YOLOv7训练自己的数据集(超详细)
Posted Mr Dinosaur
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv7训练自己的数据集(超详细)相关的知识,希望对你有一定的参考价值。
介绍
2022年7月,YOLOv7来临, 论文链接:https://arxiv.org/abs/2207.02696
代码链接:
废话不多说,赶紧上车!
文件配置
1、数据集
自己创建一个myself.yaml文件用来配置路径,路径格式与之前的V5、V6不同,只需要配置txt路径就可以
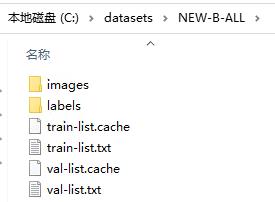
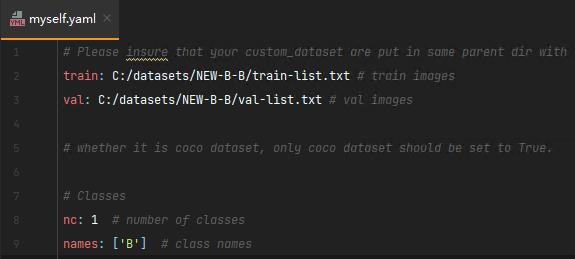
train-list.txt和val-list.txt文件里存放的都是图片的绝对路径(也可以放入相对路径)


如何获取图像的绝对路径,脚本写在下面了(也可以获取相对路径)
# From Mr. Dinosaur
import os
def listdir(path, list_name): # 传入存储的list
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
list_name = []
path = 'D:/PythonProject/data/' # 文件夹路径
listdir(path, list_name)
print(list_name)
with open('./list.txt', 'w') as f: # 要存入的txt
write = ''
for i in list_name:
write = write + str(i) + '\\n'
f.write(write)2、train.py
官网下载模型文件,train.py文件只支持YOLOv7和YOLOv7-X模型
train文件还是和V5一样,为了方便,我将需要用到的文件放在了根目录下
路径修改完之后右击运行即可
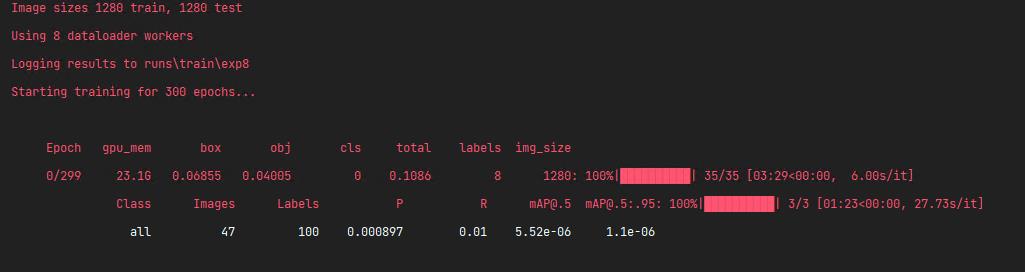
3、train_aux.py
如果你想使用较大的预训练模型,请使用train_aux.py进行训练,否则效果会很差(本人亲测)
下面放上对比图:(上面V7,下面V5)
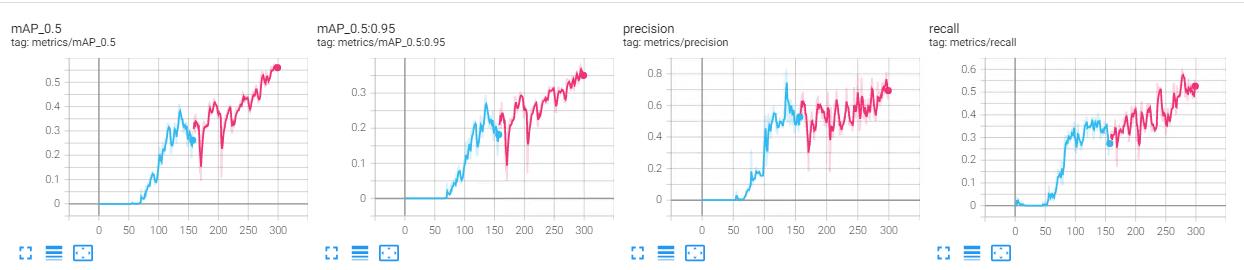
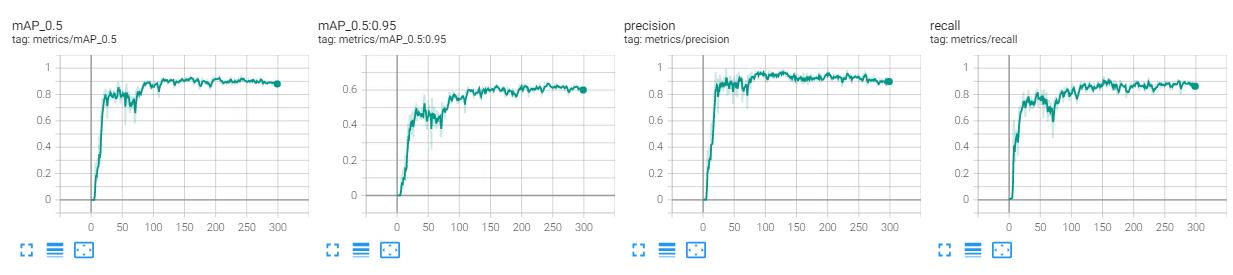
--weights
下载位置在官网的GitHub上(我是用的是yolov7-d6-training.pt)

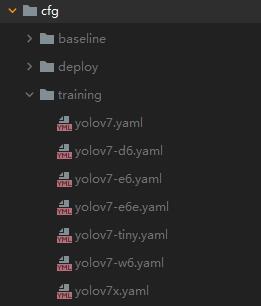
--cfg
请使用cfg-training-中的模型文件
--hyp
文件夹data-hyp.scratch.p6.yaml
运行train_aux.py
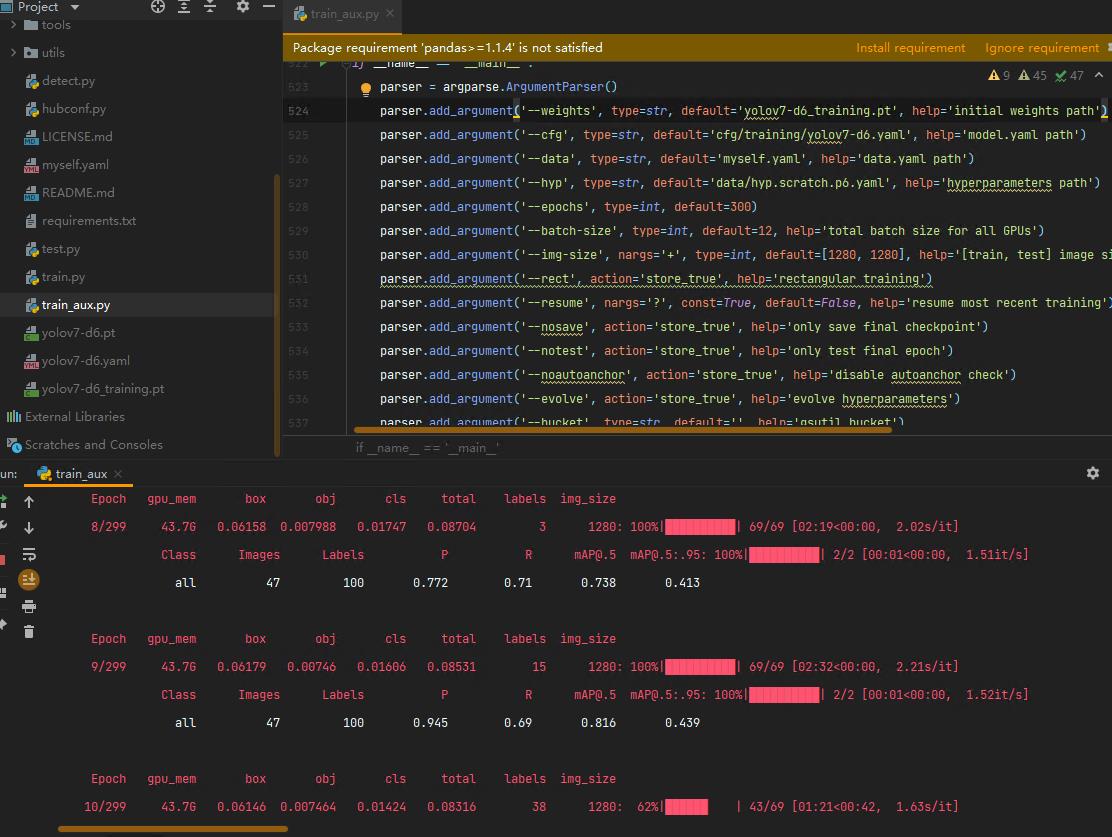
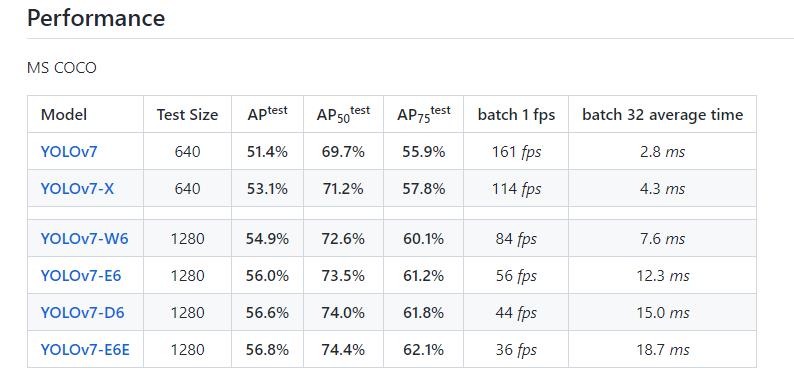
效果对比
在此放上YOLOv7和YOLOv5的对比图:(左V7,右V5)


报错解决
 https://blog.csdn.net/qq_58355216/article/details/125842647?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_58355216/article/details/125842647?spm=1001.2014.3001.5501评价
无论是训练的速度、还是精度、召回和map的提升,V7的表现都是十分显著的,称得上是YOLO界的扛把子,期待作者之后的优化和更新。
YOLOv8发布
官网的YOLOv8最近开始发布,效果要比V7更快更准,训练和测试方法已写好,感兴趣的小伙伴快动手操作一下
YOLOv8训练自己的数据集 https://blog.csdn.net/qq_58355216/article/details/128671030?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_58355216/article/details/128671030?spm=1001.2014.3001.5501
深入浅出Yolov5之自有数据集训练超详细教程
除了本文,大白还整理了如何深入浅出人工智能行业,算法、数据、目标检测、论文创新点、求职等版块的内容,可以查看:点击查看。
此外本文章Yolov5相关的代码、模型、数据等内容,可以查看下载:点击查看。
当然下方也列出了,如何通过官方链接的方式,下载的过程,也可以查看。
1 下载Yolov5代码及模型权重
1.1 下载Yolov5代码
登录github链接:https://github.com/ultralytics/yolov5,下载完整的代码。
1.2 下载Yolov5模型权重
在Yolov5模型权重页面,https://github.com/ultralytics/yolov5/releases
在下方选择相应的Yolov5各个pt权重文件。
放在Yolov5代码的models文件夹中。

2 下载一系列的依赖库
按照yolov5代码中requirements.txt中的说明,下载一系列的依赖库
3 对于推理功能进行测试
先使用预训练的模型,对于图片进行推理测试,看看效果。
修改detect.py里面的weights的路径,增加前面的models文件夹的路径。
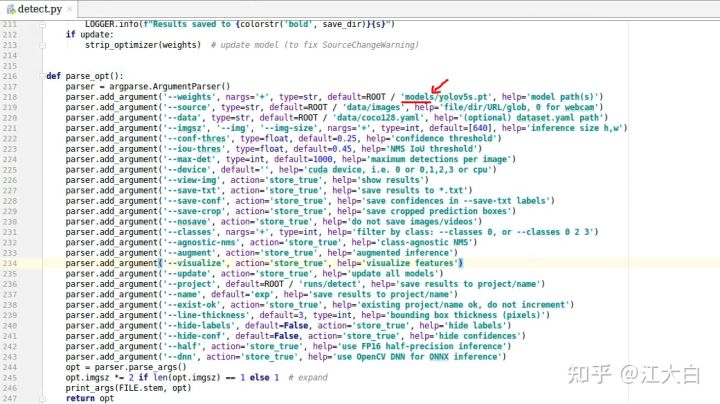
运行结束后,可以在运行结果看到信息:

打开runs/detect/exp可以看到推理得到的结果:
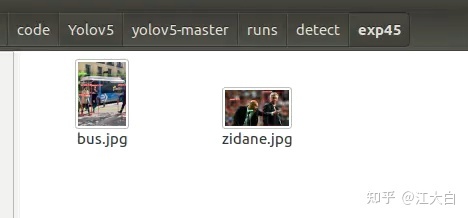
4 使用自有数据进行训练
4.1 数据&脚本&训练代码
大白为了让大家从0基础,就可以学会训练,准备了三个文件。
(1)data:人头数据集
为了便于大家学习,大白准备了一个教室场景下的人头数据集,放在data/head/classroom文件夹中。
数据集中,JPEGImages有4361张图片,Annotations有4361张xml文件。
(2)train_code:数据处理脚本
在train_code文件夹中,有三个python文件,主要使用的是get_labels.py和main.py两个脚本。
get_labels.py脚本,可以直接获取Annotations文件夹中,所有标注文件的标注类别。
而main.py脚本,可以将之前标注文件和图像,进行处理,转换成Yolov5可以训练的格式。
(3)yolov5-master:训练代码
这个文件夹里面就是Yolov5的训练测试代码,大家也可以直接使用大白提供的Yolov5代码。
4.2 查看自有数据集中的类别数
打开train_code/get_labels.py,修改下方的人头数据集路径。
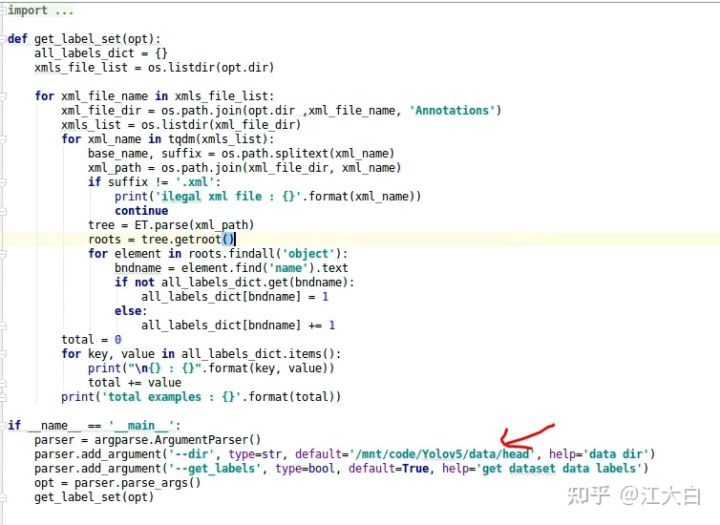
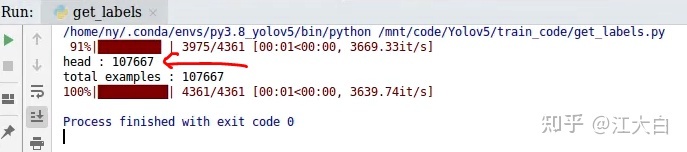
运行后,在下方就可以看到类别数,以及标注的类别框的数量。
4.3 转换训练数据格式
(1)新建数据集转换文件夹
首先在data文件夹里面,新建一个head_train_data文件夹。
并在head_train_data文件夹中,新建一个images_label_split文件夹。
并将前面的classroom数据集,直接拷贝到images_label_split里面。
(2)main.py脚本处理:配置修改
打开train_code/main.py文件,修改训练数据的路径。

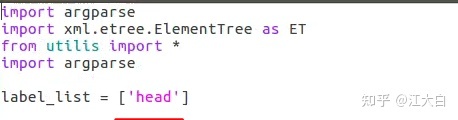
在前面通过get_labels.py脚本,我们也知道了当前数据集的类别数,比如主要是“head”,将该类别填入label_list中。
而main.py文件主要分为三个部分的功能:数据集的清洗、训练集&验证集划分、xml转换txt格式。
(3)main.py脚本处理:数据集清洗
数据集的清洗使用的主要是这些行的代码。

有的数据集有图片,没有标注文件。有的数据集有标注文件,图片有可能丢失。
同时将长宽比太小的框删除掉,并且在删除后,检查下是否存在空的标注文件,如果有,也删除。
并在最后,将标注的框显示到图片上,进一步确定脚本是否正确。
运行上面的代码,最后会跳出来一些画了人头框的图片。

(4)main.py脚本处理:训练集&验证集划分
训练集&验证集划分的代码主要是这一行代码。

0.2表示,80%的数据进行训练,20%的数据进行验证。
运行结束后,会发现head_train_data这个文件夹下面多了两个文件夹,train和test,就是按照80%、20%进行划分。
(5)main.py脚本处理::xml转换txt格式
xml转换成txt格式的代码主要是下面三行。

运行结束后,可以看到多了两个文件夹。

image_txt文件夹中是所有的image和转换完的txt文件、
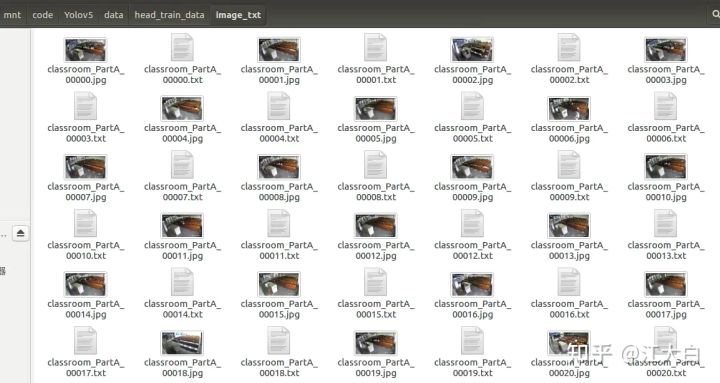
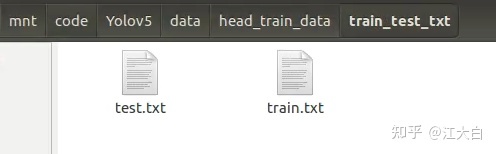
而train_test_txt文件夹中,则是对于训练和测试数据路径汇总的两个txt,后面训练中会用到。
4.4 Yolov5代码训练
4.4.1 修改训练配置
(1)新建一个yaml文件
因为是训练人头数据集,所以在data文件夹下先新建一个head.yaml文件,并修改其中的参数。
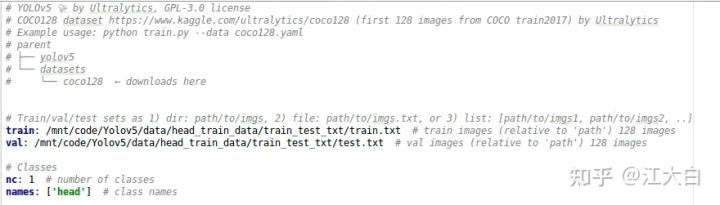
可以复制一个coco.yaml文件进行修改,其中主要涉及到训练集的txt文件、验证集的txt文件、类别数量nc、类别标签名。
(2)修改train.py参数
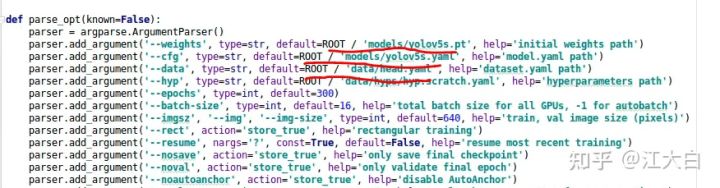
① 修改models里面的weights路径,大白下载了一些pt文件放在models中,可以选择使用。
② 修改cfg路径,即网络结构的参数配置文件,需要注意的是,需要修改其中的类别数。
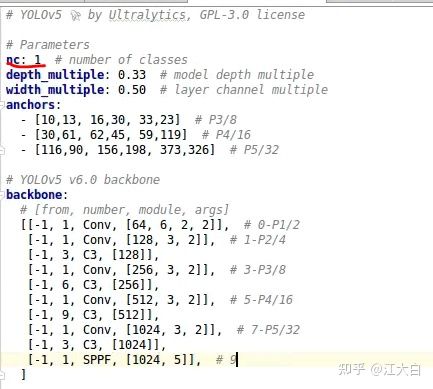
③ 修改data的路径,即前面修改的head.yaml文件。
4.4.2 开始训练
运行train.py文件,既可以开始训练。

可以看到网络收敛的很快。
4.4.3 训练结果测试
网络训练到一段时间后,可以使用detect.py脚本对于训练的模型,进行测试了,不过需要修改是三个参数:
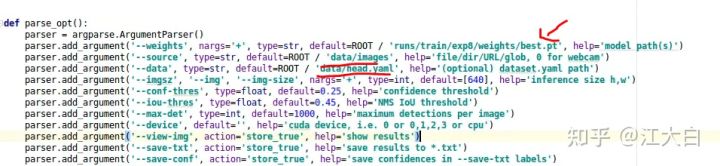
① weights:即前面训练好得到的权重文件
② source:即需要检测的图片数据集
③ data:修改成head.yaml
运行detect.py文件后,可以在runs/detect/exp最后一个文件夹中得到检测的效果图片:

以上就是Yolov5的详细训练过程,其中每一步大白都是经过详细的测试的,可以下载对应的代码、权重,进行尝试。
以上是关于YOLOv7训练自己的数据集(超详细)的主要内容,如果未能解决你的问题,请参考以下文章