大数据时代的数据管理可以使用哪些软件?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据时代的数据管理可以使用哪些软件?相关的知识,希望对你有一定的参考价值。
数据是平台运营商的重要资产,可能提供API接口允许第三方有限度地使用,但是显然是为了增强自身的业务,与此目的抵触的行为都会受到约束。收集数据主要是通过计算机和网络。凡是经过计算机处理的数据都很容易收集,比如浏览器里的搜索、点击、网上购物、……其他数据(比如气温、海水盐度、地震波)可以通过传感器转化成数字信号输入计算机。
收集到的数据一般要先经过整理,常用的软件:Tableau和Impure是功能比较全面的,Refine和Wrangler是比较纯粹的数据整理工具,Weka用于数据挖掘。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。用于统计分析的R语言有个扩展R + Hadoop,可以在Hadoop集群上运行R代码。更具体的自己搜索吧。
可视化输出的工具很多。建议参考wikipedia的“数据可视化”条目。
Tableau、Impure都有可视化功能。R语言也可以绘图。
还有很多可以用来在网页上实现可视化输出的框架或者控件。
大致基于四种技术:Flash(Flex)或者JS(html5)或者Java或者ASP.NET(Silverlight)
Flash的有Degrafa、BirdEye、Axiis、Open Flash Chart
JS的有Ajax.org、Sencha Ext JS、Filament、jQchart、Flot、Sparklines、gRaphael、TufteGraph、Exhibit、PlotKit、ExplorerCanvas、MilkChart、Google Chart API、Protovis
Java的有Choosel、google-visualization-java、GWT Chronoscope、JFreeChart
ASP.NET的有Telerik Charts、Visifire、Dundas Chart
目前我比较喜欢d3(Data-Driven Documents),图形种类丰富,有交互能力,你可以去d3js.org看看,有很多种图形的demo。 参考技术A 大数据时代的数据管理可以使用哪些软件?根据你的需求,建议你使用敬业签,因为它支持你分类整理记录的数据内容,而且还有日志时间轴的功能,既可以将记录的内容按时间线串联起来,又能保证内容的完整储存。 参考技术B 传统的数据管理,通常要根据业务需要,设计一个基于关系数据库的应用程序。这样的系统可以根据一个或者多个数据的特征以及组合关联进行查询和分析,但是缺点是表结构固定、扩展困难、也不通用、只能局限在特定的专有应用场景。在强关联的数据应用场景下,海量数据条目难以分库分表,查询效率会急剧下降,遇到数十亿数据条目的时候有可能永远也得不到结果。
进化型的数据管理采用分布式的半结构化数据库,(比如使用文档数据库MongoDB,KV数据库Cassendra或者Redis),这样看起来扩展性好很多,但是当面临大规模强关联数据进行关联分析和查询的时候异常困难。
但是如果文件系统包含了数十亿的文件和数亿的目录,想要快速发现数据,还需要对于数据特征的标准特征(例如名字、路径、大小、访问时间等)或者应用定义的特征标签关联组合,有效管理数据。
极道的数据管理系统Metaview通过高级的图引擎来解决这个问题。Metaview把数据和数据特征都作为点,所有的特征和数据的关联,以及数据和数据的关联作为边构成了一个庞大的复杂图。这个图里面有数十亿个点,也有数十亿条边,通过把这个图切分成多个小局部图,分布式的存储在多个计算资源上,在局部图和局部图的关联之处做特殊处理,利用高级算法进行并行分析,可以实现大规模、强关联数据特征的实时分析。
存储系统原生的数据感知系统MetaHunter既不需要进行存储系统扫描,也不需要网关,系统能够自动将所有的数据特征和变化动作捕捉到Metaview的后端图引擎中进行索引。但这需要数据管理系统和存储系统紧密配合,因为数据管理的特征感知系统Metahunter的一部分逻辑是在存储系统中实现的。
数据管理系统Metaview, 1秒内能够从10亿个文件、1亿个目录的文件系统中,根据任意标签、名字等复杂组合条件快速发现任意指定数据,全量数据统计20秒完成,复杂全量数据分析5分钟内完成。
极道数据管理系统MetaView结合计算数据流系统Achelous、分布式存储系统ANNA/ALAMO组成的“三驾马车”彼此相互配合协同,能够有效将企业级用户应用产生的海量数据转化为数据资产。 参考技术C 大数据是互联网发展的方向,大数据人才是未来的高薪贵族。随着大数据人才的供不应求,大数据人才的薪资待遇也在不断提升。大数据时代,中国IT环境也将面临重新洗牌,不仅仅是企业,更是程序员们转型可遇而不可求的机遇。综合以下是10家专门从事大数据构建或相关业务的企业所提供的应用程序,有需要的可以直接收藏了!
1. Domo
Omniture公司前首席执行官Josh James于2010年创立了Domo公司,为企业提供了一种方法,可以从不同来源、不同的孤岛中查看数据。它自动从电子表格、社交媒体、内部存储、数据库,基于云的应用程序,以及数据仓库中提取数据,并在可定制仪表板上显示信息。它以其易用性以及几乎任何人都可以建立和使用它而闻名,而不仅仅是数据科学家采用。它配备了许多预加载的图表和数据源设计,可以快速移动。
2. Teradata Database
从Teradata Database 15开始,该公司增加了Teradata统一数据架构等新的大数据功能,使企业能够跨多个系统访问和处理分析查询,其中包括从Hadoop导入和导出双向数据。它还添加了地理空间数据的3D显示和处理,以及增强的工作负载管理和系统可用性。支持AWS和Azure的基于云计算的版本称为Teradata Everywhere,它在基于公共云的数据和本地部署的数据之间提供了大规模的并行处理分析。
3. Hitachi Vantara
Hitachi Vantara的大数据产品是建立一些流行的开源工具基础上。Hitachi Vantara成立于2017年,是日立数据系统公司的存储和数据中心基础设施业务部门,是由Hitachi Insight集团物联网业务和日立Pentaho大数据业务组合成的一家合资公司。 Pentaho基于Apache Spark内存计算框架和Apache Kafka消息系统。Pentaho 8.0还增加了对Apache Knox Gateway的支持,以对用户进行身份验证,并强制访问大数据存储库的访问规则。它还增加了对依靠Docker容器构建分析应用程序的支持。
4. TIBCO公司的Statistica
TIBCO公司的Statistica是针对各种规模企业的预测分析软件,使用Hadoop技术对结构化和非结构化数据执行数据挖掘,解决物联网数据,能够在全球任何地方的设备和网关上部署分析,并支持数据库内分析来自Apache Hive、mysql、Oracle、Teradata等平台的功能。它使用模板来设计完整的分析,因此只有较少的技术用户可以进行自己的分析,并且可以将模型从电脑导出到其他设备。
5. Panoply
Panoply公司依靠使用人工智能来销售所谓的智能云数据仓库,以消除转换、集成和管理数据所需的开发和编码。该公司声称,其智能云数据仓库实质上提供了数据管理即服务,能够在无需任何干预的情况下消费和处理高达1PB的数据。其机器学习算法可以检查来自任何数据源的数据,并对该数据执行查询和可视化。
6. IBM Watson Analytics
Watson Analytics是IBM公司的基于云计算的分析服务。当用户将数据上传到Watson时,它会根据数据分析向用户提供可帮助回答的问题,并立即提供关键数据可视化。它还可以进行简单分析、预测分析、智能数据发现,并提供各种自助服务仪表板。IBM公司还有另一种分析产品SPSS,可用于从数据中发现模式,并查找数据点之间的关联。
7. SAS Visual Analytics
Statistical Analysis System (SAS)创建于1976年,比大数据的创建还要早,就是为了处理大量数据。它可以从各种来源中挖掘、更改、管理和检索数据,并对所述数据执行统计分析,然后将其呈现在一系列方法中,如统计数据、图表等,或将数据写入其他文件。它支持所有类型的数据预测和分析要点,并附带预测工具来分析和预测流程。
8. Sisense商业智能软件
Sisense公司声称其提供了唯一的商业智能软件,使用户可以依靠从商品服务器硬件上的多个源进行来准备、分析和可视化复杂数据。Sisense的片上高性能数据引擎可以在一秒钟内完成对TB级数据的查询,并且为不同行业提供了一批模板。
9. Talend的大数据工作室
Talend一直专注于为Hadoop生成干净的原生代码,无需手动编写所有代码。它为各种大数据存储库提供接口,如Cloudera,MapR,Hortonworks和Amazon EMR。它近期添加了一个数据准备应用程序,可以让客户创建一个通用字典,并使用机器学习,自动执行数据清理过程,以便在更短的时间内为数据处理准备好数据。
10. Cloudera
Apache Hadoop公司是很受欢迎的提供商和支持者,它与戴尔、英特尔、甲骨文、SAS、德勤和凯捷等公司都有合作关系。它由五个主要应用程序组成:核心数据管理平台Cloudera Essentials,数据管理平台Cloudera Enterprise Data Hub,用于商业智能和基于SQL的分析的Cloudera Analytic DB; 高度可扩展的NoSQL数据库Cloudera Operational DB,以及Cloudera Data Science and Engineering,在Core Essentials平台上运行的数据处理、数据科学和机器学习。 参考技术D 有很多呀,应用商店你可以找
大数据时代必修技能 阿里HBase又放出了哪些大招?
前言
HBaseCon是Apache HBase官方举办的技术会议,主要目的是分享,交流HBase这个开源分布式大数据存储的使用和开发以及发展。HBaseCon发起于2012年。通常HBaseCon的举办地是在美国,这是HBaseCon第一次在亚洲举行,命名为Apache HBaseCon 2017Asia。而且这次会议举办地选择在中国深圳,也足以见得HBase在中国的火爆程度和中国开发者们对HBase社区所做的卓越贡献。
Apache HBase是基于Apache Hadoop构建的一个分布式、可伸缩的Key-Value数据库,它提供了大数据背景下的高性能的随机读写能力。做为最早研究、使用和二次开发HBase技术的中国公司,阿里巴巴从2010年就开始使用HBase,经过近7年的发展,现在采用HBase存储的业务已经超过1000+,拥有了上万台的HBase集群规模,在HBase上存储的数据已达PB级。
秉承开源和分享的精神,阿里把HBase的实践经验和改进不断回馈HBase社区,比如说Bucket Cache和Reverse Scan等功能,给HBase技术发展带来了非常深远的影响。同时,也给HBase社区培养了2名PMC和2名Committer,阿里在HBase社区的影响力可见一斑。那么这次HBaseCon 2017 Asia。阿里派出了一位HBase PMC和2位Committer,还有两位资深的HBase开发,给大家带来了十足的干货。
阿里干货系列
一、强同步复制
传统的HBase主备集群同步使用的方案是异步复制,这使得主备集群数据之间会有短暂的数据不同步现象。用户为了灾备,不得不放弃强一致模型。没法放弃强一致语义的用户,必须自己写一套复杂的逻辑来保证主备集群之间数据的读写一致性。阿里的HBase技术专家天引,在此次的HBaseCon Asia上给大家带来了强同步复制方案。

据天引介绍,强同步复制方案采用了主备并发写和RemoteLog技术,使得在同城网络条件下同步复制相对于异步复制仅有2%的吞吐量下降。当一个请求到达主库后,并发写本地和备库,到达备库的同步写不需要走完整的写入路径,而是直接写入RemoteLog,降低同步写开销与延时。除了同步链路外,还有一套异步链路将数据从主库复制到备库,因此正常情况下不需要回放RemoteLog的数据到备库,在主库不可服务的情况下,只需要回放RemoteLog中那些还没有被异步复制链路同步到备库的数据,异步复制只有几秒钟的数据延迟,这保证了可以在很短的时间内完成从主库到备库的切换。
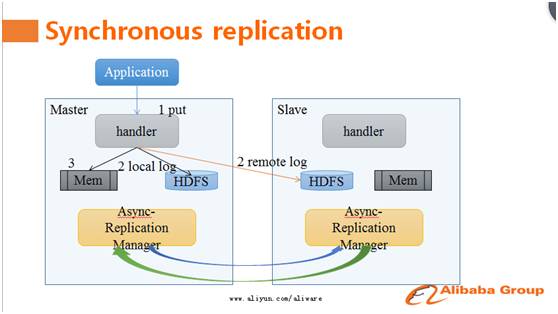
此方案在大会现场引起了强烈反响,很多HBase用户表示这是他们期待已久的功能,希望能尽快使用上。天引表示此功能目前基于阿里内部分支实现、运行及完善,未来将会回馈给社区。
二、SQL on HBase
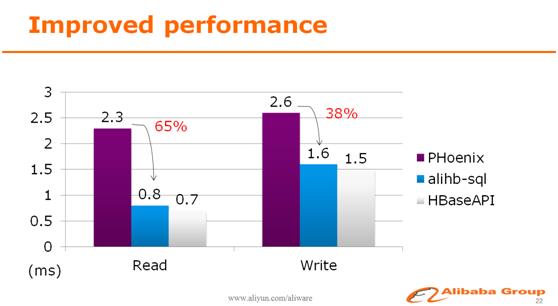
阿里HBase服务了大量的内部用户,并持续有新用户接入。但是使用HBase的用户有很大一部分是从传统的SQL数据库转过来的,HBase的rowkey设计和API的使用习惯对于他们来说并不友好。为了降低这些转型用户的使用门槛,阿里在HBase上引入了SQL层。来自阿里的资深HBase开发工程师天穆,给大家详细讲解了如何玩转SQL on HBase。

通过优化,现在在阿里使用SQL访问HBase和原生API的速度已经相差无几,而且在SQL语法上,创造性地支持HBase多版本和时间戳等NoSQL才具有的功能。
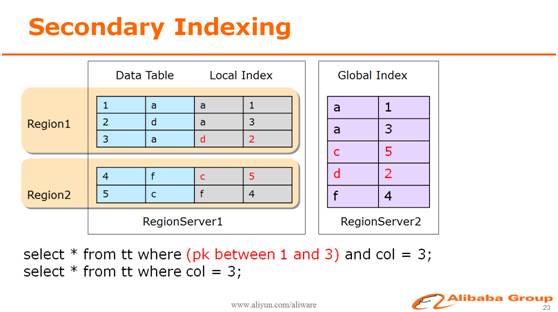
另外,在HBase上同时支持了全局二级索引和本地二级索引。使用户可以在多列上建立索引,简化了业务的设计,提升了请求效率,降低了使用成本。
三、跨集群分区拷贝
HBase上通常承载着海量的数据,而在日常生产过程中,随着业务的发展和公司数据中心的规划等原因,这些海量数据需要经常搬迁,这通常对于运维来说是一个非常头疼的问题。来自阿里的HBase社区Committer正研,分享了阿里跨集群分区拷贝的场景和成熟解决方案。

正研首先介绍了在阿里内部常见的需要数据拷贝的场景,比如说新建数据中心,HBase集群需要整体搬迁到新的机房;又比如说不同机房内的HBase集群的增量数据同步,可以用replication来解决,但是对于存量数据,目前还没有比较高效的方案;另外还一个常见场景就是数据恢复,而传统的HBase备份还原工具都没法控制数据恢复的范围。
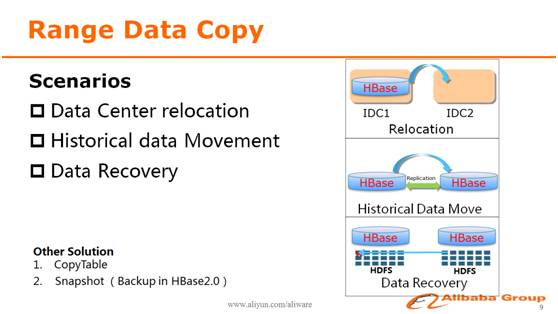
因此,阿里研发了Range Data Copy功能内置在HBase中,提供了一个简单高效,而且能够自动处理各种错误情况和灾难恢复的数据拷贝功能,使用这个功能拷贝一张200TB的表到另外一个集群,所需时间不到5小时。
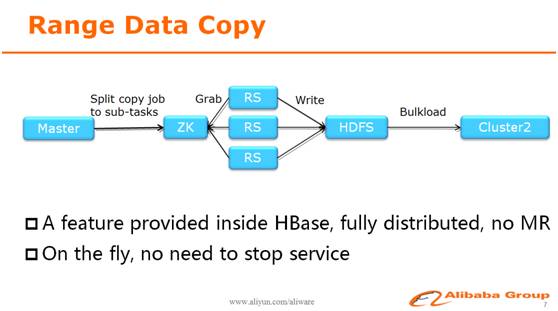
四、读写链路优化
在阿里使用HBase的过程中,对HBase本身做了非常多的读写性能优化。来自阿里的HBase社区PMC绝顶和Committer天照,一起给大家分享了阿里在这方面所取得的一些成果。

1、使用Netty替代HBase原生的RPC server,大大提升了HBaseRPC的吞吐能力,降低了延迟 ;
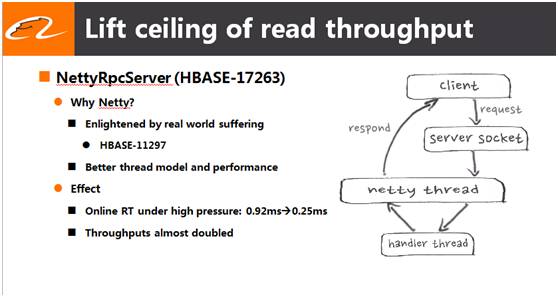
2、 引入新的HFileBlock编码格式,把顺序搜索变成了二分查找,提高了HBase随机读的能力

3、拆分写链路,释放阻塞的handler资源,提高了HBase写的吞吐能力 ;

来自阿里的这些优化黑科技,使HBase的能力又更上一个新台阶。并且这些优化和功能目前已经回馈给了社区,所有的HBase用户都能在新版本的使用获得这些技术红利。
总结
除了阿里带来的技术分享,现场许多其他公司也都带来了他们对HBase做出的改进和使用经验。比如说小米实现了AsyncClient,填补了HBase没有原生异步API的缺口;知乎使用kubernetes自动扩容缩容HBase集群,灵活地适应业务高速发展和瞬息万变;烽火网络隔离读写资源使近线查询更加稳定等等。
除了上述提到的这几个亮点技术分享,此次HBaseCon大会的每一个session都非常精彩,给大家带来了一场又一场思维碰撞的盛宴。Apache HBase“掌门人”Michael Stack也参加了此次会议,并与HBase开发者们举行了一次圆桌会议,共同探讨HBase的现状和未来。

这次HBaseCon的火爆程度,直接展示了国内企业和开发者们对HBase热情和期望。HBaseCon大会不仅给HBase的使用者们带来了最新鲜的技术进展,互通有无,吸收其他公司的先进经验;也成为HBase使用者和开发者之间沟通的桥梁,能让开发者们看到业界动态,用户的需求,共同把HBase打造成一个更加易用,更高性能,更稳定的大数据存储。这次HBaseCon大会是一个很好的开端,期望HBaseCon Asia越办越好,给大家带来更多的干货!

写在最后
如果你对大数据在线存储、对HBase感兴趣,或者是想更好地使用HBase、开发更NB的产品,欢迎联系我(正研,zhengyan.ywl@alibaba-inc.com),一起交流,互相学习!
作者简介
杨文龙,花名正研,阿里巴巴存储技术事业部资深研发,HBase开源社区Committer。开源技术爱好者,对分布式存储系统的设计、实践具备丰富的大规模生产的经验。
你可能还喜欢
关注「阿里技术」
把握前沿技术脉搏
转载 l 合作 l 投稿
lunalin.lpp@alibaba-inc.com
以上是关于大数据时代的数据管理可以使用哪些软件?的主要内容,如果未能解决你的问题,请参考以下文章