NOSQL数据库简介
Posted slvher
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NOSQL数据库简介相关的知识,希望对你有一定的参考价值。
近年来,相信IT从业者对NOSQL这个名词不会陌生,根据WikiPedia的定义,NOSQL是”non SQL”或”Not Only SQL”的简称。其实早在1960年前后,计算机领域就出现过类似的系统,但NOSQL系统真正的爆发点是在WEB2.0出现以后,特别是随着大数据概念的兴起而大放异彩。其被广泛使用的原因与数据特点有着紧密关系。
本文是NOSQL数据库综述方面的学习笔记,参考资料主要来自”Graph Database (2nd Edition)“一书附录”NOSQL Overview”部分。
1. NOSQL基本概念
目前IT行业,尤其是互联网行业数据有几个典型特征:
1)数据量大,单机无法存储;即使能存储于单机关系型数据库,但随着数据量增加,联表join查询的性能会急剧下降
2)数据变化快:a. 数据增速快;b. 流量分布变化快(有明显的峰谷,也可能有突发流量);c. 数据间的耦合结构变化快,传统关系型数据库的强schema模式显得不够灵活
3)数据来源多,原始数据不容易结构化,有强schema约束的关系型数据库不再合适
4)对数据存储的要求有变化,以CAP理论为指导,大多数系统并不要求强一致性,而是对数据存储系统的Availability & Partition tolerance有更高要求
而NOSQL数据库通常满足BASE约束:
1)Basic Availability
系统在外界看来似乎总处于可用状态,这是通过多机水平扩展的集群部署方案实现的,只要多数节点正常就能保证系统基本的可用性,只有落在故障节点的用户请求才会感知到系统不可用。
2)Soft-state
大多数NOSQL系统通过牺牲强一致性来保证可用性和分区容忍性,也即,一个节点写入新数据后,更新不会立即传播至集群其它节点,所以落在其它节点上的读请求可能会读到旧数据。
3)Eventual consistency
NOSQL系统对最终一致性通常是可以保证的。值得一提的是,Neo4j这个图数据库虽然也属NOSQL阵营,但它是可以保证ACID约束的。
从定义来看,与关系型数据库的ACID强约束相比,BASE约束要松散一些,但灵活性有优势,因此,满足前述数据特征的互联网系统越来越依赖NOSQL系统也就不足为奇了。当然,一些对数据有ACID要求的系统还是应该首选关系型数据库。
总之,数据特征决定了我们在实际工程中应该使用何种存储系统。
2. 业界典型的NOSQL系统
根据业界流行的NOSQL系统,可以将NOSQL存储划分为4个象限,如下图所示。
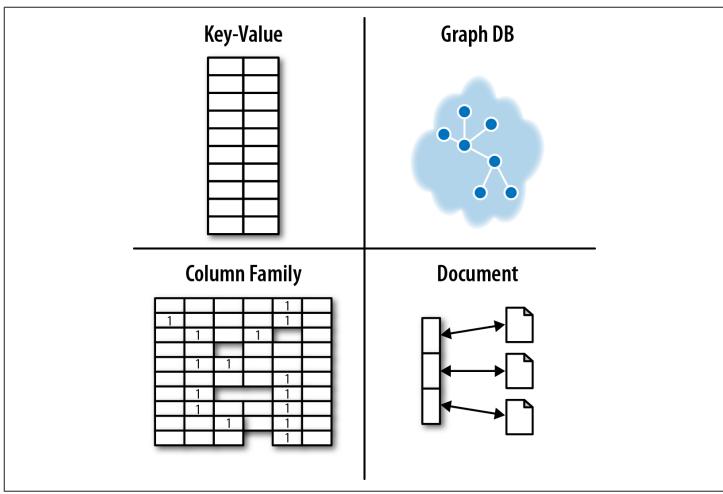
2.1 Key-Value Stores
KV型NOSQL系统起源于Amazon开发的Dynamo系统(Amazon AWS提供的DynamoDB就是这货),可以把它理解为一个分布式的hashmap,支持SEG/GET元操作。
一个完整的分布式KV系统会将KEY按策略尽量均匀地散列在不同的节点上。其中一致性哈希是比较优雅的散列策略,它可以保证当某个节点挂掉时,只有该节点的数据需要重新散列。作为对比,若采用取模哈希策略,则集群有节点不可用时,取模的分母N发生变化,会导致几乎所有的KEY都要重新散列,代价太高。
大多数KV NOSQL通常不会关心存入的value到底是什么,在它看来,那只是一堆字节而已,所以开发者也无法通过value的某些属性来获取整个value。如果开发者有根据value的部分字段查找数据的需求,那应该考虑使用文档型NOSQL系统。
典型的KV型NOSQL系统:Memcached, Redis及DynamoDB
2.2 Document Stores
对于需要跟具有层次文档结构的数据打交道的开发者来说,文档型NOSQL系统提供了最自然的存储模式,它支持读/写一些标准格式的文档数据(典型如XML, YAML和JSON,甚至支持2进制的BSON格式)。
在最简单的应用中,文档数据可以通过其ID进行读写操作,此时,可以将文档型NOSQL系统看作是K-V系统。
但文档型NOSQL系统更普遍的应用场合是根据文档的某个属性字段来获取整个文档。根据属性快速获取包含该属性的所有文档的操作是通过索引来实现的,也即文档数据在写入时,系统会对某些文档属性建立索引,从而支持高效地反查操作。而维护索引是有代价的,因此,文档型NOSQL数据库适用于读多写少的场合。
需要注意的是,对于单个文档的读写,文档型NOSQL系统可以保证原子操作,但批量写入的事物原子性目前还不能由系统保证,需要开发者在应用程序中显式处理。
此外,目前大多数文档型NOSQL系统需要用户来规划数据在集群多个实例间的sharding策略,因此,系统的水平扩展问题需要在选型时重点考虑,例如MongoDB早期版本的auto sharding在运维上就容易坑人,导致其一直被诟病。作为对比,主流的KV NOSQL系统和列式NOSQL系统在底层实现时就支持自动sharding,通常无需开发者花费很大精力来处理。
典型的文档型NOSQL系统:MongoDB和Apache CouchDB
2.3 Column Family Stores
列式NOSQL系统起源于Google的BigTable,其数据模型可以看作是一个每行列数可变的数据表,它可以细分为4种实现模式,如下图所示。

其中,Super Colunm Family模型可以理解为maps of maps,例如可以把一个作者和他的专辑结构化地存成Super Colunm Family模式,如下图所示。

与KV型或文档型的NOSQL系统相比,列式存储系统对数据模型的表达力更强。
典型的列式NOSQL系统:BigTable, Cassandra, HBase
2.4 Graph Databases
上面介绍的KV系统、文档型系统及列式存储系统可被统一称为聚合存储系统(Aggregate Stores),它们的共同点是不适合处理具有耦合关系的数据,即它们不适合用于需要理解数据关联关系的复杂查询,而这正是图数据库的用武之地。
图数据库可以细分为底层存储引擎和处理引擎两部分。有些图数据库实现了native的、为存储和管理图数据做过特别优化的图存储引擎(例如Neo4j),而有些图数据库底层存储是外接系统。至于处理引擎,有些数据库实现了具备index-free adjacency特性的引擎(如Neo4j),而有些图数据库并未做到这一点。
图数据库在查找数据时并不会特别依赖索引(严格地说,只是在定位初始节点时会用到索引),因为对于图来说,节点间的关系可以用有向边表达出来。基于图的查询会利用这种局部临接关系遍历图,而非根据全局索引对图中节点做遍历,因此,对于有关联关系的数据来说,利用图进行查询的性能会很高。
图数据库在组织数据时,常用的数据模型包括:属性图(property graphs)、超图(hypergraphs)和三元组(triples),其中属性图模型是图数据库组织数据时普遍采用的主流模型,Neo4j即是采用属性图模型来表达数据间的关联关系。
上述3种图数据模型间的详细区别涉及较多术语,限于篇幅,本文不赘述,感兴趣的话可以翻阅”Graph Database (2nd Edition)”一书的附录部分。
3. 参考资料
- Wikipedia: NOSQL
- Wikipedia: CAP theorem
- Book: Graph Database (2nd Edition), Appendix A. NOSQL Overview
- Wikipedia: Consistent Hashing
- Neo4j Blog: Demining the “Join Bomb” with Graph Queries, 文中解释了index-free adjacency对图遍历的重要性
以上是关于NOSQL数据库简介的主要内容,如果未能解决你的问题,请参考以下文章