Hbase
Posted 捡黄金的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase相关的知识,希望对你有一定的参考价值。
1、HBase集群安装部署
(1)、解压文件
cd /kkb/soft/
tar -xzvf hbase-1.2.0-cdh5.14.2.tar.gz -C /kkb/install/
(2)、修改HBase配置文件
cd /kkb/install/hbase-1.2.0-cdh5.14.2/conf/
vim hbase-env.sh
添加java地址
export JAVA_HOME=/opt/install/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
(3)、修改 hbase-site.xml
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<!-- 此属性可省略,默认值就是2181 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/kkb/install/zookeeper-3.4.5-cdh5.14.2/zkdatas</value>
</property>
<!-- 此属性可省略,默认值就是/hbase -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>
(4)、egionservers修改
[hadoop@node01 conf]$ vim regionservers
-
指定HBase集群的从节点;原内容清空,添加如下三行
node01 node02 node03
(5)、back-masters
-
创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
-
vim backup-masters
-
将node02作为备份的HMaster节点,问价内容如下
node02
(6)、分发安装包
cd /kkb/install
scp -r hbase-1.2.0-cdh5.14.2/ node02:$PWDscp -r hbase-1.2.0-cdh5.14.2/ node03:$PWD
(7)、建立软连接
-
注意:三台机器均做如下操作
-
因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们==三台机器==都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/core-site.xml /kkb/install/hbase-1.2.0-cdh5.14.2/conf/core-site.xml
ln -s /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/hdfs-site.xml /kkb/install/hbase-1.2.0-cdh5.14.2/conf/hdfs-site.xml
(7)、添加HBase环境变量
-
注意:三台机器均执行以下命令,添加环境变量
vim /etc/profile
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh5.14.2
export PATH=$PATH:$HBASE_HOME/bin重新编译/etc/profile,让环境变量生效
source /etc/profile
(8)、Base的启动与停止
-
需要提前启动HDFS及ZooKeeper集群
-
第一台机器==node01==(HBase主节点)执行以下命令,启动HBase集群
start-hbase.sh
-
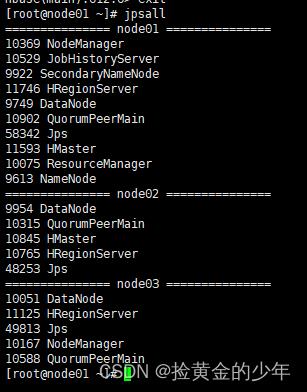
启动完后,jps查看HBase相关进程
node01、node02上有进程HMaster、HRegionServer
node03上有进程HRegionServer
-
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告
查看当前所有节点Jps状态
2、hbase基础学习
2.1、rowkey行键
-
table的主键,table中的记录==按照rowkey 的字典序进行排序==
-
Row key行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes)
2.2 Column Family列族
-
列族或列簇
-
HBase表中的每个列,都归属与某个列族
-
列族是表的schema的一部分(而列不是),即建表时至少指定一个列族
-
比如创建一张表,名为
user,有两个列族,分别是info和data,建表语句create 'user', 'info', 'data'
2.3 Column列
-
列肯定是表的某一列族下的一个列,用
列族名:列名表示,如info列族下的name列,表示为info:name -
属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
2.4 cell单元格
-
指定row key行键、列族、列,可以确定的一个cell单元格
-
cell中的数据是没有类型的,全部是以字节数组进行存储
2.5 Timestamp时间戳
-
可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号version number
-
即一个Cell可以有多个版本的值
Client客户端
-
Client是操作HBase集群的入口
-
对于管理类的操作,如表的增、删、改操纵,Client通过RPC与HMaster通信完成
-
对于表数据的读写操作,Client通过RPC与RegionServer交互,读写数据
-
-
Client类型:
-
HBase shell
-
Java编程接口
-
Thrift、Avro、Rest等等
-
ZooKeeper集群
-
作用
-
实现了HMaster的高可用,多HMaster间进行主备选举
-
保存了HBase的元数据信息meta表,提供了HBase表中region的寻址入口的线索数据
-
对HMaster和HRegionServer实现了监控
-
HMaster
-
HBase集群也是主从架构,HMaster是主的角色,是老大
-
主要负责Table表和Region的相关管理工作:
-
关于Table
-
管理Client对Table的增删改的操作
-
关于Region
-
在Region分裂后,负责新Region分配到指定的HRegionServer上
-
管理HRegionServer间的负载均衡,迁移region分布
-
当HRegionServer宕机后,负责其上的region的迁移
-
-
HRegionServer
-
HBase集群中从的角色,是小弟
-
作用
-
响应客户端的读写数据请求
-
负责管理一系列的Region
-
切分在运行过程中变大的region
-
Region
-
HBase集群中分布式存储的最小单元
-
一个Region对应一个Table表的部分数据
基础命令操作
进入hbase
hbase shell
创建user表,以及info,data列族
create 'user', 'info', 'data'
向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
HBase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
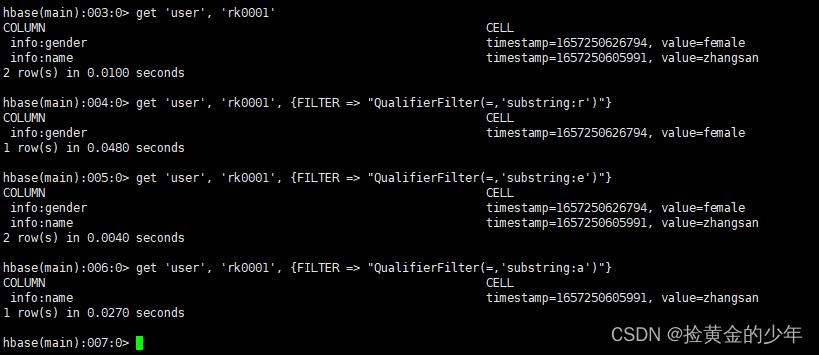
根据rowkey查询该行所有列族的数据
get 'user', 'rk0001'
获取user表中row key为rk0001,info列族的name、age列的信息
get 'user', 'rk0001', 'info:name', 'info:age'
过滤值, 获取user表中row key为rk0001,cell的值为zhangsan的信息
get 'user', 'rk0001', FILTER => "ValueFilter(=, 'binary:zhangsan')"
获取user表中row key为rk0001,列标示符中含有a的信息
get 'user', 'rk0001', FILTER => "QualifierFilter(=,'substring:a')"
查看所有的表
list
查看表中所有数据
scan 'user'
查看user表中,一个列族的所有信息
scan 'user', COLUMNS => 'info'
查询info:name列、data:pic列的数据
scan 'user', COLUMNS => ['info:name', 'data:pic']
将user表的f1列族版本数改为5
alter 'user', NAME => 'info', VERSIONS => 5
删除user表row key为rk0001,列标示符为info:name的数据
delete 'user', 'rk0001', 'info:name'
删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete 'user', 'rk0001', 'info:name', 1392383705316
清空表数据
truncate 'user'
删除表
-
首先需要先让该表为disable状态,使用命令:
disable 'user'
-
然后使用drop命令删除这个表
drop 'user'
(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
查看所有的表
list
统计表中有多少个行键(rowkey)
count 'user'
javaApi操作
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>compile</scope>
</dependency>
</dependencies>1、创建表
@Test
public void createTable() throws IOException
Configuration configuration = HBaseConfiguration.create();
//连接HBase集群不需要指定HBase主节点的ip地址和端口号
configuration.set("hbase.zookeeper.quorum","node01:2181,node02:2181,node03:2181");
//创建连接对象
Connection connection = ConnectionFactory.createConnection(configuration);
//获取连接对象,创建一张表
//获取管理员对象,来对手数据库进行DDL的操作
Admin admin = connection.getAdmin();
//指定我们的表名
TableName myuser = TableName.valueOf("myuser");
HTableDescriptor hTableDescriptor = new HTableDescriptor(myuser);
//指定两个列族
HColumnDescriptor f1 = new HColumnDescriptor("f1");
HColumnDescriptor f2 = new HColumnDescriptor("f2");
hTableDescriptor.addFamily(f1);
hTableDescriptor.addFamily(f2);
admin.createTable(hTableDescriptor);
admin.close();
connection.close();
2、添加数据
private Connection connection;
private final String TABLE_NAME = "myuser";
private Table table;
@Before
public void initTable() throws IOException
System.out.println("1111111111");
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181");
connection = ConnectionFactory.createConnection(configuration);
table = connection.getTable(TableName.valueOf(TABLE_NAME));
@After
public void close() throws IOException
System.out.println("222222");
table.close();
connection.close();
/**
* 向myuser表当中添加数据
*/
@Test
public void addData() throws IOException
//获取表
//Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
Put put = new Put("0001".getBytes());//创建put对象,并指定rowkey值
put.addColumn("f2".getBytes(), "name".getBytes(), "zhangsan".getBytes());
put.addColumn("f2".getBytes(), "age".getBytes(), Bytes.toBytes(18));
put.addColumn("f2".getBytes(), "id".getBytes(), Bytes.toBytes(25));
put.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("地球人"));
System.out.println("000000000000000");
table.put(put);
table.close();
3、批量插入数据
/**
* hbase的批量插入数据
*/
@Test
public void batchInsert() throws IOException
//创建put对象,并指定rowkey
Put put = new Put("0002".getBytes());
//f1
put.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(1));
put.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("曹操"));
put.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(30));
//f2
put.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("沛国谯县"));
put.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("16888888888"));
put.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("helloworld"));
Put put2 = new Put("0003".getBytes());
put2.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(2));
put2.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("刘备"));
put2.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(32));
put2.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put2.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("幽州涿郡涿县"));
put2.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("17888888888"));
put2.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("talk is cheap , show me the code"));
Put put3 = new Put("0004".getBytes());
put3.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(3));
put3.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("孙权"));
put3.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(35));
put3.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put3.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("下邳"));
put3.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("12888888888"));
put3.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("what are you 弄啥嘞!"));
Put put4 = new Put("0005".getBytes());
put4.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(4));
put4.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("诸葛亮"));
put4.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(28));
put4.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put4.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("四川隆中"));
put4.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("14888888888"));
put4.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("出师表你背了嘛"));
Put put5 = new Put("0006".getBytes());
put5.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(5));
put5.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("司马懿"));
put5.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(27));
put5.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put5.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("哪里人有待考究"));
put5.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("15888888888"));
put5.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("跟诸葛亮死掐"));
Put put6 = new Put("0007".getBytes());
put6.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes(5));
put6.addColumn("f1".getBytes(), "name".getBytes(), Bytes.toBytes("xiaobubu—吕布"));
put6.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(28));
put6.addColumn("f2".getBytes(), "sex".getBytes(), Bytes.toBytes("1"));
put6.addColumn("f2".getBytes(), "address".getBytes(), Bytes.toBytes("内蒙人"));
put6.addColumn("f2".getBytes(), "phone".getBytes(), Bytes.toBytes("15788888888"));
put6.addColumn("f2".getBytes(), "say".getBytes(), Bytes.toBytes("貂蝉去哪了"));
List<Put> listPut = new ArrayList<Put>();
listPut.add(put);
listPut.add(put2);
listPut.add(put3);
listPut.add(put4);
listPut.add(put5);
listPut.add(put6);
table.put(listPut);
4、行键rowkey的查询
/**
* 查询rowkey为0003的人
* get -> Result
*/
@Test
public void getData() throws IOException
//Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
//通过get对象,指定rowkey
Get get = new Get(Bytes.toBytes("0007"));
get.addFamily("f1".getBytes());//限制只查询f1列族下面所有列的值
//查询f2 列族 phone 这个字段
get.addColumn("f2".getBytes(), "address".getBytes());
//通过get查询,返回一个result对象,所有的字段的数据都是封装在result里面了
Result result = table.get(get);
List<Cell> cells = result.listCells(); //获取一条数据所有的cell,所有数据值都是在cell里面 的
if (cells != null)
for (Cell cell : cells)
byte[] family_name = CellUtil.cloneFamily(cell);//获取列族名
byte[] column_name = CellUtil.cloneQualifier(cell);//获取列名
byte[] rowkey = CellUtil.cloneRow(cell);//获取rowkey
byte[] cell_value = CellUtil.cloneValue(cell);//获取cell值
//需要判断字段的数据类型,使用对应的转换的方法,才能够获取到值
if ("age".equals(Bytes.toString(column_name)) || "id".equals(Bytes.toString(column_name)))
System.out.println(Bytes.toString(family_name));
System.out.println(Bytes.toString(column_name));
System.out.println(Bytes.toString(rowkey));
System.out.println(Bytes.toInt(cell_value));
else
System.out.println(Bytes.toString(family_name));
System.out.println(Bytes.toString(column_name));
System.out.println(Bytes.toString(rowkey));
System.out.println(Bytes.toString(cell_value));
//table.close();
5、不知道rowkey的具体值,我想查询rowkey范围值是0003 到0006
@Test
public void scanData() throws IOException
//获取table
//Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
Scan scan = new Scan();//没有指定startRow以及stopRow 全表扫描
//只扫描f1列族
scan.addFamily("f1".getBytes());
//扫描 f2列族 phone 这个字段
scan.addColumn("f2".getBytes(), "phone".getBytes());
scan.setStartRow("0003".getBytes());
scan.setStopRow("0007".getBytes());
//通过getScanner查询获取到了表里面所有的数据,是多条数据
ResultScanner scanner = table.getScanner(scan);
//遍历ResultScanner 得到每一条数据,每一条数据都是封装在result对象里面了
for (Result result : scanner)
List<Cell> cells = result.listCells();
for (Cell cell : cells)
byte[] family_name = CellUtil.cloneFamily(cell);
byte[] qualifier_name = CellUtil.cloneQualifier(cell);
byte[] rowkey = CellUtil.cloneRow(cell);
byte[] value = CellUtil.cloneValue(cell);
//判断id和age字段,这两个字段是整形值
if ("age".equals(Bytes.toString(qualifier_name)) || "id".equals(Bytes.toString(qualifier_name)))
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toInt(value));
else
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toString(value));
//table.close();
6、查询所有rowkey比0003小的数据
@Test
public void rowFilter() throws IOException
//Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
Scan scan = new Scan();
//获取我们比较对象
BinaryComparator binaryComparator = new BinaryComparator("0003".getBytes());
/***
* rowFilter需要加上两个参数
* 第一个参数就是我们的比较规则
* 第二个参数就是我们的比较对象
*/
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, binaryComparator);
//为我们的scan对象设置过滤器
scan.setFilter(rowFilter);
SubstringComparator substringComparator = new SubstringComparator("f2");
//通过familyfilter来设置列族的过滤器
// FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
// scan.se(familyFilter);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner)
List<Cell> cells = result.listCells();
for (Cell cell : cells)
byte[] family_name = CellUtil.cloneFamily(cell);
byte[] qualifier_name = CellUtil.cloneQualifier(cell);
byte[] rowkey = CellUtil.cloneRow(cell);
byte[] value = CellUtil.cloneValue(cell);
//判断id和age字段,这两个字段是整形值
if ("age".equals(Bytes.toString(qualifier_name)) || "id".equals(Bytes.toString(qualifier_name)))
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toInt(value));
else
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toString(value));
7、列族过滤器FamilyFilter
-
查询列族名包含f2的所有列族下面的数据
/**
* 通过familyFilter来实现列族的过滤
* 需要过滤,列族名包含f2
* f1 f2 hello world
*/
@Test
public void familyFilter() throws IOException
Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
Scan scan = new Scan();
SubstringComparator substringComparator = new SubstringComparator("f2");
//通过familyfilter来设置列族的过滤器
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
scan.setFilter(familyFilter);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner)
List<Cell> cells = result.listCells();
for (Cell cell : cells)
byte[] family_name = CellUtil.cloneFamily(cell);
byte[] qualifier_name = CellUtil.cloneQualifier(cell);
byte[] rowkey = CellUtil.cloneRow(cell);
byte[] value = CellUtil.cloneValue(cell);
//判断id和age字段,这两个字段是整形值
if ("age".equals(Bytes.toString(qualifier_name)) || "id".equals(Bytes.toString(qualifier_name)))
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toInt(value));
else
System.out.println("数据的rowkey为" + Bytes.toString(rowkey) + "======数据的列族为" + Bytes.toString(family_name) + "======数据的列名为" + Bytes.toString(qualifier_name) + "==========数据的值为" + Bytes.toString(value));
数据的rowkey为0001======数据的列族为f2======数据的列名为address==========数据的值为地球人
数据的rowkey为0001======数据的列族为f2======数据的列名为age==========数据的值为18
数据的rowkey为0001======数据的列族为f2======数据的列名为id==========数据的值为25
数据的rowkey为0001======数据的列族为f2======数据的列名为name==========数据的值为zhangsan
数据的rowkey为0002======数据的列族为f2======数据的列名为address==========数据的值为沛国谯县
数据的rowkey为0002======数据的列族为f2======数据的列名为phone==========数据的值为16888888888
数据的rowkey为0002======数据的列族为f2======数据的列名为say==========数据的值为helloworld
数据的rowkey为0002======数据的列族为f2======数据的列名为sex==========数据的值为1
数据的rowkey为0003======数据的列族为f2======数据的列名为address==========数据的值为幽州涿郡涿县
数据的rowkey为0003======数据的列族为f2======数据的列名为phone==========数据的值为17888888888
数据的rowkey为0003======数据的列族为f2======数据的列名为say==========数据的值为talk is cheap , show me the code
数据的rowkey为0003======数据的列族为f2======数据的列名为sex==========数据的值为1
数据的rowkey为0004======数据的列族为f2======数据的列名为address==========数据的值为下邳
数据的rowkey为0004======数据的列族为f2======数据的列名为phone==========数据的值为12888888888
数据的rowkey为0004======数据的列族为f2======数据的列名为say==========数据的值为what are you 弄啥嘞!
数据的rowkey为0004======数据的列族为f2======数据的列名为sex==========数据的值为1
数据的rowkey为0005======数据的列族为f2======数据的列名为address==========数据的值为四川隆中
数据的rowkey为0005======数据的列族为f2======数据的列名为phone==========数据的值为14888888888
数据的rowkey为0005======数据的列族为f2======数据的列名为say==========数据的值为出师表你背了嘛
数据的rowkey为0005======数据的列族为f2======数据的列名为sex==========数据的值为1
数据的rowkey为0006======数据的列族为f2======数据的列名为address==========数据的值为哪里人有待考究
数据的rowkey为0006======数据的列族为f2======数据的列名为phone==========数据的值为15888888888
数据的rowkey为0006======数据的列族为f2======数据的列名为say==========数据的值为跟诸葛亮死掐
数据的rowkey为0006======数据的列族为f2======数据的列名为sex==========数据的值为1
数据的rowkey为0007======数据的列族为f2======数据的列名为address==========数据的值为内蒙人
数据的rowkey为0007======数据的列族为f2======数据的列名为phone==========数据的值为15788888888
数据的rowkey为0007======数据的列族为f2======数据的列名为say==========数据的值为貂蝉去哪了
数据的rowkey为0007======数据的列族为f2======数据的列名为sex==========数据的值为18、列过滤器QualifierFilter
/**
* 列名过滤器 只查询包含name列的值
*/
@Test
public void qualifierFilter() throws IOException
Scan scan = new Scan();
SubstringComparator substringComparator = new SubstringComparator("name");
//定义列名过滤器,只查询列名包含name的列
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
scan.setFilter(qualifierFilter);
ResultScanner scanner = table.getScanner(scan);
printResult(scanner);
9、列值过滤器ValueFilter
-
查询所有列当中包含8的数据
/**
* 查询哪些字段值 包含数字8
*/
@Test
public void contains8() throws IOException
Scan scan = new Scan();
SubstringComparator substringComparator = new SubstringComparator("8");
//列值过滤器,过滤列值当中包含数字8的所有的列
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
scan.setFilter(valueFilter);
ResultScanner scanner = table.getScanner(scan);
printResult(scanner);
10、专用过滤器使用
1、单列值过滤器 SingleColumnValueFilter
-
SingleColumnValueFilter会返回满足条件的cell。所在行的所有cell的值
-
查询名字为刘备的数据
/**
* select * from myuser where name = '刘备'
* 会返回我们符合条件数据的所有的字段
*
* SingleColumnValueExcludeFilter 列值排除过滤器
* select * from myuser where name != '刘备'
*/
@Test
public void singleColumnValueFilter() throws IOException
//查询 f1 列族 name 列 值为刘备的数据
Scan scan = new Scan();
//单列值过滤器,过滤 f1 列族 name 列 值为刘备的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(), CompareFilter.CompareOp.EQUAL, "刘备".getBytes());
scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = table.getScanner(scan);
printResult(scanner);
11、列值排除过滤器SingleColumnValueExcludeFilter
-
与SingleColumnValueFilter相反
-
如果指定列的值符合filter条件,则会排除掉row中指定的列,其他的列全部返回
-
如果列不存在或不符合filter条件,则不返回row中的列
-
11、rowkey前缀过滤器PrefixFilter
-
查询以00开头的所有前缀的rowkey
/**
* 查询rowkey前缀以 00开头的所有的数据
*/
@Test
public void prefixFilter() throws IOException
Scan scan = new Scan();
//过滤rowkey以 00开头的数据
PrefixFilter prefixFilter = new PrefixFilter("00".getBytes());
scan.setFilter(prefixFilter);
ResultScanner scanner = table.getScanner(scan);
printlReult(scanner);
12、分页过滤器PageFilter
-
通过pageFilter实现分页过滤器
/**
* HBase当中的分页
*/
@Test
public void hbasePageFilter() throws IOException
int pageNum= 3;
int pageSize = 2;
Scan scan = new Scan();
if(pageNum == 1 )
//获取第一页的数据
//scan.setMaxResultSize(pageSize);
scan.setStartRow("".getBytes());
//使用分页过滤器来实现数据的分页
PageFilter filter = new PageFilter(pageSize);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
printResult(scanner);
else
String startRow = "";
//扫描数据的调试 扫描五条数据
int scanDatas = (pageNum - 1) * pageSize + 1;
//scan.setMaxResultSize(scanDatas);//设置一步往前扫描多少条数据
PageFilter filter = new PageFilter(scanDatas);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner)
byte[] row = result.getRow();//获取rowkey
//最后一次startRow的值就是0005
startRow= Bytes.toString(row);//循环遍历我们多有获取到的数据的rowkey
//最后一条数据的rowkey就是我们需要的起始的rowkey
//获取第三页的数据
scan.setStartRow(startRow.getBytes());
//scan.setMaxResultSize(pageSize);//设置我们扫描多少条数据
PageFilter filter1 = new PageFilter(pageSize);
scan.setFilter(filter1);
// scan.setAllowPartialResults(true);
// scan.setBatch(100);
ResultScanner scanner1 = table.getScanner(scan);
printResult(scanner1);
分页过滤器二
@Test
public void hbasePageFilter2() throws IOException
Scan scan = new Scan();
int pageNum = 2;
int pageSize = 2;
String startRow = "000" + (pageNum - 1) * pageSize + 1;
//获取第三页的数据
scan.setStartRow(startRow.getBytes());
//scan.setMaxResultSize(pageSize);//设置我们扫描多少条数据
PageFilter filter1 = new PageFilter(pageSize);
scan.setFilter(filter1);
// scan.setAllowPartialResults(true);
// scan.setBatch(100);
ResultScanner scanner1 = table.getScanner(scan);
printResult(scanner1);
13、多过滤器综合查询FilterList
-
需求:使用SingleColumnValueFilter查询f1列族,name为刘备的数据,并且同时满足rowkey的前缀以00开头的数据(PrefixFilter)
@Test
public void filterList() throws IOException
Scan scan = new Scan();
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("f1".getBytes(), "name".getBytes(), CompareFilter.CompareOp.EQUAL, "刘备".getBytes());
PrefixFilter prefixFilter = new PrefixFilter("00".getBytes());
FilterList filterList = new FilterList();
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(prefixFilter);
scan.setFilter(filterList);
ResultScanner scanner = table.getScanner(scan);
printResult(scanner);
14、根据rowkey删除数据
-
删除rowkey为003的数据
/**
* 删除数据
*/
@Test
public void deleteData() throws IOException
Delete delete = new Delete("0003".getBytes());
table.delete(delete);
15、删除表
/**
* 删除表
*/
@Test
public void deleteTable() throws IOException
//获取管理员对象,用于表的删除
Admin admin = connection.getAdmin();
//删除一张表之前,需要先禁用表
admin.disableTable(TableName.valueOf(TABLE_NAME));
admin.deleteTable(TableName.valueOf(TABLE_NAME));
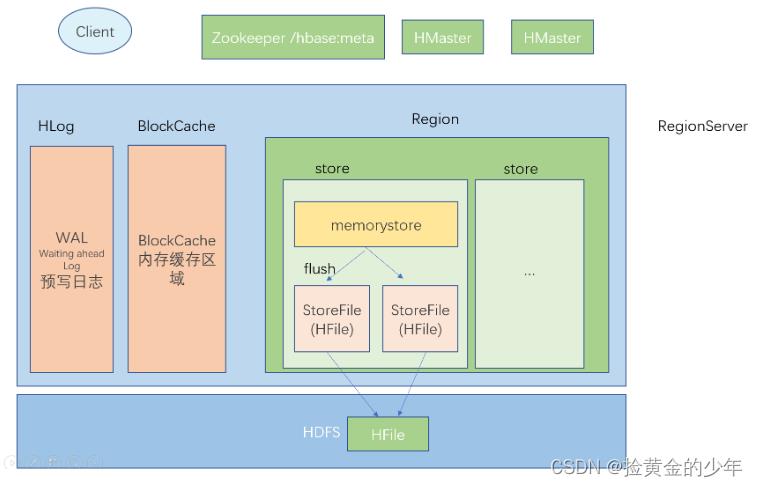
HBase读写流程
-
第一部分: HLog, WAL, 存储写入数据的指令, 而不是数据, HLog存储在hdfs之上
-
第二部分: BlockCache
-
第三部分: Region
-
多个store模块, store模块和列族有关系
-
memoryStore
-
多个StoreFile(HFile)
-
-
-
RegionServer --> n个Region
-
RegionServer -> 1HLog
-
RegionServer -> 1 BlockCache
-
Region -> n个store模块
-
store -> 1memorystroe(128) + n个storeFile
-
Cli连接zk, 获取一张特殊表, hbase/meta表, 获取这张表对应的region, 存储在哪一个regionserver上, 然后将对应的信息缓存在客户端
-
客户端连接对应的regionserver, 读取对应的meta的信息(存储了hbase的元数据信息, 有哪些hbase表, 表对应的region在哪里, 以及每一个region管理的数据范围), hbase/meta表存储的是hbase的元数据信息 scan 'hbase:meta'
存储到blockcache: 为了提高后期查询的效率 (为了提高读的效率)
memorystore: 是为了提高写入的效率, 如果直接把文件写入到磁盘(阻塞) io效率差
-
如果memorystore中的数据超过128M, memorystore中的数据会进入到一个flush队列, 书写到StoreFile
-
刷写完成之后, 删除HLog中的历史数据
1、hbase读取数据流程
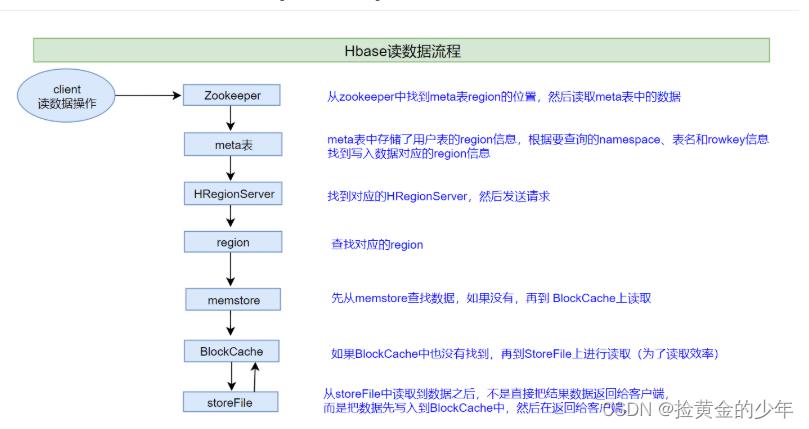
说明:HBase集群,只有一张meta表,此表只有一个region,该region数据保存在一个HRegionServer上
-
1、客户端首先与zk进行连接;
-
从zk找到meta表的region位置,即meta表的数据存储在某一HRegionServer上;
-
客户端与此HRegionServer建立连接,然后读取meta表中的数据;meta表中存储了所有用户表的region信息,我们可以通过
scan 'hbase:meta'来查看meta表信息
-
-
2、根据要查询的namespace、表名和rowkey信息。找到写入数据对应的region信息
-
3、找到这个region对应的regionServer,然后发送请求
-
4、查找并定位到对应的region
-
5、先从memstore查找数据,如果没有,再从BlockCache上读取
-
HBase上Regionserver的内存分为两个部分
-
一部分作为Memstore,主要用来写;
-
另外一部分作为BlockCache,主要用于读数据;
-
-
-
6、如果BlockCache中也没有找到,再到StoreFile上进行读取
-
从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后再返回结果给客户端。
-
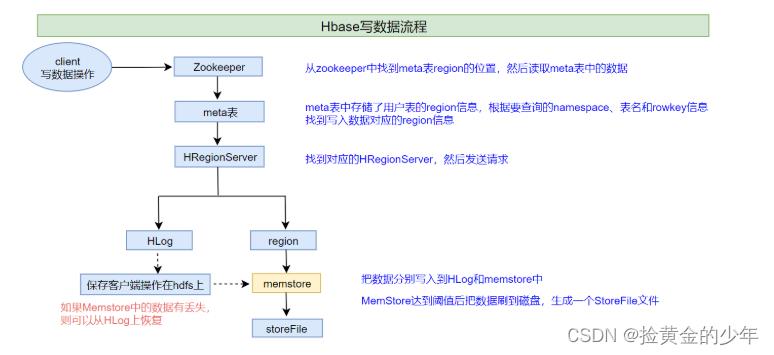
HBase写数据流程
-
1、客户端首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
-
2、根据namespace、表名和rowkey信息。找到写入数据对应的region信息
-
3、找到这个region对应的regionServer,然后发送请求
-
4、把数据分别写到HLog(write ahead log)和memstore各一份
-
5、memstore达到阈值后把数据刷到磁盘,生成storeFile文件
-
6、删除HLog中的历史数据
补充:
HLog(write ahead log):
也称为WAL意为Write ahead log,类似mysql中的binlog,用来做灾难恢复时用,HLog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
MemStore的flush
1、Flush触发条件
1、 memstore级别限制
-
当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
2、region级别限制
-
当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认 2* 128M = 256M),会触发memstore刷新。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>4</value>
</property>
3、Region Server级别限制
-
当一个Region Server中所有Memstore的大小总和超过低水位阈值hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size(前者默认值0.95),RegionServer开始强制flush;
-
先Flush Memstore最大的Region,再执行次大的,依次执行;
-
如写入速度大于flush写出的速度,导致总MemStore大小超过高水位阈值hbase.regionserver.global.memstore.size(默认为JVM内存的40%),此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
4、 HLog数量上限
-
当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
5、定期刷新Memstore
-
默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
6、手动flush
-
用户可以通过shell命令
flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
flush的流程
-
为了减少flush过程对读写的影响,将整个flush过程分为三个阶段:
-
prepare阶段:遍历当前Region中所有的Memstore,将Memstore中当前数据集CellSkipListSet做一个快照snapshot;然后再新建一个CellSkipListSet。后期写入的数据都会写入新的CellSkipListSet中。prepare阶段需要加一把updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
-
flush阶段:遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时。
-
commit阶段:遍历所有Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。
-
Compact合并机制
-
hbase为了==防止小文件过多==,以保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。
-
在hbase中主要存在两种类型的compaction合并
-
==minor compaction 小合并==
-
==major compaction 大合并==
-
minor compaction 小合并
-
在将Store中多个HFile合并为一个HFile
在这个过程中会选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,对于超过了==TTL的数据、更新的数据、删除的数据==仅仅只是做了标记。并没有进行物理删除,一次Minor Compaction的结果是更少并且更大的StoreFile。这种合并的触发频率很高。
-
minor compaction触发条件由以下几个参数共同决定:
<!--默认值3;表示一个store中至少有4个store file时,会触发minor compaction-->
<property>
<name>hbase.hstore.compactionThreshold</name>
<value>3</value>
</property>
<!--默认值10;表示一次minor compaction中最多合并10个store file-->
<property>
<name>hbase.hstore.compaction.max</name>
<value>10</value>
</property>
<!--默认值为128m;表示store file文件大小小于该值时,一定会加入到minor compaction的-->
<property>
<name>hbase.hstore.compaction.min.size</name>
<value>134217728</value>
</property>
<!--默认值为LONG.MAX_VALUE;表示store file文件大小大于该值时,一定会被minor compaction排除-->
<property>
<name>hbase.hstore.compaction.max.size</name>
<value>9223372036854775807</value>
</property>
2 major compaction 大合并
-
合并Store中所有的HFile为一个HFile
将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。一般可以是手动控制进行合并,防止出现在业务高峰期。
-
major compaction触发时间条件
<!--默认值为7天进行一次大合并,--> <property> <name>hbase.hregion.majorcompaction</name> <value>604800000</value> </property> -
手动触发
##使用major_compact命令 major_compact tableName
HBase表的预分区
-
当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。
-
解决这个问题可以用pre-splitting,在创建table的时候就配置好,生成多个region。
为何要预分区?
-
增加数据读写效率
-
负载均衡,防止数据倾斜
-
方便集群容灾调度region
-
优化Map数量
2、预分区原理
-
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
3、手动指定预分区
-
三种方式
第一种
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']
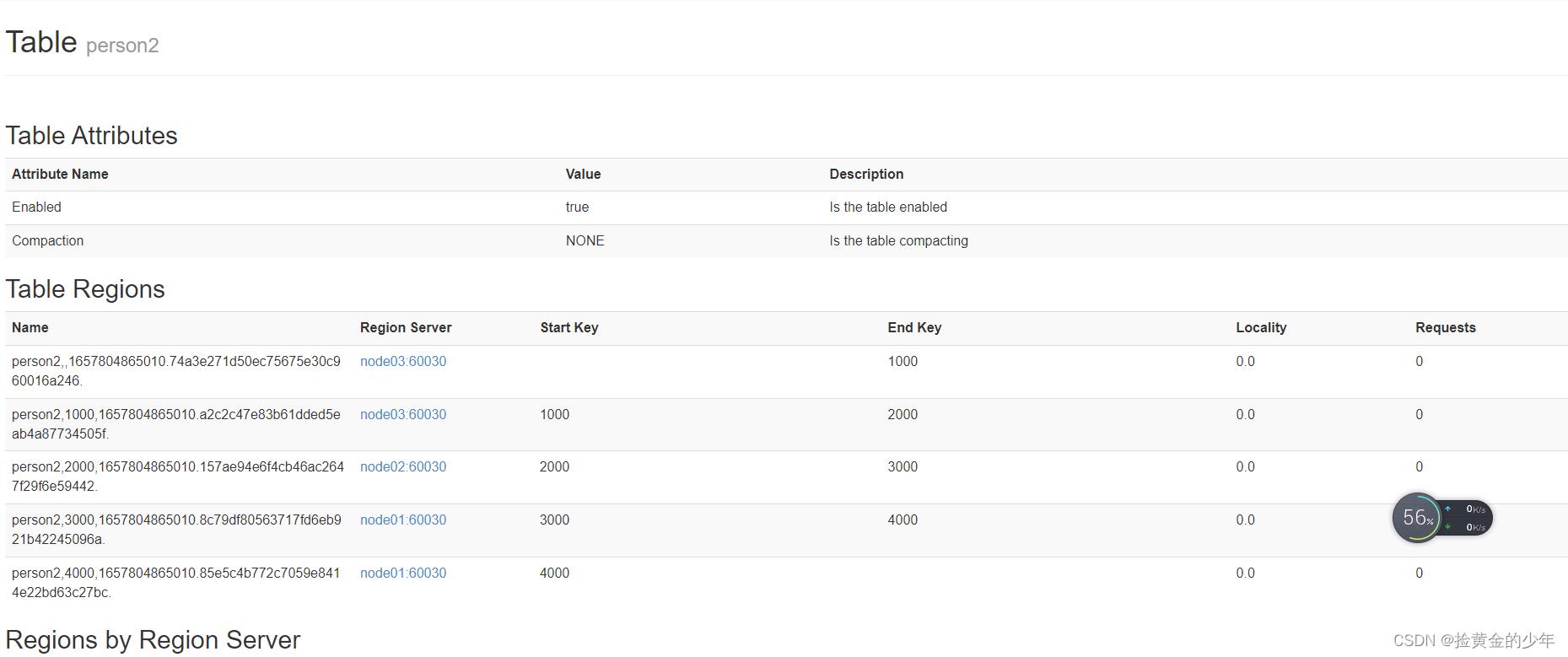
方式二:也可以把分区规则创建于文件中
cd /kkb/install
vim split.txt
aaa
bbb
ccc
ddd
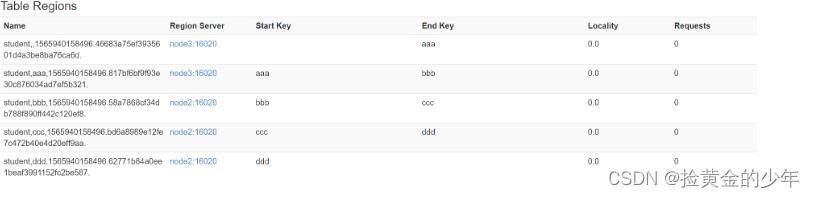
create 'student','info',SPLITS_FILE => '/kkb/install/split.txt'
方式三: HexStringSplit 算法
-
HexStringSplit会将数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为拆分点。
-
例如:
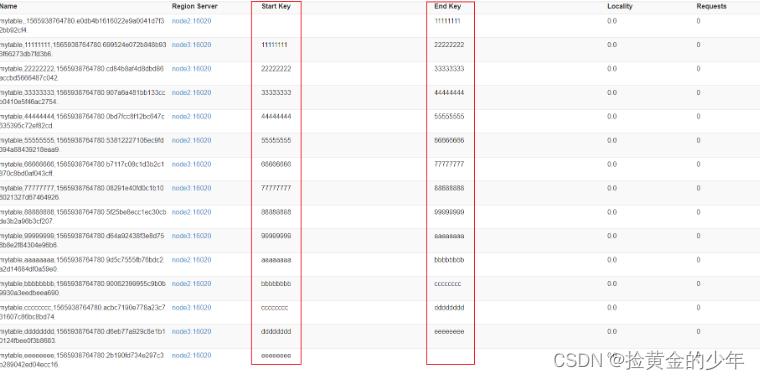
create 'mytable', 'base_info',' extra_info', NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'
region的冷合并和热合并
region合并说明
-
Region的合并不是为了性能, 而是出于便于运维的目的 .
-
比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点
-
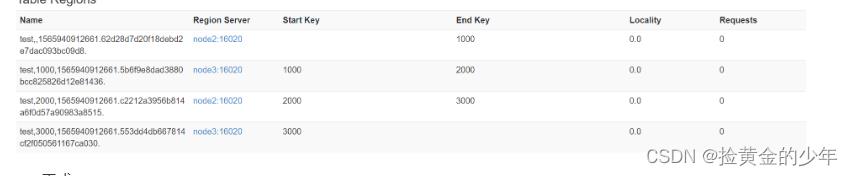
一、冷合并
这里通过org.apache.hadoop.hbase.util.Merge类来实现,不需要进入hbase shell,直接执行(==需要先关闭hbase集群==):
hbase org.apache.hadoop.hbase.util.Merge test test,,1565940912661.62d28d7d20f18debd2e7dac093bc09d8. test,1000,1565940912661.5b6f9e8dad3880bcc825826d12e81436.
2、通过online_merge热合并Region
-
==不需要关闭hbase集群==,在线进行合并
-
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分。
-
需求:需要把test表中的2个region数据进行合并: test,2000,1565940912661.c2212a3956b814a6f0d57a90983a8515. test,3000,1565940912661.553dd4db667814cf2f050561167ca030.
-
需要进入hbase shell:
merge_region 'a34185c9f32b1e3211d6d688664266f9','abf69cdc7335880918a60f3c917093e9'
hbase实战
1、hbase实战一(hbase通过MR将一个表中数据,筛选到宁外一张表中)
-
需求:==读取HBase当中myuser这张表的f1:name、f1:age数据,将数据写入到另外一张myuser2表的f1列族里面去==
-
第一步:创建myuser2这张hbase表
注意:列族的名字要与myuser表的列族名字相同
create 'myuser2','f1'
HBaseReadMapper类,继承TableMapper,拿到每条数据,并对数据进行过滤并封装
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* myuser f1: name&age => myuser2 f1
*/
public class HBaseReadMapper extends TableMapper<Text, Put>
/**
*
* @param key rowkey
* @param value rowkey此行的数据 Result类型
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException
//获得roweky的字节数组
byte[] rowkey_bytes = key.get();
String rowkeyStr = Bytes.toString(rowkey_bytes);
Text text = new Text(rowkeyStr);
//输出数据 -> 写数据 -> Put 构建Put对象
Put put = new Put(rowkey_bytes);
//获取一行中所有的Cell对象
Cell[] cells = value.rawCells();
//将f1 : name& age输出
for(Cell cell: cells)
//当前cell是否是f1
//列族
byte[] family_bytes = CellUtil.cloneFamily(cell);
String familyStr = Bytes.toString(family_bytes);
if("f1".equals(familyStr))
//在判断是否是name | age
byte[] qualifier_bytes = CellUtil.cloneQualifier(cell);
String qualifierStr = Bytes.toString(qualifier_bytes);
if("name".equals(qualifierStr))
put.add(cell);
if("age".equals(qualifierStr))
put.add(cell);
//判断是否为空;不为空,才以上是关于Hbase的主要内容,如果未能解决你的问题,请参考以下文章