SparkRDD转换操作
Posted 会编程的李较瘦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkRDD转换操作相关的知识,希望对你有一定的参考价值。
1.reduceByKey(func)
合并具有相同键的值。
在 spark-shell 中输入如下代码:

截图如下:

2.groupByKey()
对具有相同键的值进行分组。
在 spark-shell 中输入如下代码:

截图如下:

3.mapValues(func)
对键值对 RDD 的每个值应用一个函数而不改变对应的键。
在 spark-shell 中输入如下代码:
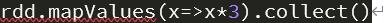
截图如下:

flatMapValues(func)
对键值对 RDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录,通常用于符号化。
在 spark-shell 中输入如下代码:
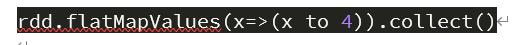
截图如下:

keys()
返回一个仅包含所有键的 RDD。
在 spark-shell 中输入如下代码:

截图如下:

values()
返回一个仅包含所有值的 RDD。
在 spark-shell 中输入如下代码:

截图如下:

sortByKey()
返回一个根据键排序的 RDD。
在 spark-shell 中输入如下代码:

截图如下:

combineByKey(createCombiner,mergeValue,mergeCombiners)
combineByKey() 是键值对 RDD 中较为核心的高级函数,很多其它聚合函数都是在这个之上实现的,通过使用 combineByKey() 函数,我们能够更加清楚的明白 spark 底层如何进行分布式计算。其中这 3 个参数分别对应着聚合操作的 3 个步骤。
combineByKey() 会遍历分区的所有元素,在这个过程中只会出现两种情况:一种是该元素对应的键没有遇到过;另外一种是该元素对应的键和之前的某一个元素的键是相同的。
如果是新的元素,combineByKey() 会使用 createCombiner() 函数来创建该键对应累加器的初始值。注意,是在每一个分区中第一次出现新键的时候创建,而不是在整个 RDD 中。
在当前分区中,如果遇到该键是已经存在的键,那么就调用 mergeValue() 方法将该键对应累加器的当前值与这个新的值合并。
由于有多个分区,每个分区都是独立处理的,所以最后需要调用 mergeCombiners() 方法将各个分区的结果合并。
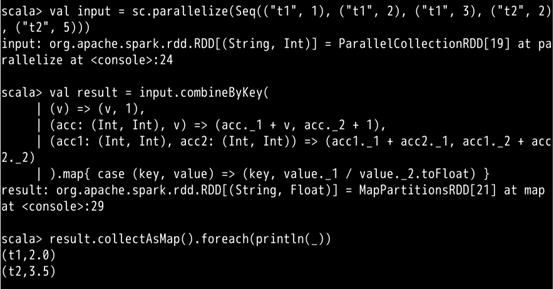
下面我们来看一个实际的例子,在 spark-shell 中输入如下代码:
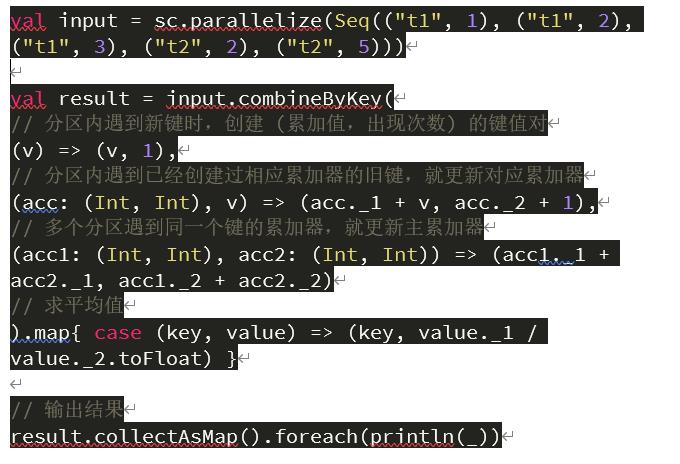
对应截图如下:
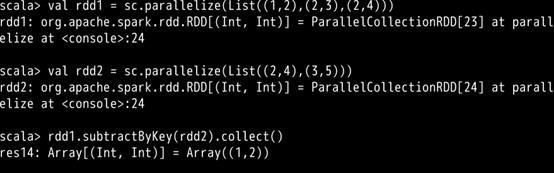
subtractByKey()
删掉 RDD1 中键与 RDD2 的键相同的元素。
在 spark-shell 中输入如下代码:

截图如下:
cogroup()
将两个 RDD 中拥有相同键的数据分组到一起。
在 spark-shell 中输入如下代码:

截图如下:

以上是关于SparkRDD转换操作的主要内容,如果未能解决你的问题,请参考以下文章