redis详解(内部分享版)
Posted 5ycode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis详解(内部分享版)相关的知识,希望对你有一定的参考价值。
文章目录
基础概念
-
为什么要区分内核空间和用户空间?
-
早期是不区分内核和用户的,带来的问题是程序可以访问任意内存空间,如果程序不稳定,容易把系统搞崩溃。
-
后来按cpu指令的重要程度对指令进行了分级,一共4个级别:Ring0~Ring3,linux只使用了Ring0和Ring3两个级别;
-
用户态使用Ring3级别运行,只访问用户空间,Ring0运行在内核态,可以访问任何程序空间
-
-
内核空间
- linux系统内核运行的空间
- 主要提供进程调度、内存分配、连接硬件资源等
-
用户空间
- 提供给应用程序的空间
- 不具备访问内核空间资源的权限
- 需要通过内核空间才能访问到内核资源
- 使用内核资源,cpu需要从用户态切换到内核态,再从内核态到用户态,cpu最少需要切换两次
-
fd(file descriptors文件描述符)
-
指向内核为对应进程维护打开文件记录表的索引值,进程唯一,也可以理解为文件指针
-
file table
- 由系统内核维护的全局唯一的表(一个系统内只有一个)
- 记录所有进程打开文件的状态、偏移量、访问模式、文件位置,该文件对应的inode对象引用
-
inode table
- 全局唯一的表,是硬盘存储的文件的元数据的集合
- 文件类型、文件大小、文件类型、文件锁
-
一切皆文件(进程、设备、通道等)
-
抽象了一组标准接口,每个进程有3个标准文件
- 0 标准输入
- 1 标准输出
- 2 标准错误
- nohup command 2>&1 &
-
fd可以重复利用

-
-
socket的概念
- 特殊的文件(一切皆文件)
- 套接字允许链接到网络,套接字与邮筒和墙壁上的电话插座是类似的
- 必须有一个地址和端口与其绑定
- 双端都建立链接后,两台计算机可以建立一个链接
-
bind()
- redis在启动的时候,通过listenToPort 将配置的ipv4和ipv6以及端口绑定到对应的fd上(可以理解产生一个对外提供服务的fd);
-
listen()
- Redis 通过acceptTcpHandler来监听bind阶段产生的fd到达的tcp请求;
- 一次循环1000次(MAX_ACCEPTS_PER_CALL),每次通过anetTcpAccept中的accept获取达到的tcp请求的fd;
- 将产生的fd绑定到新创建的redisClient上(通过acceptCommonHandler中的createClient创建)
- 这里也会对redis的链接数增加对应的client的个数
-
fork()
- 只是复制主进程的虚拟表空间,仍与父进程共享同样的物理空间;
- 当父子进程某一方放生写操作时,系统才会为其分配物理空间,并复制一份副本以供其修改;
- fork函数的奇妙指出就是仅调用一次,却能够返回两次
- 返回0 表示子进程执行
- 返回1 表示父进程执行
socket示意图:

tcp链接流程

-
io多路复用
- I/O多路复用是一种同步I/O模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知线程进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序。多路是指网络连接,复用指的是同一个线程。
- I/O多路复用模型是建立在内核提供的多路分离函数select/epoll等基础之上的,使用select/epoll函数可以避免同步非阻塞IO模型中轮询等待的问题
- IO多路复用有两个模型
- 一个模型是早期的select和poll,通过集合set去线性循环所有的事件
- 一个是后期的epoll模型,通过注册事件以及事件回调机制处理
redis中的事件驱动模型
/**
* @brief ae的几种实现
* redis按照性能从上到下排序
*
* evport: 支持Solaris
* epoll: 支持linux
* kqueue: 支持FreeBSD 系统 如macos
* select: 都不包含就是select
*/
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
redis 对于事件模型的封装
/**
* @brief
* 根据不同的操作系统会有不同的实现
* 对于select来说应该是就是初始化fdset,用于select的相关调用;
* 对于epoll来说,需要创建epoll的fd以及epoll使用的events数组
* @param eventLoop
* @return int
*/
static int aeApiCreate(aeEventLoop *eventLoop)
/**
* @brief 注册事件到 到操作系统,每个操作系统针对读写的事件类型不同
* 对于evport来说,往npending里增加fd
* 对于kqueue来说,就是往kqfd里增加fd
* 对于select来说,就是往对应读写类型的fd_set里面增加fd
* 对于epoll来说,就是在events中增加/修改感兴趣的事件
* @param eventLoop 是为了接收回调数据
* @param fd 对应监听的fd值
* @param mask 类型
* @return int
*/
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
/**
* @brief 单位时间内监听到的事件数量
* @param eventLoop
* @param tvp 单位时间
* @return int 返回待处理的事件数量
*/
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
//删除事件
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)
static void aeApiFree(aeEventLoop *eventLoop)
//获取实现的名称
static char *aeApiName(void)
select和poll的缺点:
- 单个进程打开的fd是有限制的,通过fd_setsize设置,默认1024
- 每次调用select,都需要把fd集合从用户态copy到内核态
- 然后在内核遍历(线性扫描,采用轮训的方法)传递进来的fd集合;
epoll改进了select模式,避免了以上的几个缺点(事件驱动)
- epoll所支持的fd上限是最大可打开文件的数目,这个数字,可以在操作系统配置,通过ulimit -a查看(实际上redis通过MAX_ACCEPTS_PER_CALL限制了一次处理的请求数)
- epoll通过epoll_ctl函数,每次注册新的事件到epoll句柄的时候,都会把对应的fd copy到内核中,epoll保证了每个fd在整个过程中只copy一次;
- 默认通过LT模式遍历扫描:epoll_wait监测到fd事件发生后会通知应用程序,应用程序可以不立即处理该事件,下次调用会再次响应
redis的线程模型
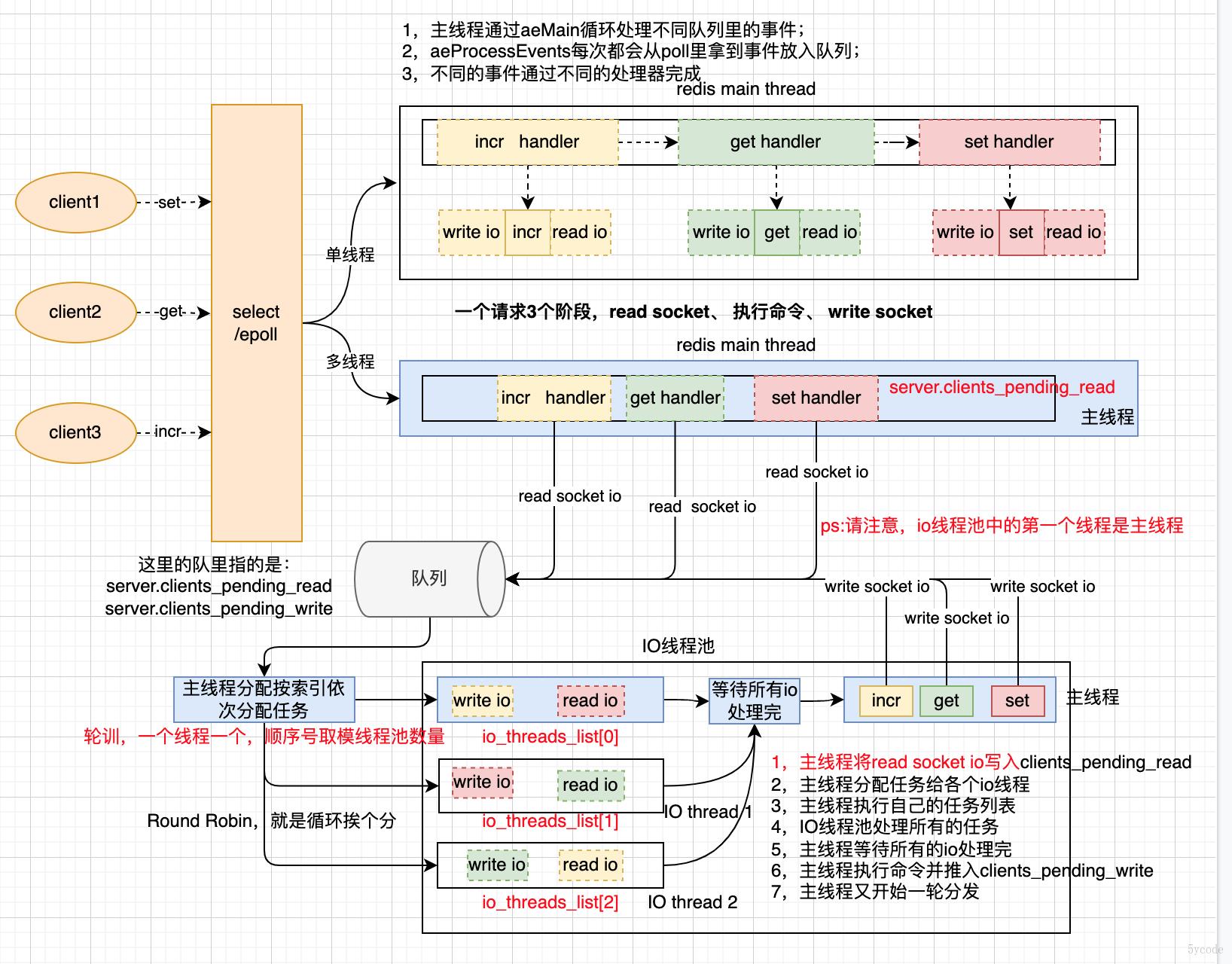
如上图:
- 5.0以及5.0之前的线程模型是单线程的,都是通过主线程在处理读I/O,执行命令,写I/O;
- 6.0以后,redis增加了一个工作线程组(主线程是工作线程的第一个线程)
- 主线程通过aeApiPoll从select/epoll中获取到就绪的事件读写事件(工作线程池,只处理读写I/O)
- 然后主线程将任务扔到队列里
- 主线程通过从队列获取数据依次分给工作线程池里的线程
- 通过计数器等待所有的线程执行完
- 然后主线程挨个执行对应的命令(有序性能保证)
- 主线程执行完命令后,将写I/O再次写入队列
- 然后再次按读I/O的模式处理
redis为什么那么快?
- 纯内存操作
- 使用I/O多路复用+事件模型+非阻塞I/O(利用操作系统的特性,性能高)
- 业务执行单线程模型(避免不必要的上下文切换)
- 高效的数据结构+合理的数据编码
redis 的发展史
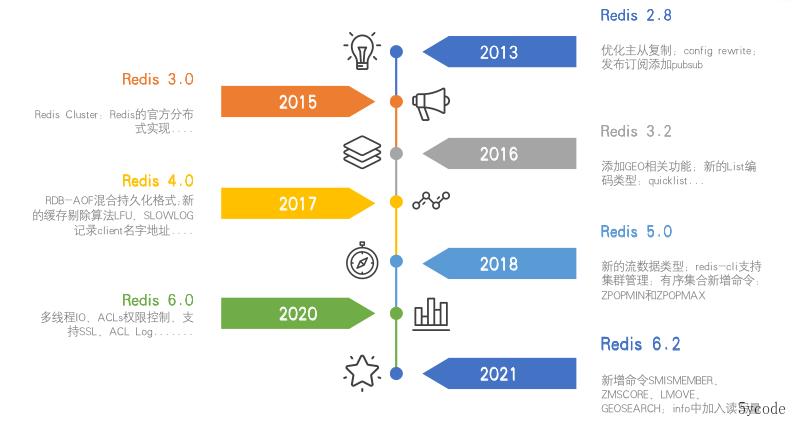
redis是如何运行的?
启动流程
精简流程

核心代码
void aeMain(aeEventLoop *eventLoop)
eventLoop->stop = 0;
//只要没有停止,就循环执行,这个是主线程
while (!eventLoop->stop)
if (eventLoop->beforesleep != NULL)
//每次循环前执行beforesleep
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
处理tcp请求
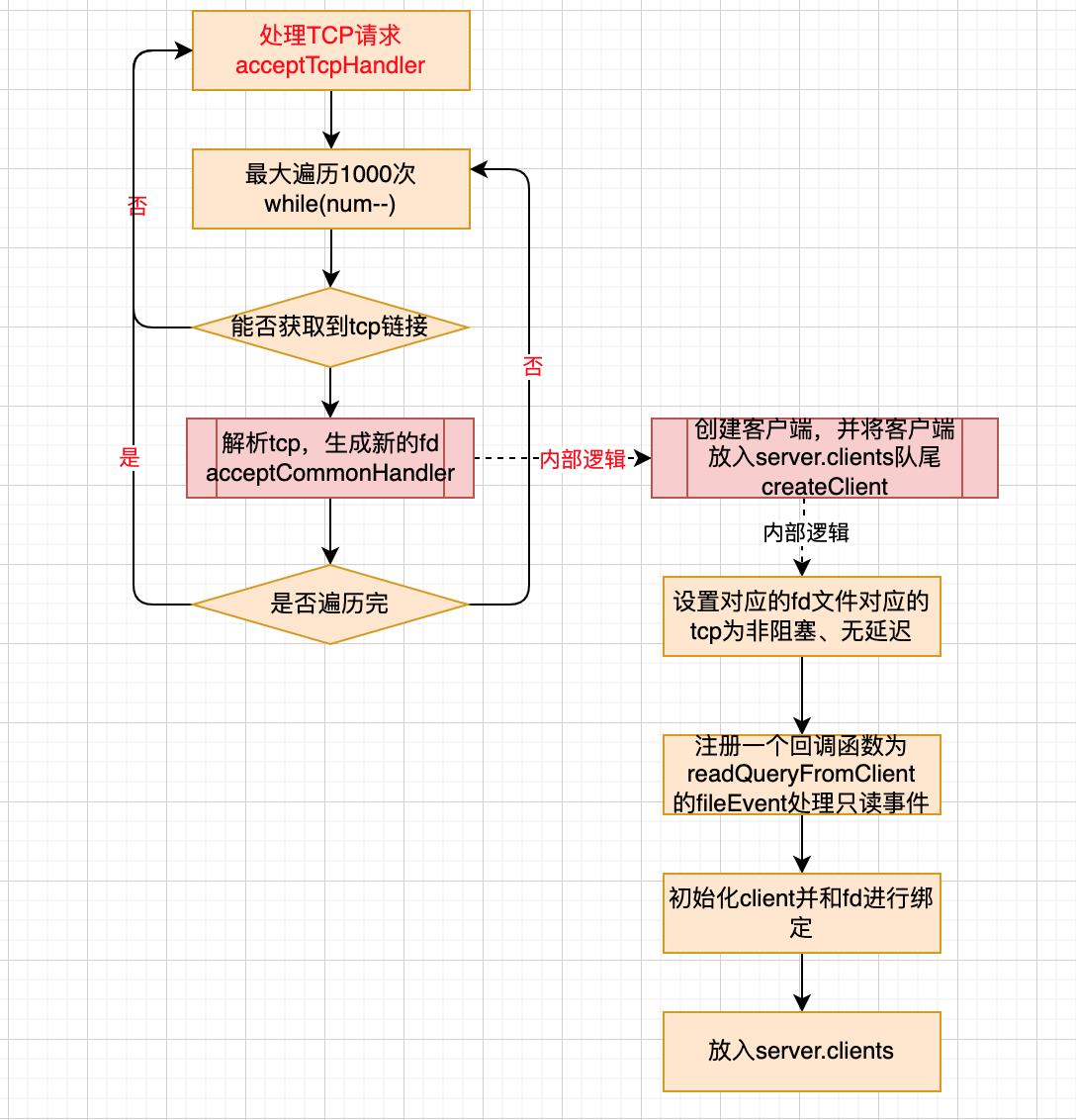
- 在这里将请求转换成了client,并生成了一个fd与其绑定
/**
* @brief tcp处理器
* @param el
* @param fd 当前tcp的fd
* @param privdata 对应epoll数据
* @param mask
*/
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask)
/**
* cport 当前的端口
* cfd 当前的fd
* max 一次最多处理1000个
*/
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
//取tcp请求
while(max--)
/**
* @brief 监听tcp socket ,获取一个新的fd,后续再研究下这里 TODO
* 新的fd就是一个有效的链接
*/
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR)
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
//针对新监听到的请求处理(创建一个client并将新生成的cfd与其绑定)
acceptCommonHandler(cfd,0,cip);
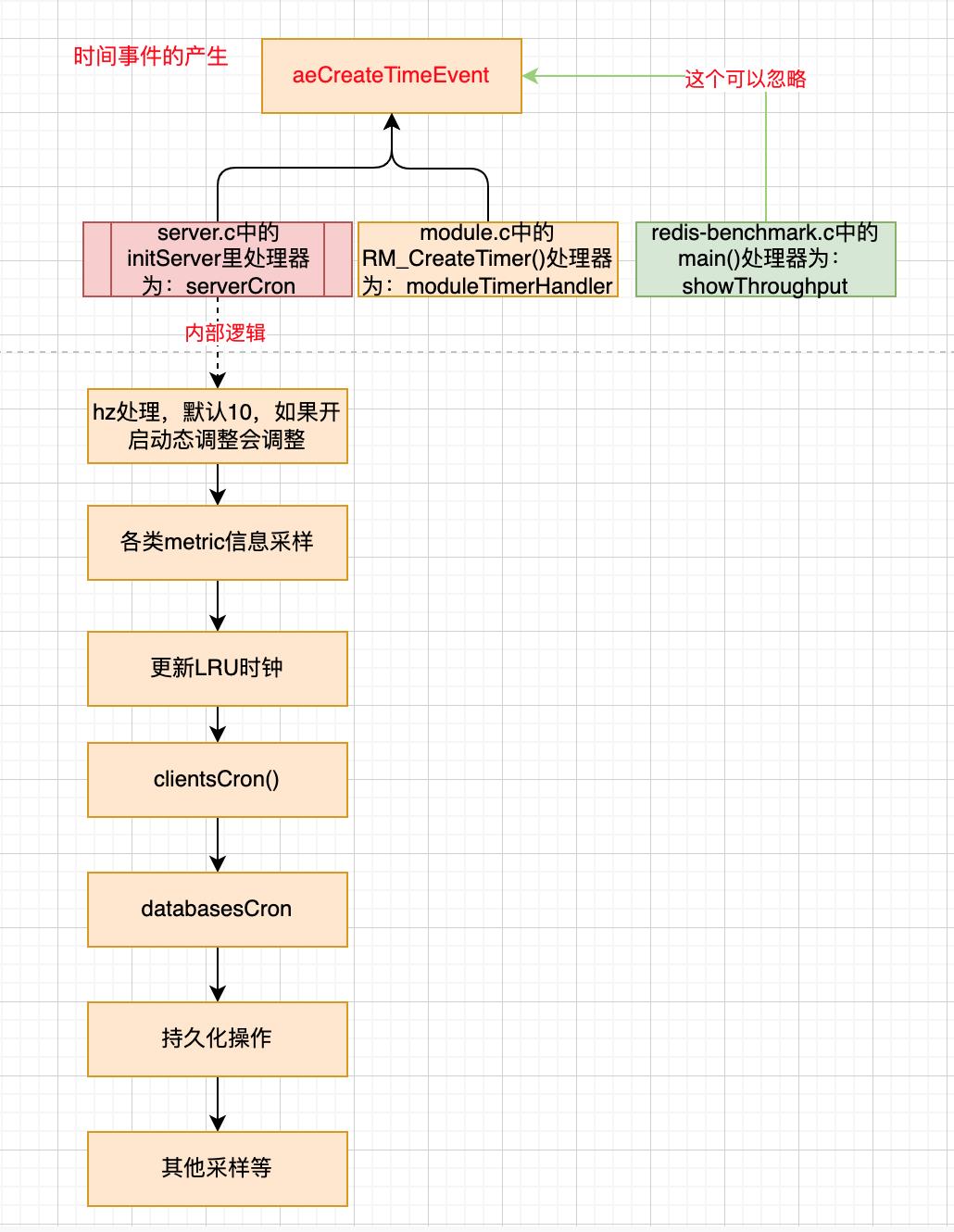
时间事件的产生
单线程启动流程

redis多线程启动流程

redis存储的基本结构

- 一个redisDb代表着一个数据库,默认redis配置16个DB;
- *dict 表示存储所有的key的;
- ht[0] 表示正常使用的hash通;
- redis通过拉链法解决hash冲突;
- entry 代表的是一个链表中的一个节点,包含key 和val的指针;
- key是一个sds类型的字符串(不预留空间,节省空间)
- val是一个包装的redisObj对象
- ht[1] 是redis在进行rehash的时候,临时存放的节点,rehash后会改到ht[0]
- ht[0] 表示正常使用的hash通;
- *expires 会存储一份带有过期时间的key;
- 结构和*dict中的一样
typedef struct dictEntry
void *key;
// v使用联合体,共用头部指针,正常是4选一,可以理解为java的泛型
union
void *val;
uint64_t u64;
int64_t s64;
double d;
v;
struct dictEntry *next;
dictEntry;
/**
* @brief redis对象的数据结构体,在监听到数据后,都会将key和value包装成这个对象
* OBJ_STRING -> OBJ_ENCODING_INT 使用整数值实现的字符串对象
* OBJ_STRING -> OBJ_ENCODING_RAW 使用sds实现的字符串对象
* OBJ_STRING -> OBJ_ENCODING_EMBSTR 使用embstr编码的sds实现的字符串
* OBJ_LIST -> OBJ_ENCODING_QUICKLIST 使用快速列表实现(混合了压缩列表和双端链表)
* OBJ_SET -> OBJ_ENCODING_HT 使用字典实现的集合
* OBJ_SET -> OBJ_ENCODING_INTSET 使用整数集合实现的集合
* OBJ_ZSET -> OBJ_ENCODING_ZIPLIST 使用压缩列表实现的有序集合
* OBJ_ZSET -> OBJ_ENCODING_SKIPLIST 使用跳表实现的有序集合
* OBJ_HASH -> OBJ_ENCODING_HT 使用字典实现的hash
* OBJ_HASH -> OBJ_ENCODING_ZIPLIST 使用压缩列表实现的hash
* OBJ_MODULE
* OBJ_STREAM -> OBJ_ENCODING_STREAM 使用stream实现
*/
typedef struct redisObject
//robj存储的对象类型,sting、list、set、zset等
unsigned type:4; //4位
// 编码,OBJ_ENCODING_RAW 0 OBJ_ENCODING_INT 1
unsigned encoding:4; //4位
/**
* @brief 24位
* LRU的策略下:lru存储的是 秒级时间戳的低24位,约194天会溢出
* LFU的策略下:24位拆为两块,高16位(最大值65535)低8位(最大值255)
* 高16存储的是 存储的是分钟级&最大存储位的值,要溢出的话,需要65535%60%24 约 45天溢出
* 低8位存储的是近似统计位
* 在lookupKey进行更新
*/
unsigned lru:LRU_BITS;
//引用次数,当为0的时候可以释放就,c语言没有垃圾回收的机制,通过这个可以释放空间
int refcount; //4字节
/**
* 指针有两个属性
* 1,指向变量/对象的地址;
* 2,标识变量/地址的长度;
* void 因为没有类型,所以不能判断出指向对象的长度
*/
void *ptr; // 8字节
robj;//一个robj 占16字节
typedef struct client
uint64_t id; /* Client incremental unique ID. */
int fd; /* Client socket. */
redisDb *db; /* Pointer to currently SELECTed DB. */
robj *name; /* As set by CLIENT SETNAME. */
//初始的时候,是一个空的sds,客户端累计的查询缓冲区大小,后续每次处理扩容16kb
sds querybuf; /* Buffer we use to accumulate client queries. */
//从querybuf读取的位置
size_t qb_pos; /* The position we have read in querybuf. */
//待同步到从库的缓冲区到小
sds pending_querybuf; /* If this client is flagged as master, this buffer
represents the yet not applied portion of the
replication stream that we are receiving from
the master. */
//上次查询缓冲区使用的大小
size_t querybuf_peak; /* Recent (100ms or more) peak of querybuf size. */
//参数数量
int argc; /* Num of arguments of current command. */
//参数的redisObject 数组
robj **argv; /* Arguments of current command. */
//客户端要执行的命令
struct redisCommand *cmd, *lastcmd; /* Last command executed. */
int reqtype; /* Request protocol type: PROTO_REQ_* */
int multibulklen; /* Number of multi bulk arguments left to read. */
long bulklen; /* Length of bulk argument in multi bulk request. */
/**
* @brief 链表对象是里面的节点对象是clientReplyBlock
* clientReplyBlock是一个数组
* 因为不知道缓冲区有多大,为了
*/
list *reply; /* List of reply objects to send to the client. */
unsigned long long reply_bytes; /* Tot bytes of objects in reply list. */
size_t sentlen; /* Amount of bytes already sent in the current
buffer or object being sent. */
time_t ctime; /* Client creation time. */
/**
* @brief 上次交互的时间,用于判断超时
*/
time_t lastinteraction; /* Time of the last interaction, used for timeout */
time_t obuf_soft_limit_reached_time;
.....
/* Response buffer */
int bufpos;
char buf[PROTO_REPLY_CHUNK_BYTES];
client;
redis支持的数据类型
Redis是一个开源,内存存储的数据结构服务,可用作数据库(不建议),高速缓存和消息队列等。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglog、stream等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
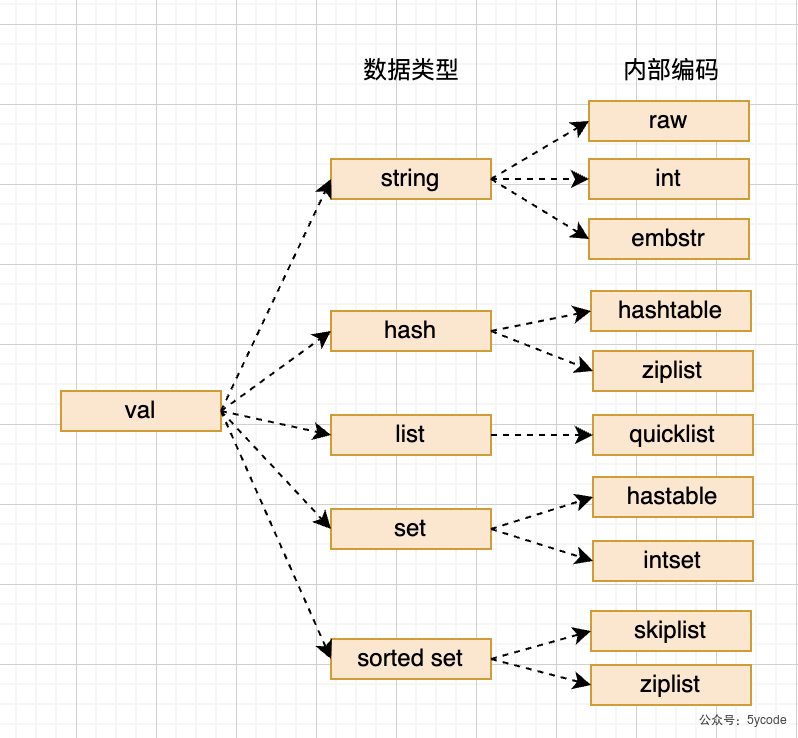
string (sds)
通过sds动态字符串编码实现。
- string类型分为embstr和raw两种编码,
- 小于44字节,用embstr编码(一次空间申请,空间紧凑)
- 大于44字节,使用raw编码
- 数值类型使用int编码
struct __attribute__ ((__packed__)) sdshdr8
//1字节 max= 255 已用空间(不同类型len占用的长度不同)
uint8_t len; /* used */
//1字节 申请的buf的总空间,max255(不包含flags、len、alloc这些)(不同类型len占用的长度不同)
uint8_t alloc; /* excluding the header and null terminator */
// 1字节 max= 255
unsigned char flags; /* 3 lsb of type, 5 unused bits */
// 字节数组+1结尾\\0
char buf[];
;//4+n 长度
struct __attribute__ ((__packed__)) sdshdr16
// 2字节 16位 max 65535(不同类型len占用的长度不同)
uint16_t len; /* used */
// 2字节 16位 申请的buf的总空间max 65535
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
;

sds高效在哪了?
必须了解下c语言的字符串。
- 在c语言中没有字符串的概念,只有一个字符数组
- c语言中字符串的结束以’\\0’ 标记,字符有多长?每次都得循环遍历到\\0 才能获取
- c语言的字符串不能存储二进制数据;
sds做了哪些优化?
- 将长度获取降为O(1),通过len可以直接获取存储的数据长度;
- 空间预分配
- 这也是redis里叫简单动态字符串的根因
- 由不同的sdshdr类型组成,其中len和alloc根据类型不同,占用的位数不同,buf数组就为申请空间的长度
- redis在创建字符串的时候,使用最小原则去匹配对应的sdshdr(ps:key的sds生成比较特殊,直接申请固定长度的空间len和alloc相同),未填满的空间就是预留的buffer;
- 当内容值改变的时候,如果改变后的值未超出总长度,就直接在对应的内存上操作,不会再申请新的空间,如果超过,就得变换类型
应用场景
- 缓存
- 计数器
- 共享session
- 分布式锁
list
redis3.2以后将list的压缩列表(ziplist)和双端链表(linkedList)改成了quicklist了。
-
quicklist融合了ziplist和linkedlist的功能;
-
默认一个quicklistNode是一个ziplist对象;
-
ziplist的大小有限制
- 不能保存过多的元素(否则O(n)的查询复杂度会很慢)
- 不能保存过大的元素(过大,装不了几个元素)
-
ziplist更新会比较麻烦(比如更新值不等于当前元素内存大小时,需要扩缩容,或挪移,如果多个连续更新,想下效率)
- 扩缩容,会引起数据的挪移,内存数据的搬迁
先看下原来ziplist的的创建,以及结构
/**
* @brief 创建一个空的压缩列表
*
* @return unsigned char*
*/
unsigned char *ziplistNew(void)
// <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
//压缩列表的结构大小 12+1
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
//申请13字节的空间,ziplist的 head + 结束标识的大小
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
//将列表尾设置为255
zl[bytes-1] = ZIP_END;
return zl;

再看下quicklist的源码和结构
typedef struct quicklist
//头节点指针
quicklistNode *head;
//尾节点指针
quicklistNode *tail;
//元素个数总和
unsigned long count; /* total count of all entries in all ziplists */
//快速列表的节点个数
unsigned long len; /* number of quicklistNodes */
//压缩列表的最大大小,初始化时用的,list-max-ziplist-size的值
int fill : 16; /* fill factor for individual nodes */
//结点压缩深度,初始化时用的 list-compress-depth 的值,0表示不压缩
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
quicklist;
/**
* 快速列表的节点结构
*/
typedef struct quicklistNode
//前驱节点指针
struct quicklistNode *prev;
//后继节点指针
struct quicklistNode *next;
//指向压缩列表的指针(当前节点被压缩,指向一个quicklistLZF结构的指针)
unsigned char *zl;
//压缩列表所占字节总数
unsigned int sz; /* ziplist size in bytes */
//压缩列表中的元素数量
unsigned int count : 16; /* count of items in ziplist */
//编码,原生字节数组为1,压缩存储为2
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//表示quicklistNode 节点是否采用ziplist结构保存数据,
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//是否再次压缩,不设置,表示ziplist结构,设置为1表示quicklistLZF,
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
quicklistNode;
typedef struct quicklistLZF
//表示被压缩后的ziplist的大小
unsigned int sz; /* LZF size in bytes*/
char compressed[];
quicklistLZF;

如上:
- quicklist解决了压缩列表插入扩缩容的问题(链表指针,不用考虑空间,不用考虑挪移)
- quicklist解决了压缩列表容量的问题,
应用场景
- 消息队列
- 文章列表
set
/**
* 创建set的工厂方法
* @param value
* @return
*/
robj *setTypeCreate(sds value)
//是一个long类型的,创建成intset
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
return createIntsetObject();
return createSetObject();
/**
* 创建一个普通hash表
* @return
*/
robj *createSetObject(void)
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;
return o;
/**
* 创建一个intset
* @return
*/
robj *createIntsetObject(void)
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
/**
* intset的数据结构
*/
typedef struct intset
//编码方式,可以是16位整数,32位整数,64位整数
uint32_t encoding;
//元素个数
uint32_t length;
//存储的是数组指针,按从小到大排列
int8_t contents[];
intset;
这里只介绍下intset
- 在intset中,保存的是当前intset最大的编码类型
- length是数组的长度
- contents 是数组的指针
- 按从小达到排列,不重复,具备唯一性
- 插入时通过二分查找定位
应用场景
-
唯一性
-
共同(好友、独立ip、标签)
zset
主要讲解下跳跃表结构,压缩表不讲解
/**
* 跳跃表节点
*/
typedef struct zskiplistNode
//member对象
sds ele;
//权重分值
double score;
//后退指针
struct zskiplistNode *backward;
//层级描述
struct zskiplistLevel
//前进指针
struct zskiplistNode *forward;
//跨越节点的数量
unsigned long span;
level[];
zskiplistNode;
/**
* zset的数据结构跳跃表
*/
typedef struct zskiplist
//头尾节点指针
struct zskiplistNode *header, *tail;
//节点数量
unsigned long length;
//最大层数
int level;
zskiplist;
/**
* 跳表结构的zset
*/
typedef struct zset
//kv形式,存储所有的member和对应的score
dict *dict;
//跳跃表
zskiplist *zsl;
zset;
zadd添加数据流程
我们从源码zadd看下zset命令(精简后的源码),在t_zset.c中
void zaddGenericCommand(client *c, int flags)
//不存在,就创建
if (zobj == NULL)
/**
* 根据redis的配置,如果有序集合不使用ziplist存储或者第一次插入元素的个数大于设置的ziplist最大长度,则使用跳表
*/
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
//这里创建了一个score为0,层级为64的元素为null的 头节点
zobj = createZsetObject();
else
zobj = createZsetZiplistObject();
//插入entry到hash表
dbAdd(c->db,key,zobj);
else //存在,校验类型,不是zset,报错
if (zobj->type != OBJ_ZSET)
addReply(c,shared.wrongtypeerr);
goto cleanup;
//遍历所有的<element,score>
for (j = 0; j < elements; j++)
double newscore;
score = scores[j];
int retflags = flags;
//获取元素数据的指针
ele = c->argv[scoreidx+1+j*2]->ptr;
//添加元素到zset,在zsetAdd 方法里进行了类型区分
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0)
addReplyError(c,nanerr);
goto cleanup;
//根据操作类型计数
if (retflags & ZADD_ADDED) added++以上是关于redis详解(内部分享版)的主要内容,如果未能解决你的问题,请参考以下文章