currentThread(以上是关于(02)Cartographer源码无死角解析-(54) 2D后端优化→PoseGraphInterfacePoseGraphPoseGraph2D::AddNode()的主要内容,如果未能解决你的问题,请参考以下文章