sql 怎么递归查询的方法:
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql 怎么递归查询的方法:相关的知识,希望对你有一定的参考价值。
有个部门表,假设有三个字段Id,deptId,upperDeptId,现在我想查询指定部门下的所有部门,该怎么办,不要用start with connect by prior
1.创建测试表,createtabletest_connect(idnumber,p_idnumber);
2.插入测试数据,
Insertintotest_connectvalues(1,1);
Insertintotest_connectvalues(2,1);
Insertintotest_connectvalues(3,2);
Insertintotest_connectvalues(4,3);
提交;

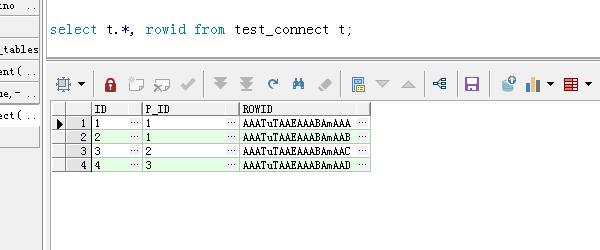
3.查询数据表的内容,选择*fromtest_connect,
4.执行递归查询语句,将答案添加到nocycle元素中,就不会有[ora-01436:CONNECTBYerrorintheuserdata]。执行结果如下:
Select*
来自test_connectt
从id=4开始
由nocyclepriort连接。p_id=t.i.

WITH TEMP AS (SELECT Id,deptId,upperDeptId FROM PRODCLAS WHERE 上级部门字段='' UNION ALL
SELECT B.Id,B.deptId,B.upperDeptId FROM TEMP A
INNER JOIN 部门资料表 B ON B.上级部门字段 = A.当前部门字段)
SELECT 当前部门 FROM TEMP
向下递归查询
参考技术B sql 递归查询的方法:方法一:T-SQL递归查询
with Dep as
(
select Id,DeptCode,DeptName from Department where Id=1
union all
select d.Id,d.DeptCode,d.DeptName from Dep
inner join Department d on dep.Id = d.ParentDeptId
)
select * from Dep
方法二:PL/SQL递归查询
select Id,DeptCode,DeptName
from Department
start with Id = 1
connect by prior Id = ParentDeptId; 参考技术C 递归查询貌似只是oracle单独提供出来的。其他数据库没有提供递推查询吧。。。。
我当时做的项目是通过一个公司查出所有的子公司和子公司的子公司。。。
我做第一个项目的时候就是用的start with connect by prior做的。没找到其他递归方法。。
第二个项目的时候,这种树形结构有可能无限层,这个时候start with connect by prior也就不可靠了,速度慢。如果这个表可以新增一个字段,建议你加一个字段,当时我取名叫nodeIds,varchar类型的,用来存放父类的nodeIds+自己的id。
比如说顶层部门的id为1,那么该部门的nodeIds就是,1,,然后他下一层部门id是2,则这个部门的nodeIds的值就是,1,2,....id是2的部门的下一层部门id为3的话,则这个部门的nodeIds的值就是,1,2,3,,这样的话,你就完全好查询的。。。通过传入id所对应的部门的nodeIds去like一下,就获得了他及其所有子部门。
比如你要查id是1的所有子部门,那么你就拿,1,去数据库like一下,那么,1, ,1,2, ,1,2,3, 都拿出来了。。。后面两个肯定是前面那个的子部门。。。
不知道这样讲你能不能看懂,不懂再追问哈。追问
嗯,你说的这个方法貌似可行,但是使用like的查询的话,他是全表查询,如果表很大的话,会导致负载过大吧。start with connect by prior这个只用oracle有,其实我现在用的是jpql,jpql是不支持这个语法的,所以想找个别的方法。我想你这个方法还不错,谢了
追答如果层数过多,这个应该算是一种较优的算法了,我反正还没见过比这个好的解决大量层递归查询的方法。这个方法当然也不是我想出来的,我还没那么大本事。这个算法在10亿条数据之内绝对不可能慢的。因为我一个朋友是在一个数据量相当庞大的公司工作的(这个公司我不方便透露),这个想法就是从他那里借鉴的,他们都是采用新增一个字段代替递归查询。
本回答被提问者采纳MYSQL 8.019 CTE 递归查询怎么解决死循环三种方法

MYSQL CTE 是8.0 引入的SQL 查询的一种功能,通过CTE 可以将复杂的SQL 变得简单,便于分析和查询. 其中CTE 有一种功能递归, 并且牵扯到递归就会有一个问题的提出,就是无限递归的问题.
下面是一个递归死循环的例子

这里先解释一下CTE 递归
1 递归查询至少包含两个子查询, 第一个查询的目的是设置递归的初始值
2 第二个查询成为递归查询,第二个查询调用第一个查询的结果,然后开始循环
之间通过union all 来连接.
递归查询中,当查询的结果不匹配,或超过了递归次数就会停止. 或者在执行是系统发现是死循环则会在设定好的最大cte_max_recursion_depth 后终止查询.

递归查询中出现3636的问题,分为两种
1 数据出现问题 (这是引起递归出现问题的常见原因)
2 SQL 递归的撰写有问题
根据1 出现问题的概率比较大,并且比较难以排查, 这里就需要在写SQL 的时候,添加一些语句来避免递归出现问题.
1 方法一, 使用distinct ,通过在union 后面添加distinct 来将重复的数据去掉,大部分死循环是因为有重复的数据,这样可以查出数据. 但问题是在 WORKBENCH 中是可以的,但将语句在 MYSQL 程序中是报错的,这点我也没法解释.


2 方法 在MYSQL 8.109 引入了 LIMIT 语句,通过LIMIT 来限制输出数据的数量,投机取巧的避免了部分 3636 的错误


这个方式在workbench 和 MYSQL 命令符下都是OK 的.
实际当中,可能用的最多的是另外一种方式,自动设置让死循环结束

WITH RECURSIVE cte_all AS
(
SELECT dname AS Child
FROM cte_test
WHERE rname=Tim
UNION all
SELECT r.dname
FROM cte_test r, cte_all d
WHERE r.rname=d.Child
)
SELECT /*+ MAX_EXECUTION_TIME(1000) */ * FROM cte_all;
这样的写法在workbench 是OK 的,但在MYSQL 命令行中是还是不可以

当然绕来绕去,最关键的还是修复导致死循环的数据

在修复数据后,在此执行查询,问题解决.
以上几种方法,各有利弊,在软件开发中也有递归函数,当然现在开发的过程中好像在规避递归类似的算法. 但在SQL 的撰写中如果业务逻辑合适, 递归会将SQL 写的比较简单,但需要给定的数据要符合一定的规律,以上的方式均是想通过一定方式来规避由于数据问题,产生的递归问题.

以上是关于sql 怎么递归查询的方法:的主要内容,如果未能解决你的问题,请参考以下文章