MMPose理解
Posted Arrow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MMPose理解相关的知识,希望对你有一定的参考价值。
MMPose理解
1. MMPose是什么
- MMPose 是一款基于 Pytorch 的姿态估计开源工具箱,是 OpenMMLab 项目的成员之一,包含了丰富的 2D 多人姿态估计、2D 手部姿态估计、2D 人脸关键点检测、133关键点全身人体姿态估计、动物关键点检测、服饰关键点检测等算法以及相关的组件和模块。
- MMPose 由 8 个主要部分组成,apis、structures、datasets、codecs、models、engine、evaluation 和 visualization。
- apis 提供用于模型推理的高级 API
- structures 提供 bbox、keypoint 和 PoseDataSample 等数据结构
- datasets 支持用于姿态估计的各种数据集
- transforms 包含各种数据增强变换
- codecs 提供姿态编解码器:编码器用于将姿态信息(通常为关键点坐标)编码为模型学习目标(如热力图),解码器则用于将模型输出解码为姿态估计结果
- models 以模块化结构提供了姿态估计模型的各类组件
- pose_estimators 定义了所有姿态估计模型类
- data_preprocessors 用于预处理模型的输入数据
- backbones 包含各种骨干网络
- necks 包含各种模型颈部组件
- heads 包含各种模型头部
- losses 包含各种损失函数
- engine 包含与姿态估计任务相关的运行时组件
- hooks 提供运行时的各种钩子
- evaluation 提供各种评估模型性能的指标
- visualization 用于可视化关键点骨架和热力图等信息
2. 编解码器
- 在关键点检测任务中,根据算法的不同,需要利用标注信息,生成不同格式的训练目标,比如归一化的坐标值、一维向量、高斯热图等。同样的,对于模型输出的结果,也需要经过处理转换成标注信息格式。我们一般将标注信息到训练目标的处理过程称为编码,模型输出到标注信息的处理过程称为解码。
- 编码和解码是一对紧密相关的互逆处理过程。在 MMPose 早期版本中,编码和解码过程往往分散在不同模块里,使其不够直观和统一,增加了学习和维护成本。
- MMPose 1.0 中引入了新模块编解码器(Codec) ,将关键点数据的编码和解码过程进行集成,以增加代码的友好度和复用性。
- 编解码器在工作流程中所处的位置如下所示:
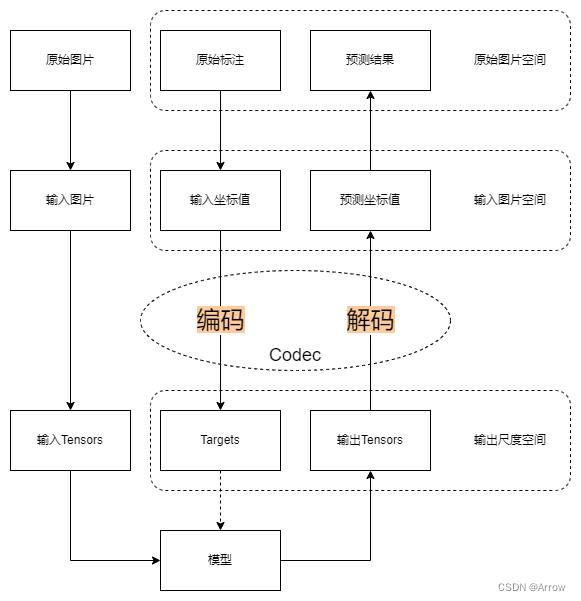
- 一个编解码器主要包含两个部分:
- 编码器
- 解码器
2.1 编码器
- 编码器主要负责将处于输入图片尺度的坐标值,编码为模型训练所需要的目标格式,主要包括:
- 归一化的坐标值:用于 Regression-based 方法
- 一维向量:用于 SimCC-based 方法
- 高斯热图:用于 Heatmap-based 方法
- 以 Regression-based 方法的编码器为例:
@abstractmethod
def encode(
self,
keypoints: np.ndarray,
keypoints_visible: Optional[np.ndarray] = None
) -> Tuple[np.ndarray, np.ndarray]:
"""Encoding keypoints from input image space to normalized space.
Args:
keypoints (np.ndarray): Keypoint coordinates in shape (N, K, D)
keypoints_visible (np.ndarray): Keypoint visibilities in shape
(N, K)
Returns:
tuple:
- reg_labels (np.ndarray): The normalized regression labels in
shape (N, K, D) where D is 2 for 2d coordinates
- keypoint_weights (np.ndarray): The target weights in shape
(N, K)
"""
if keypoints_visible is None:
keypoints_visible = np.ones(keypoints.shape[:2], dtype=np.float32)
w, h = self.input_size
valid = ((keypoints >= 0) &
(keypoints <= [w - 1, h - 1])).all(axis=-1) & (
keypoints_visible > 0.5)
reg_labels = (keypoints / np.array([w, h])).astype(np.float32)
keypoint_weights = np.where(valid, 1., 0.).astype(np.float32)
return reg_labels, keypoint_weights
- 参数说明:
- N:instance number
- K:keypoint number
- D:keypoint dimension
- L:embedding tag dimension
- [w, h]:image size
- [W, H]:heatmap size
- sigma:The sigma value of the Gaussian heatmap
2.1.1 Heatmap-based
- Heatmap-based方法为每个关节生成似然热图(likelihood heatmap),并使用argmax 或 soft-argmax 操作把关节定位到一个点。
- 2D heatmap生成为一个二维高斯分布,其中心为标注的关节位置,通过为每个位置分配概率值来抑制false positive并平滑训练过程。
- heatmap的不足:
- 计算量大
- 存储量大
- 扩展到3D或4D(空间+时间)成本高
- 难以把heatmap布署到one-state方法中
- 低分辨率输入的性能受到限制
- 为了提高特征图分辨率以获得更高的定位精度,需要多个计算量大的上采样层
- 为减少量化误差,需采用额外的后处理
2.1.2 RLE ( Regression-based)
- RLE:Residual Log-likelihood Estimation (残差对数似然估计)
- DLE:Direct Likelihood Estimation
- RLE是一种regression-based的方法。 具体来说,RLE 学习分布的变化而不是未参考的基础分布,以促进训练过程。
- RLE的优势:其性能和计算量均优于heatmap-based方法

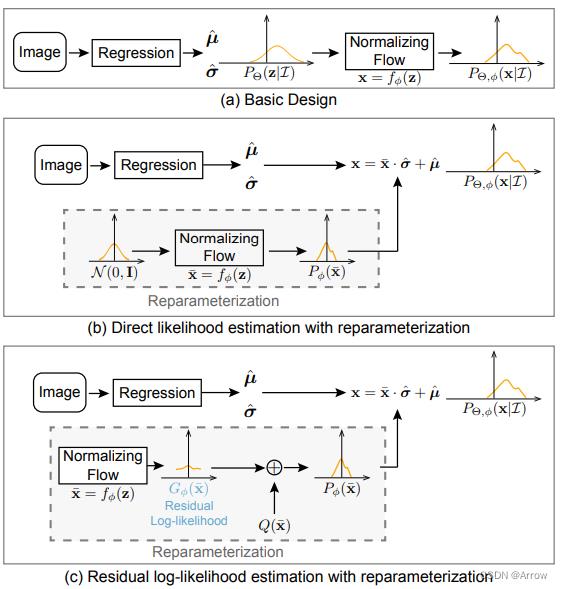
- 标准Regression-based方法直接将输入映射到输出关节坐标,这对于各种人体姿态估计任务和实时应用来说是灵活高效的,尤其是在边缘设备上。一个标准的热图头(3 个反卷积层)的成本是 ResNet-50 主干的 1.4 倍 FLOP,而回归头仅花费相同主干的 1/20000 FLOP。
- 标准Regression-based的不足:
- 回归的性能较差
- 在遮挡、运动模糊和截断等具有挑战性的情况下,真实标签本质上是模棱两可的。通过利用似然热图,基于热图的方法对这些歧义具有鲁棒性。 但是RLE之前的回归方法容易受到这些嘈杂标签的影响。


2.1.3 SimCC (SimCC-based )
- SimCC:Simple Coordinate Classification
- 思路:SimCC将 HPE(Human Poes Estimation) 重新定义为水平和垂直坐标的两个分类任务。将每个像素均匀地划分为多个 bin,从而实现亚像素定位精度和低量化误差。
- 方法比较


2.2 解码器
- 解码器主要负责将模型的输出解码为输入图片尺度的坐标值,处理过程与编码器相反。
- 以 Regression-based 方法的解码器为例:
def decode(self, encoded: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""Decode keypoint coordinates from normalized space to input image
space.
Args:
encoded (np.ndarray): Coordinates in shape (N, K, D)
Returns:
tuple:
- keypoints (np.ndarray): Decoded coordinates in shape (N, K, D)
- scores (np.ndarray): The keypoint scores in shape (N, K).
It usually represents the confidence of the keypoint prediction
"""
if encoded.shape[-1] == 2:
N, K, _ = encoded.shape
normalized_coords = encoded.copy()
scores = np.ones((N, K), dtype=np.float32)
elif encoded.shape[-1] == 4:
# split coords and sigma if outputs contain output_sigma
normalized_coords = encoded[..., :2].copy()
output_sigma = encoded[..., 2:4].copy()
scores = (1 - output_sigma).mean(axis=-1)
else:
raise ValueError(
'Keypoint dimension should be 2 or 4 (with sigma), '
f'but got encoded.shape[-1]')
w, h = self.input_size
keypoints = normalized_coords * np.array([w, h])
return keypoints, scores
- 默认情况下,decode() 方法只提供单个目标数据的解码过程,你也可以通过 batch_decode() 来实现批量解码提升执行效率。
2.3 常见用法
- 在 MMPose 配置文件中,主要有三处涉及编解码器:
- 定义编解码器
- 生成训练目标
- 模型头部
2.3.1 定义编解码器
- 以回归方法生成归一化的坐标值为例,在配置文件中,我们通过如下方式定义编解码器:
codec = dict(type='RegressionLabel', input_size=(192, 256))
2.3.2 生成训练目标
- 在数据处理阶段生成训练目标时,需要传入编解码器用于编码:
dict(type='GenerateTarget', target_type='keypoint_label', encoder=codec)
2.3.3 模型头部
- 在 MMPose 中,我们在模型头部对模型的输出进行解码,需要传入编解码器用于解码:
head=dict(
type='RLEHead',
in_channels=2048,
num_joints=17,
loss=dict(type='RLELoss', use_target_weight=True),
decoder=codec
)
以上是关于MMPose理解的主要内容,如果未能解决你的问题,请参考以下文章