Flink Checkpoint机制分析
Posted Fred^_^
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Checkpoint机制分析相关的知识,希望对你有一定的参考价值。
原创作品,转载请标明:http://blog.csdn.net/xiejingfa/article/details/105439802
可靠性是分布式系统实现必须考虑的因素之一。Flink基于Chandy-Lamport分布式快照算法实现了一套可靠的Checkpoint机制,可以保证集群中某些节点出现故障时,能够将整个作业恢复到故障之前某个状态。同时,Checkpoint机制也是Flink实现Exactly-Once语义的基础。
本文将介绍Flink的Checkpoint机制的原理,并从源码层面了解Checkpoint机制是如何实现的(基于Flink 1.10)。
1. 为什么需要Checkpoint
Flink是有状态的流计算处理引擎,每个算子Operator可能都需要记录自己的运行数据,并在接收到新流入的元素后不断更新自己的状态数据。当分布式系统引入状态计算后,为了保证计算结果的正确性(特别是对于流处理系统,不可能每次系统故障后都从头开始计算),就必然要求系统具有容错性。对于Flink来说,Flink作业运行在多个节点上,当出现节点宕机、网络故障等问题,需要一个机制保证节点保存在本地的状态不丢失。流处理中Exactly-Once语义的实现也要求作业从失败恢复后的状态要和失败前的状态一致。
那么怎么保证分布式环境下各节点状态的容错呢?通常这是通过定期对作业状态和数据流进行快照实现的,常见的检查点算法有比如Sync-and-Stop(SNS)算法、Chandy-Lamport(CL)算法。
Flink的Checkpoint机制是基于Chandy-Lamport算法的思想改进而来,引入了Checkpoint Barrier的概念,可以在不停止整个流处理系统的前提下,让每个节点独立建立检查点保存自身快照,并最终达到整个作业全局快照的状态。有了全局快照,当我们遇到故障或者重启的时候就可以直接从快照中恢复,这就是Flink容错的核心。
2. Checkpoint执行流程
Barrier是Flink分布式快照的核心概念之一,称之为屏障或者数据栅栏(可以理解为快照的分界线)。Barrier是一种特殊的内部消息,在进行Checkpoint的时候Flink会在数据流源头处周期性地注入Barrier,这些Barrier会作为数据流的一部分,一起流向下游节点并且不影响正常的数据流。Barrier的作用是将无界数据流从时间上切分成多个窗口,每个窗口对应一系列连续的快照中的一个,每个Barrier都带有一个快照ID,一个Barrier生成之后,在这之前的数据都进入此快照,在这之后的数据则进入下一个快照。
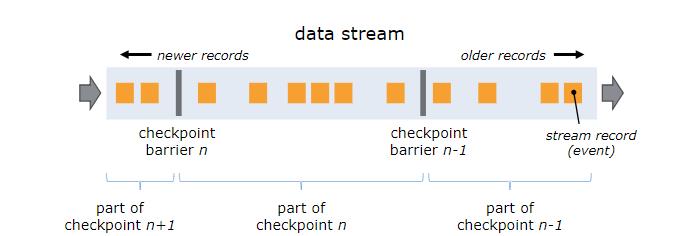
如上图,Barrier-n跟随着数据流一起流动,当算子从输入流接收到Barrier-n后,就会停止接收数据并对当前自身的状态做一次快照,快照完成后再将Barrier-n以广播的形式传给下游节点。一旦作业的Sink算子接收到Barrier n后,会向JobMnager发送一个消息,确认Barrier-n对应的快照完成。当作业中的所有Sink算子都确认后,意味一次全局快照也就完成。
当一个算子有多个上游节点时,会接收到多个Barrier,这时候需要进行Barrier Align对齐操作。

如上图,一个算子有两个输入流,当算子从一个上游数据流接收到一个Barrier-n后,它不会立即向下游广播,而是先暂停对该数据流的处理,将到达的数据先缓存在Input Buffer中(因为这些数据属于下一次快照而不是当前快照,缓存数据可以不阻塞该数据流),直到从另外一个数据流中接收到Barrier-n,才会进行快照处理并将Barrier-n向下游发送。从这个流程可以看出,如果开启Barrier对齐后,算子由于需要等待所有输入节点的Barrier到来出现暂停,对整体的性能也会有一定的影响。
综上,Flink Checkpoint机制的核心思想实质上是通过Barrier来标记触发快照的时间点和对应需要进行快照的数据集,将数据流处理和快照操作解耦开来,从而最大程度降低快照对系统性能的影响。
Flink的一致性和Checkpoint机制有紧密的关系:
- 当不开启Checkpoint时,节点发生故障时可能会导致数据丢失,这就是At-Most-Once
- 当开启Checkpoint但不进行Barrier对齐时,对于有多个输入流的节点如果发生故障,会导致有一部分数据可能会被处理多次,这就是At-Least-Once
- 当开启Checkpoint并进行Barrier对齐时,可以保证每条数据在故障恢复时只会被重放一次,这就是Exactly-Once
3. Checkpoint相关配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- 默认情况下,Checkpoint机制是关闭的,需要通过enableCheckpointing(interval)来开启,并指定每interval毫秒进行一次Checkpoint。
- Checkpoint模式支持Exactly-Once和At-Least-Once,可以通过setCheckpointingMode来设置。
- 如果两次Checkpoint的时间很短,会导致整个系统大部分资源都用于执行Checkpoint,影响正常作业的执行。可以通过setMinPauseBetweenCheckpoints来设置两次Checkpoint之间的最小间隔。
- setCheckpointTimeout可以给Checkpoint设置一个超时时间,当一次Checkpoint超过一定时间没有完成,直接终止掉。
- 默认情况下,当一个Checkpoint还在执行时,不会触发另一个Checkpoint,通过setMaxConcurrentCheckpoints可以设置最大并发Checkpoint数量。
- enableExternalizedCheckpoints可以设置当用户取消了作业后,是否保留远程存储上的Checkpoint数据,一般设置为RETAIN_ON_CANCELLATION。
4. Checkpoint过程源码分析
4.1 Client端生成Checkpoint配置
Client端在向JobManger提交作业前会根据用户代码生成StreamGraph,再转化为JobGraph,在构建JobGraph时会调用configureCheckpointing生成JobCheckpointingSettings配置并保存在JobGraph中。这里要注意到triggerVertices这个集合,它表示Flink通过这些节点触发Checkpoint。在构建JobGraph时只会将Source节点加入到triggerVertices,决定Flink之后发起Checkpoint时只针对Source节点注入Barrier。
private void configureCheckpointing()
CheckpointConfig cfg = streamGraph.getCheckpointConfig();
...(省略部分代码,只展示核心流程,下同)
// --- configure the participating vertices ---
// collect the vertices that receive "trigger checkpoint" messages.
// currently, these are all the sources
List<JobVertexID> triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint
// currently, these are all vertices
List<JobVertexID> ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages
// currently, these are all vertices
List<JobVertexID> commitVertices = new ArrayList<>(jobVertices.size());
for (JobVertex vertex : jobVertices.values())
// 这里只会将Source节点加入到triggerVertices
if (vertex.isInputVertex())
triggerVertices.add(vertex.getID());
commitVertices.add(vertex.getID());
ackVertices.add(vertex.getID());
// settings将所有Checkpoint配置封装在一起
jobGraph.setSnapshotSettings(settings);
4.2 JobManager发起Checkpoint
CheckpointCoordinator是Flink执行Checkpoint的核心组件,JobManager在接收到Client端的SubmitJob请求后将JobGraph转化为ExecutionGraph,并调用enableCheckpointing方法初始化CheckpointCoordinator,然后为CheckpointCoordinator注册一个Job状态变化的监听器CheckpointCoordinatorDeActivator。
public void enableCheckpointing()
...
// create the coordinator that triggers and commits checkpoints and holds the state
checkpointCoordinator = new CheckpointCoordinator(
jobInformation.getJobId(),
chkConfig,
tasksToTrigger,
tasksToWaitFor,
tasksToCommitTo,
checkpointIDCounter,
checkpointStore,
checkpointStateBackend,
ioExecutor,
new ScheduledExecutorServiceAdapter(checkpointCoordinatorTimer),
SharedStateRegistry.DEFAULT_FACTORY,
failureManager);
if (chkConfig.getCheckpointInterval() != Long.MAX_VALUE)
// the periodic checkpoint scheduler is activated and deactivated as a result of
// job status changes (running -> on, all other states -> off)
registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
CheckpointCoordinatorDeActivator实现了JobStatusListener接口,当job状态变成Running时,调用startCheckpointScheduler方法开启CheckpointScheduler,当job变成其他状态时,调用stopCheckpointScheduler方法停止CheckpointScheduler。
public class CheckpointCoordinatorDeActivator implements JobStatusListener
private final CheckpointCoordinator coordinator;
public CheckpointCoordinatorDeActivator(CheckpointCoordinator coordinator)
this.coordinator = checkNotNull(coordinator);
@Override
public void jobStatusChanges(JobID jobId, JobStatus newJobStatus, long timestamp, Throwable error)
if (newJobStatus == JobStatus.RUNNING)
// start the checkpoint scheduler
coordinator.startCheckpointScheduler();
else
// anything else should stop the trigger for now
coordinator.stopCheckpointScheduler();
接下来我们来看下startCheckpointScheduler,startCheckpointScheduler首先调用stopCheckpointScheduler确保之前的Checkpoint Scheduler已经停止,然后再创建一个新的ScheduledTrigger放到线程池中定时执行triggerCheckpoint方法触发Checkpoint。第3小节中提到的enableCheckpointing(interval)方法可以设置Checkpoint执行的时间间隔,背后的原理就在这里。
public void startCheckpointScheduler()
synchronized (lock)
if (shutdown)
throw new IllegalArgumentException("Checkpoint coordinator is shut down");
// make sure all prior timers are cancelled
stopCheckpointScheduler();
periodicScheduling = true;
currentPeriodicTrigger = scheduleTriggerWithDelay(getRandomInitDelay());
private ScheduledFuture<?> scheduleTriggerWithDelay(long initDelay)
return timer.scheduleAtFixedRate(
new ScheduledTrigger(),
initDelay, baseInterval, TimeUnit.MILLISECONDS);
private final class ScheduledTrigger implements Runnable
@Override
public void run()
try
triggerCheckpoint(System.currentTimeMillis(), true);
catch (Exception e)
LOG.error("Exception while triggering checkpoint for job .", job, e);
triggerCheckpoint是触发Checkpoint的核心方法,下面介绍一些它主要做了哪些工作。
- 检查当前正在处理的并发Checkpoint数是否超过阈值和距离上一次Checkpoint是否小于设置的最小间隔。如果条件不满足,直接返回。
// preCheckBeforeTriggeringCheckpoint是在triggerCheckpoint中调用的方法
private void preCheckBeforeTriggeringCheckpoint(boolean isPeriodic, boolean forceCheckpoint) throws CheckpointException
// abort if the coordinator has been shutdown in the meantime
if (shutdown)
throw new CheckpointException(CheckpointFailureReason.CHECKPOINT_COORDINATOR_SHUTDOWN);
// Don't allow periodic checkpoint if scheduling has been disabled
if (isPeriodic && !periodicScheduling)
throw new CheckpointException(CheckpointFailureReason.PERIODIC_SCHEDULER_SHUTDOWN);
if (!forceCheckpoint)
if (triggerRequestQueued)
throw new CheckpointException(CheckpointFailureReason.ALREADY_QUEUED);
checkConcurrentCheckpoints();
checkMinPauseBetweenCheckpoints();
- 检查所有需要被trigger和ack的Task是否都处于运行状态,只要有一个Task不满足条件,就没有必要触发本次Checkpoint了。
// check if all tasks that we need to trigger are running.
// if not, abort the checkpoint
Execution[] executions = new Execution[tasksToTrigger.length];
for (int i = 0; i < tasksToTrigger.length; i++)
Execution ee = tasksToTrigger[i].getCurrentExecutionAttempt();
if (ee == null)
throw new CheckpointException(CheckpointFailureReason.NOT_ALL_REQUIRED_TASKS_RUNNING);
else if (ee.getState() == ExecutionState.RUNNING)
executions[i] = ee;
else
throw new CheckpointException(CheckpointFailureReason.NOT_ALL_REQUIRED_TASKS_RUNNING);
// next, check if all tasks that need to acknowledge the checkpoint are running.
// if not, abort the checkpoint
Map<ExecutionAttemptID, ExecutionVertex> ackTasks = new HashMap<>(tasksToWaitFor.length);
for (ExecutionVertex ev : tasksToWaitFor)
Execution ee = ev.getCurrentExecutionAttempt();
if (ee != null)
ackTasks.put(ee.getAttemptId(), ev);
else
throw new CheckpointException(CheckpointFailureReason.NOT_ALL_REQUIRED_TASKS_RUNNING);
- 只有上面两次检查都通过后,才会正在进入Checkpoint的处理流程。首先生成一个新的CheckpointID,再创建一个PendingCheckpoint对象。PendingCheckpoint是一个启动但还未被确认的Checkpoint。等到所有Task都确认后又会转化为CompletedCheckpoint。
// we will actually trigger this checkpoint!
final CheckpointStorageLocation checkpointStorageLocation;
final long checkpointID;
try
// this must happen outside the coordinator-wide lock, because it communicates
// with external services (in HA mode) and may block for a while.
checkpointID = checkpointIdCounter.getAndIncrement();
catch (Throwable t)
...
final PendingCheckpoint checkpoint = new PendingCheckpoint(
job,
checkpointID,
timestamp,
ackTasks,
masterHooks.keySet(),
props,
checkpointStorageLocation,
executor);
- 为了防止Checkpoint长时间未完成而占用资源,CheckpointCoordinator还会创建一个取消器用于清理超时的Checkpoint。
// schedule the timer that will clean up the expired checkpoints
final Runnable canceller = () ->
synchronized (lock)
// only do the work if the checkpoint is not discarded anyways
// note that checkpoint completion discards the pending checkpoint object
if (!checkpoint.isDiscarded())
failPendingCheckpoint(checkpoint, CheckpointFailureReason.CHECKPOINT_EXPIRED);
pendingCheckpoints.remove(checkpointID);
rememberRecentCheckpointId(checkpointID);
triggerQueuedRequests();
;
ScheduledFuture<?> cancellerHandle = timer.schedule(canceller, checkpointTimeout, TimeUnit.MILLISECONDS);
- 最后向Source节点发送消息,触发Checkpoint。
// send the messages to the tasks that trigger their checkpoint
for (Execution execution: executions)
if (props.isSynchronous())
execution.triggerSynchronousSavepoint(checkpointID, timestamp, checkpointOptions, advanceToEndOfTime);
else
execution.triggerCheckpoint(checkpointID, timestamp, checkpointOptions);
4.3 TaskManager执行Checkpoint
TaskManager执行Checkpoint操作要分以下两种情况来讨论:
- Source节点接收到JobManager发送的TriggerCheckpoint消息后触发本节点Checkpoint。
- 非Source节点从上游接收到Barrier后触发本节点Checkpoint,这里可能还会涉及到Barrier对齐操作。
4.3.1 Source节点执行Checkpoint
下面先来看看Source节点是如何执行Checkpoint的。
TaskManager接收到JobManager的TriggerCheckpoint消息后,经过层层调用最后使用AbstractInvokable的triggerCheckpointAsync方法来处理。AbstractInvokable是对在TaskManager中可执行任务的抽象。triggerCheckpointAsync的具体实现在AbstractInvokable的子类StreamTask中,其核心逻辑就是使用线程池异步调用triggerCheckpoint方法。
public Future<Boolean> triggerCheckpointAsync(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
boolean advanceToEndOfEventTime)
return mailboxProcessor.getMainMailboxExecutor().submit(
() -> triggerCheckpoint(checkpointMetaData, checkpointOptions, advanceToEndOfEventTime),
"checkpoint %s with %s",
checkpointMetaData,
checkpointOptions);
private boolean triggerCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
boolean advanceToEndOfEventTime) throws Exception
try
...
boolean success = performCheckpoint(checkpointMetaData, checkpointOptions, checkpointMetrics, advanceToEndOfEventTime);
if (!success)
declineCheckpoint(checkpointMetaData.getCheckpointId());
return success;
catch (Exception e)
...
StreamTask的triggerCheckpoint会调用performCheckpoint方法,该方法主要工作包括:
- 创建Checkpoint Barrier并向下游节点广播。
- 触发本节点的快照操作。
private boolean performCheckpoint(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetrics checkpointMetrics,
boolean advanceToEndOfTime) throws Exception
...
final long checkpointId = checkpointMetaData.getCheckpointId();
if (isRunning)
actionExecutor.runThrowing(() ->
...
// All of the following steps happen as an atomic step from the perspective of barriers and
// records/watermarks/timers/callbacks.
// We generally try to emit the checkpoint barrier as soon as possible to not affect downstream
// checkpoint alignments
// Step (1): Prepare the checkpoint, allow operators to do some pre-barrier work.
// The pre-barrier work should be nothing or minimal in the common case.
operatorChain.prepareSnapshotPreBarrier(checkpointId);
// Step (2): Send the checkpoint barrier downstream
operatorChain.broadcastCheckpointBarrier(
checkpointId,
checkpointMetaData.getTimestamp(),
checkpointOptions);
// Step (3): Take the state snapshot. This should be largely asynchronous, to not
// impact progress of the streaming topology
checkpointState(checkpointMetaData, checkpointOptions, checkpointMetrics);
);
return true;
else
...
return false;
checkpointState方法进一步调用executeCheckpointing对本地的State进行保存,该方法被封装在CheckpointingOperation类中,其核心工作包括:
- 调用每一个StreaOperator的snapshotState方法生成快照并存储到状态后端。
- 检查Checkpoint结果并告诉JobManager。
public void executeCheckpointing() throws Exception
startSyncPartNano = System.nanoTime();
try
// 调用每一个算子的snapshotState方法
for (StreamOperator<?> op : allOperators)
checkpointStreamOperator(op);
startAsyncPartNano = System.nanoTime();
checkpointMetrics.setSyncDurationMillis((startAsyncPartNano - startSyncPartNano) / 1_000_000);
// we are transferring ownership over snapshotInProgressList for cleanup to the thread, active on submit
AsyncCheckpointRunnable asyncCheckpointRunnable = new AsyncCheckpointRunnable(
owner,
operatorSnapshotsInProgress,
checkpointMetaData,
checkpointMetrics,
startAsyncPartNano);
owner.cancelables.registerCloseable(asyncCheckpointRunnable);
// 检查结果并报告JobManager
owner.asyncOperationsThreadPool.execute(asyncCheckpointRunnable);
catch (Exception ex)
...
private void checkpointStreamOperator(StreamOperator<?> op) throws Exception
if (null != op)
OperatorSnapshotFutures snapshotInProgress = op.snapshotState(
checkpointMetaData.getCheckpointId(),
checkpointMetaData.getTimestamp(),
checkpointOptions,
storageLocation);
operatorSnapshotsInProgress.put(op.getOperatorID(), snapshotInProgress);
如果Checkpoint执行成功,AsyncCheckpointRunnable最后会调用TaskStateManagerImpl的reportTaskStateSnapshots方法向JobManager发送AcknowledgeCheckpoint消息。
public void reportTaskStateSnapshots(
@Nonnull CheckpointMetaData checkpointMetaData,
@Nonnull CheckpointMetrics checkpointMetrics,
@Nullable TaskStateSnapshot acknowledgedState,
@Nullable TaskStateSnapshot localState)
long checkpointId = checkpointMetaData.getCheckpointId();
localStateStore.storeLocalState(checkpointId, localState);
checkpointResponder.acknowledgeCheckpoint(
jobId,
executionAttemptID,
checkpointId,
checkpointMetrics,
acknowledgedState);
4.3.1 非Source节点执行Checkpoint
下游的非Source节点接收到Barrier后,调用CheckpointBarrierAligner的processBarrier方法来处理。processBarrier会分别处理单个Input Channel和多个Input Channel两个不同场景,具体为:
- 如果只有一个Input Channel,收到Barrier后直接调用notifyCheckpoint触发快照。
- 如果包含多个Input Channel, 先执行Barrier对齐,收到所有Input Channel发送的Barrier后再调用notifyCheckpoint触发快照。
public boolean processBarrier(CheckpointBarrier receivedBarrier, int channelIndex, long bufferedBytes) throws Exception
final long barrierId = receivedBarrier.getId();
// fast path for single channel cases
if (totalNumberOfInputChannels == 1)
if (barrierId > currentCheckpointId)
// new checkpoint
currentCheckpointId = barrierId;
notifyCheckpoint(receivedBarrier, bufferedBytes, latestAlignmentDurationNanos);
return false;
boolean checkpointAborted = false;
// -- general code path for multiple input channels --
if (numBarriersReceived > 0)
// this is only true if some alignment is already progress and was not canceled
if (barrierId == currentCheckpointId)
// regular case
onBarrier(channelIndex);
else if (barrierId > currentCheckpointId)
...
// abort the current checkpoint
releaseBlocksAndResetBarriers();
checkpointAborted = true;
// begin a the new checkpoint
beginNewAlignment(barrierId, channelIndex);
else
// ignore trailing barrier from an earlier checkpoint (obsolete now)
return false;
else if (barrierId > currentCheckpointId)
// first barrier of a new checkpoint
beginNewAlignment(barrierId, channelIndex);
else
// either the current checkpoint was canceled (numBarriers == 0) or
// this barrier is from an old subsumed checkpoint
return false;
// check if we have all barriers - since canceled checkpoints always have zero barriers
// this can only happen on a non canceled checkpoint
if (numBarriersReceived + numClosedChannels == totalNumberOfInputChannels)
// actually trigger checkpoint
releaseBlocksAndResetBarriers();
notifyCheckpoint(receivedBarrier, bufferedBytes, latestAlignmentDurationNanos);
return true;
return checkpointAborted;
toNotifyOnCheckpoint是AbstractInvokable实例,triggerCheckpointOnBarrier方法最终调用了performCheckpoint方法,这后面的逻辑就跟Source节点一样了。可以看出:Source节点和非Source节点执行快照的逻辑是一致的,不同的是触发快照的机制。Source节点接收到JobManager发送的TriggerCheckpoint消息触发快照,非Source节点接收到上游节点的Barrier后触发快照。
// CheckpointBarrierHandler
protected void notifyCheckpoint(CheckpointBarrier checkpointBarrier, long bufferedBytes, long alignmentDurationNanos) throws Exception
if (toNotifyOnCheckpoint != null)
CheckpointMetaData checkpointMetaData =
new CheckpointMetaData(checkpointBarrier.getId(), checkpointBarrier.getTimestamp());
...
toNotifyOnCheckpoint.triggerCheckpointOnBarrier(
checkpointMetaData,
checkpointBarrier.getCheckpointOptions(),
checkpointMetrics);
// StreamTask
public void triggerCheckpointOnBarrier(
CheckpointMetaData checkpointMetaData,
CheckpointOptions checkpointOptions,
CheckpointMetrics checkpointMetrics) throws Exception
try
if (performCheckpoint(checkpointMetaData, checkpointOptions, checkpointMetrics, false))
if (isSynchronousSavepointId(checkpointMetaData.getCheckpointId()))
runSynchronousSavepointMailboxLoop();
catch (Exception e)
...
4.4 JobManager确认Checkpoint
JobManager收到Task的AcknowledgeCheckpoint消息后,会调用CheckpointCoordinator的receiveAcknowledgeMessage方法来处理。PendingCheckPoint中记录了本次Checkpoint中有哪些Task需要Ack,如果JobManager已经收到所有的Task的Ack消息,则调用completePendingCheckpoint向Task发送notifyCheckpointComplete消息通知Task本次Checkpoint已经完成。
final PendingCheckpoint checkpoint = pendingCheckpoints.get(checkpointId);
if (checkpoint != null && !checkpoint.isDiscarded())
switch (checkpoint.acknowledgeTask(message.getTaskExecutionId(), message.getSubtaskState(), message.getCheckpointMetrics()))
case SUCCESS:
if (checkpoint.areTasksFullyAcknowledged())
completePendingCheckpoint(checkpoint);
break;
...
private void completePendingCheckpoint(PendingCheckpoint pendingCheckpoint) throws CheckpointException
...
// send the "notify complete" call to all vertices
final long timestamp = completedCheckpoint.getTimestamp();
for (ExecutionVertex ev : tasksToCommitTo)
Execution ee = ev.getCurrentExecutionAttempt();
if (ee != null)
ee.notifyCheckpointComplete(checkpointId, timestamp);
TaskManager收到notifyCheckpointComplete消息后,最终调用Task的notifyCheckpointComplete方法回调每一个算子的notifyCheckpointComplete方法。
// TaskExecutor
public CompletableFuture<Acknowledge> confirmCheckpoint(
ExecutionAttemptID executionAttemptID,
long checkpointId,
long checkpointTimestamp)
final Task task = taskSlotTable.getTask(executionAttemptID);
if (task != null)
task.notifyCheckpointComplete(checkpointId);
return CompletableFuture.completedFuture(Acknowledge.get());
else
...
// StreamTask
private void notifyCheckpointComplete(long checkpointId)
try
boolean success = actionExecutor.call(() ->
if (isRunning)
for (StreamOperator<?> operator : operatorChain.getAllOperators())
if (operator != null)
operator.notifyCheckpointComplete(checkpointId);
return true;
...
);
catch (Exception e)
...
至此,一次完整的Checkpoint过程就完成了。
参考:
- Lightweight Asynchronous Snapshots for Distributed Dataflows
- Data Streaming Fault Tolerance
- Flink Checkpointing
- Flink 轻量级异步快照ABS实现原理
以上是关于Flink Checkpoint机制分析的主要内容,如果未能解决你的问题,请参考以下文章