斯坦福大学数据可视化课程学习笔记:第二节 从数据到图像
Posted 玄魂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福大学数据可视化课程学习笔记:第二节 从数据到图像相关的知识,希望对你有一定的参考价值。

《斯坦福大学数据可视化课程学习笔记》课程资源来自于斯坦福大学数据可视化课程,是我所在团队实习生提升计划的一部分。本系列是 “秉姝” 同学在学习过程中记录和整理的学习笔记,希望这些笔记也能够帮助更多朋友了解和学习数据可视化。
第一节:斯坦福大学数据可视化课程学习笔记:第一节 可视化的发展与目标
数据可视化的过程 —— 从数据模型到图像模型
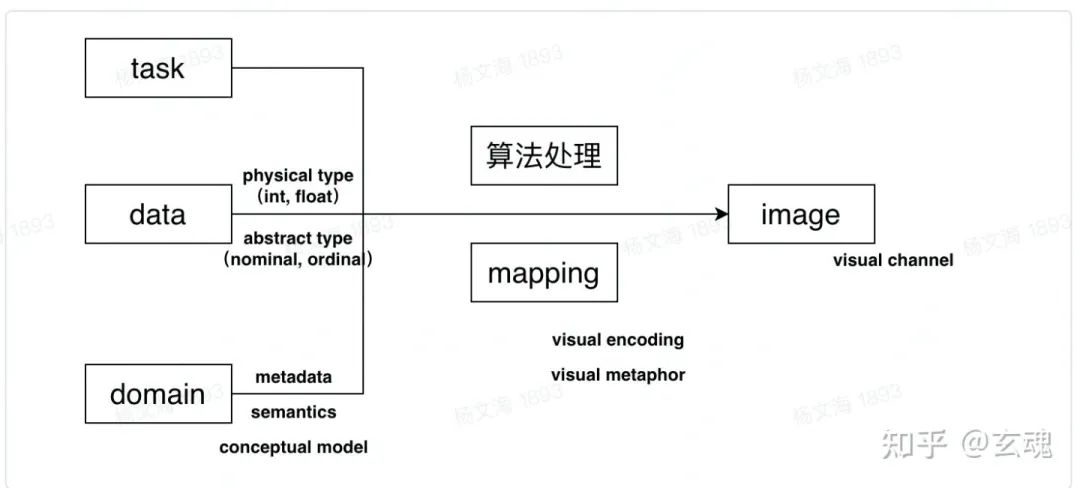
绘制图表的过程可以总结为:根据任务目的、数据、数据含义,通过算法与视觉映射,从而得到最终的图像。如上面的流程图所示,展示了绘制一张图表的整体流程分为三个阶段:
数据阶段
映射阶段
图像阶段。
接下来,我们将分别讲述这三个阶段内的主要概念。
数据 Data
巧妇难为无米之炊,数据就是可视化的“米”,数据可视化的目的就是展现数据的特征,辅助探索数据背后的秘密。

原始数据的分类
获取原始数据是可视化过程的第一步。原始数据可分为 数据模型(Data models)和 概念模型(Conceptual models)。
数据模型为可计算的数值。例如我们在原始数据中获取了这样一组浮点数 [24.3, 19.2, 21.3, 22.5, 24.1]。概念模型为支持分析的语义化数据。数据模型中的浮点数并不能支持我们进行数据分析,我们还需要知道这组浮点数的含义,概念模型就是支持分析的语义化数据,例如“一周中每天的最高气温”就是概念模型,明确了上面这组浮点数的含义。
数据模型的类型
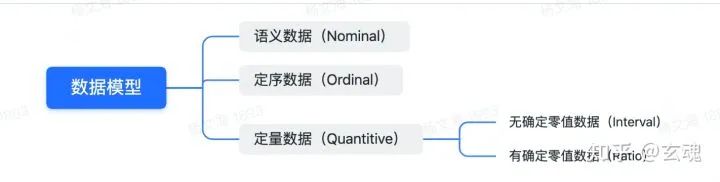
数据模型的数据又可以分为 语义数据(Nominal)、定序数据(Ordinal)以及定量数据(Quantitive),定量数据又可以进一步分为无确定零值数据(Interval)与有确定零值数据(Ratio)。
语义数据(N)
语义数据是指不具有数值属性的、相互独立的离散数据,它描述事物的性质,是数据的标签与分类。
语义数据支持的运算类型仅包括 == !== 两种,也就是只能进行相等和不相等的比较。
如性别[F, M]、国家[China, Japan, US,...]、工种[Programmer, Teacher, Saler,...]等都属于语义数据。
定序数据(O)
定序数据也是描述事物性质的数据,与语义数据不同的是,定序数据在分类的基础上有了明确的顺序。定序数据在 == !== 之外,还能够支持> <的比较。
如受教育程度[Bachelor, Master, Doctorate]、评级[Grade A, Grade B, Grade C]等属于定序数据。
定量数据(Q)
定量数据简单来讲就是数字,又可以根据有无零值的差异进一步分为“Interval”和“Ratio”两种类型。
Interval无确定零值数据。支持的运算包括==!==<><=>=-,也就是可以相减比较差值但不可以累加。例如地理位置点的坐标就是无确定零值的定量数据。Ratio有确定零值数据。支持==!==<><=>=-/的运算。例如长度、数量等就是有确定零值的定量数据。
数据阶段的目标
在数据模型处理阶段,我们会根据原始数据中的 数据模型 和 概念模型, 得到一组相关的、不同类型(语义、定序、定量 )的数据。
图像 Image
图像是可视化的结果,用直观的方式展现数据的特征。
图元 Marks
简单来说,图元就是用来展示数据的图形元素。
图元是基础的几何图形,如基础的点、线、面就是图元。

视觉变量 Visual Variables
视觉变量是控制图元展示的属性,如位置、大小、颜色、形状等就是视觉变量。
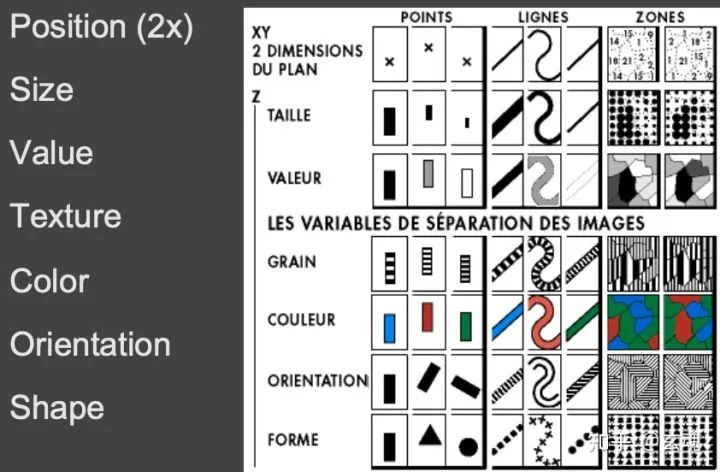
视觉映射 Encoding
视觉映射是数据与图像之间的桥梁,它将“数据模型”映射到“图像模型”,也就是“为不同类型的数据选择适合它的视觉变量”。
比例尺函数 Scale
映射实际上是一个函数,这个函数比例尺 Scale。Scale 将数据值(例如数字、日期等)映射到视觉变量值(颜色、宽高等)。Scale 描述了定义域(domain)与值域(range)之间的映射关系,搭建了用户数据到图形属性之间的桥梁。
Scale 的定义
以一个简单的柱状图为例,我们将一组数据映射到对应的视觉变量。需要映射的原始数据为:
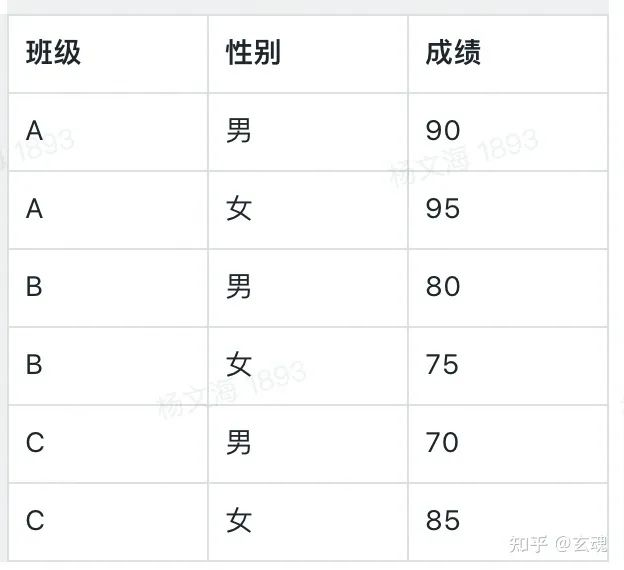
假设我们期望将“性别”数据变量映射到“颜色”视觉变量,其中,性别“男”将映射到蓝色,性别“女”将映射到红色。此时我们就得到了这一映射关系的 定义域 和 值域:
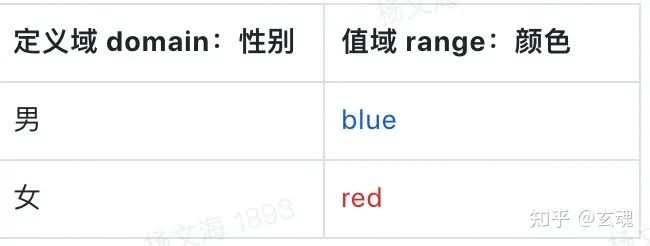
比例尺也即是对这一映射关系的描述,我们可以将它简单视作为一个函数:
// scale 的功能示例(非源码)
// 假设我们已经有一个实现了上述映射关系的scale:colorScale
var colorScale;
colorScale('男') === 'blue';
colorScale('女') === 'red';通过这一比例尺,我们可以得到每个数据所对应图元的颜色数据,绘制结果示例:
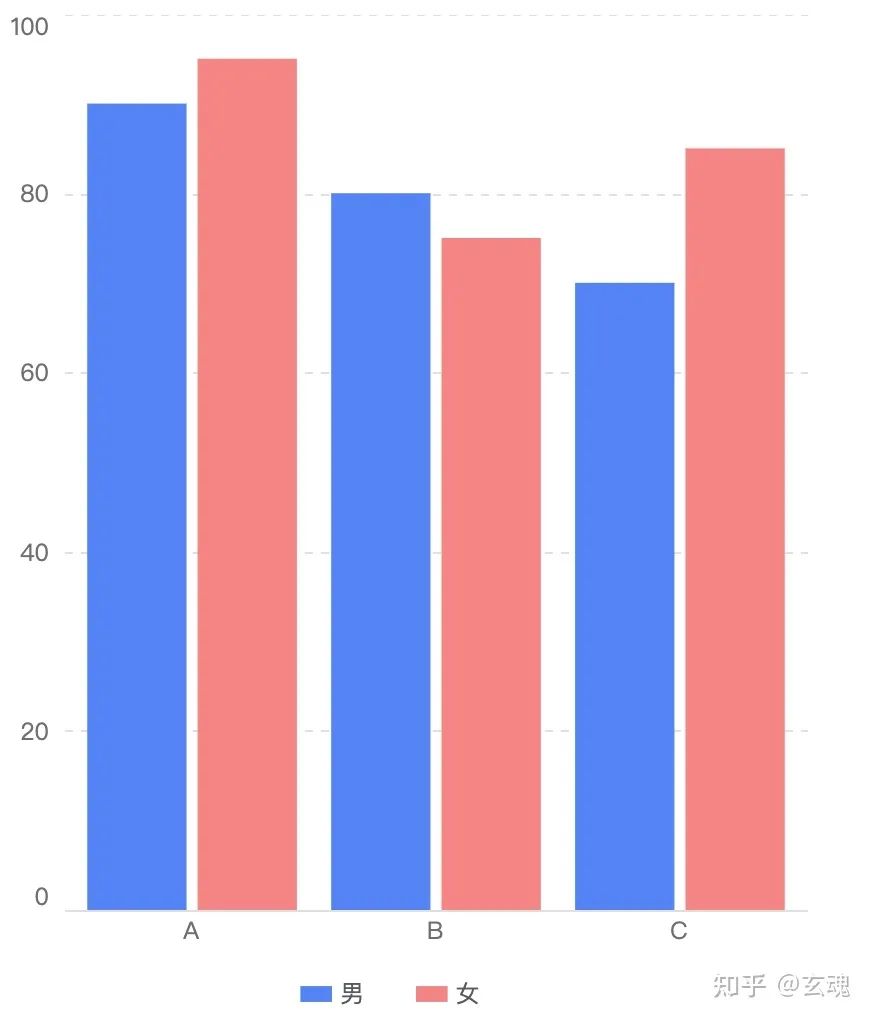
可以看到,所有数据所对应的柱子都依据性别绘制了相应的颜色。相类似的,原始数据中“班级”的属性映射到了柱子的 X 坐标,“成绩”的属性映射到了柱子的 Y 坐标。
Scale 的类型
依据定义域和值域数据类型以及映射方式的区别,可以将比例尺分为多种类型。本节内容描述了 几种常见比例尺类型。
Linear Scale
Linear Scale 将连续值(Q-Linear)线性映射到连续值的视觉变量,常用于宽高、XY坐标等数值的映射。
我们可以通过 linear scale 将成绩数值映射到柱状图中柱子的高度。需要映射的原始数据为:
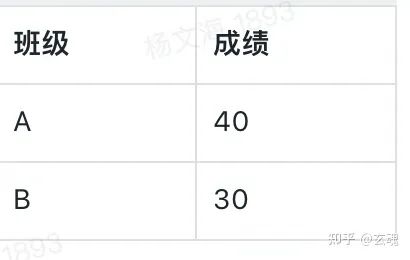
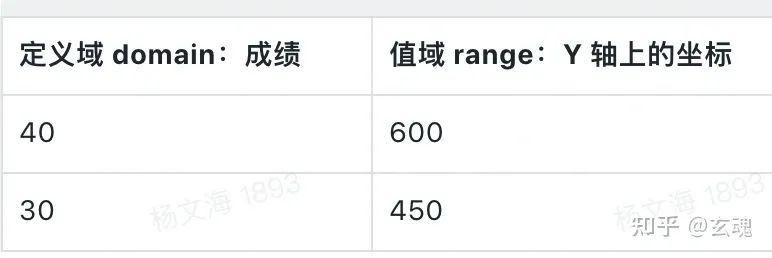
为了使得 linear scale 从成绩为 0 开始描述数据,我们将 linear scale 的值域设置为 0 到原始数据中成绩的最大值(范围为 0 - 40),值域设置为柱子的高度(范围为 0 - 600px)。相应的映射结果为:
相应的柱状图渲染结果为:
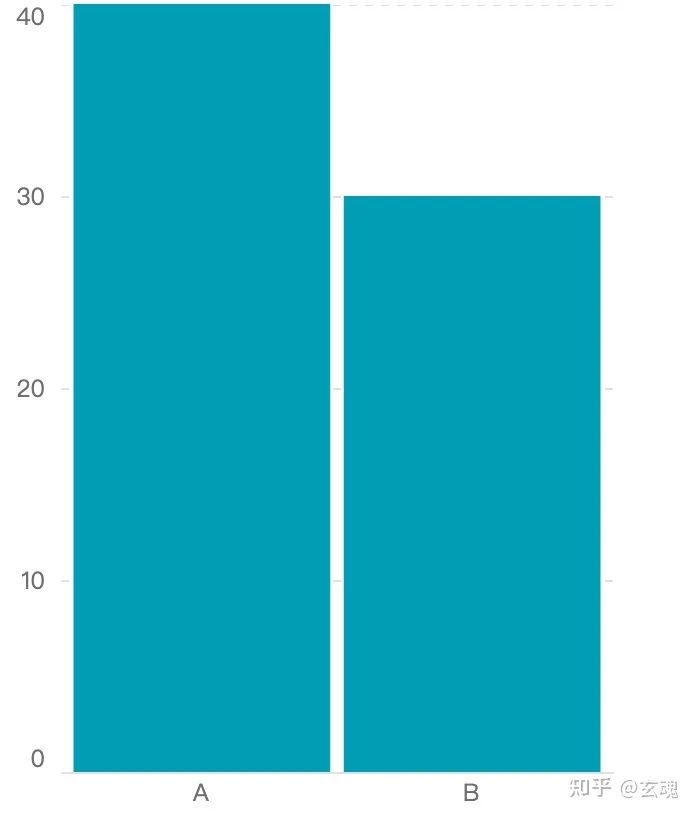
Ordinal Scale
Ordinal Scale 将离散值(O)映射到离散值的视觉变量,例如将离散的性别维度映射到离散的颜色值。
我们可以通过 ordinal scale 将原始数据中性别映射到颜色值,如快速上手中所描述的例子,这里不再赘述。
BandScale
Band Scale 与 Ordinal Scale 相类似,同样接收离散的值域(O),但是将其映射为连续的数值范围,例如柱状图中原始数据会被映射到连续X轴上的一个个柱子宽度的范围。
Band Scale 的映射结果如下图所示(图片来源于d3/d3-scale):
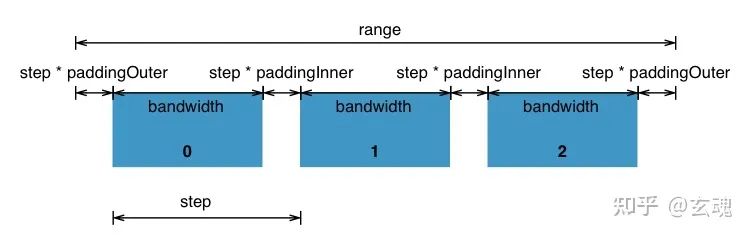
其中 bandwidth 代表映射后数据对应的宽度,paddingOuter 代表开始以及结果部分的边距,paddingInner 代表每一个映射结果之间的间距,step 则是一个 bandwidth 与 paddingInner 的和。
我们可以通过 band scale 将离散的时间数据映射到柱状图中 X 轴上柱子的排布。映射的定义域为原始数据中的时间属性,值域为 X 轴(范围为 0 - 800px),paddingOuter 以及 paddingInner 均设置为 0.4,相应的映射结果为:
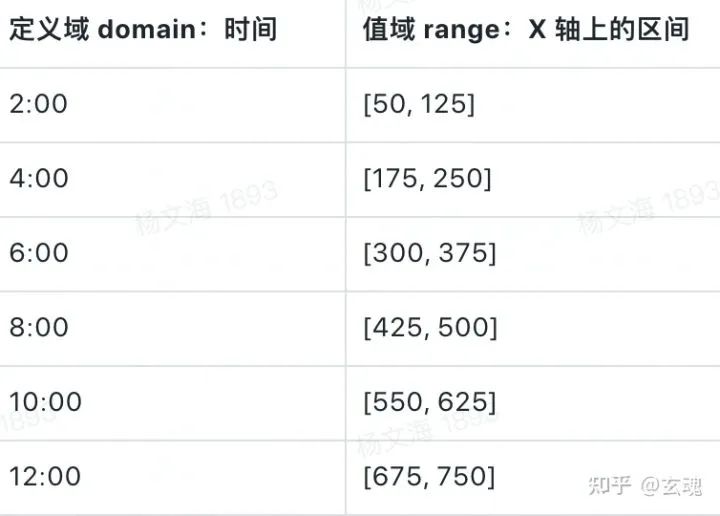
相应的柱状图渲染结果为:
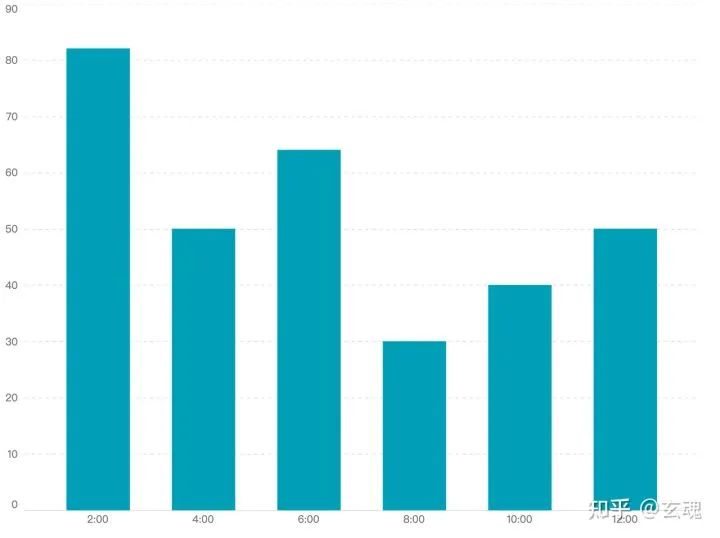
Point Scale
Point Scale 本质上是 Band Scale 的一个变种,其所有的 band width 都被固定为 0,例如折线图中原始数据会被映射到连续X轴上的一个个X坐标。
Point Scale 的映射结果如下图所示(图片来源于d3/d3-scale)。
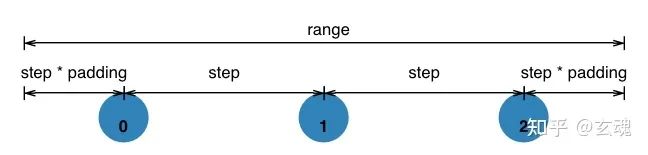
其中,padding 代表开始与结尾部分的边距,step 代表每一个映射结果之间的间距。
我们可以通过 point scale 将离散的时间数据映射到折线图中 X 轴上的坐标。映射的定义域为原始数据中的时间属性,值域为 X 轴(范围为 0 - 800px),padding 设置为 0.4,相应的映射结果为:
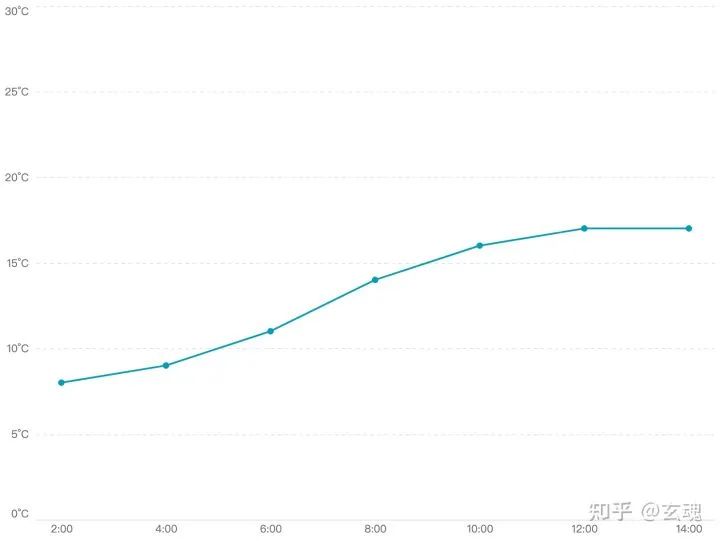
视觉变量的精确度
人眼对图形各属性的识别度能力有差异,因此各视觉变量在表示数据的准确度有所不同。一般来说,位置、长度的准确度高,倾斜度、角度、面积、体积的准确度相对较低,色彩的准确度最低。

视觉变量的有效性
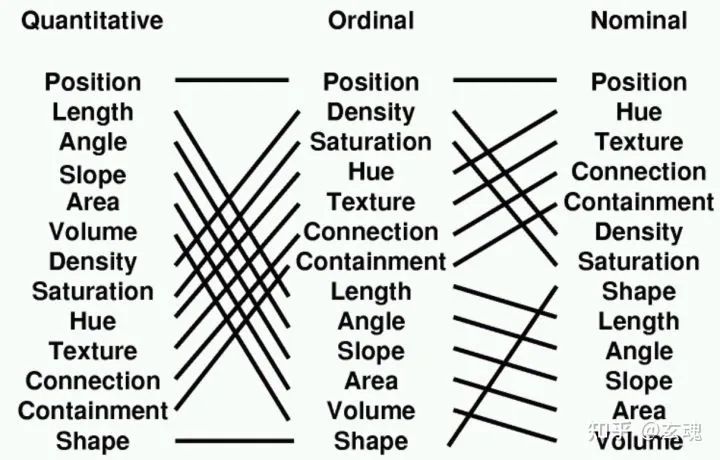
对于不同类型的数据(语义、定序、定量 ),当用不同的视觉变量表达时,人们对信息的理解成本也会有高低之分。对于特定类型的数据,如果一个视觉变量表达的理解成本要低于另一种视觉变量,就可以说这个视觉变量对于该类型数据表达的“有效性”更高。
语义数据对语义类型的数据来说,位置、色相是最有效的变量,长度、角度、面积等变量就不适合语义类数据的表达。定序数据对定序类型的数据来说,因其具有可排序的特点,位置、饱和度是更有效的变量。定量数据对定量数据来说,因其可计算可比较的特点,位置、长度、角度、面积等变量的有效性更高。
选取视觉变量的原则
视觉变量的选取要遵循两个原则:
一致性原则(视觉变量与数据属性相符)
优先级原则(最重要的数据要用最有效的视觉变量呈现)
下面这张图表的设计违反了“一致性原则”,这张图表的意图是展示各品牌汽车所属的国家,国家是语义数据,品牌也是语义数据,但是这张图表选取了“长度”来表达品牌,长度作为视觉变量,适合于定量数据的表达,这幅图中,柱状图柱子的长度会对读者带来误导。

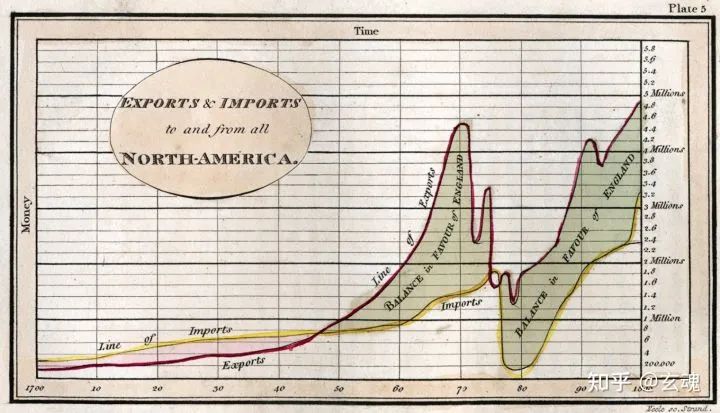
下图为 Playfair 绘制的英国进出口贸易额图表。这张图表中包含的数据变量有:
时间(Q)、贸易额(Q)、进出口类型(N)、贸易差额(Q)、贸易差类型(N)
按照一致性和优先级,以上数据变量分别映射到相应的视觉变量:
时间(Q):x-position
贸易额(Q):y-position
进出口类型(N):color
贸易差额(Q):area
贸易差类型(N):color
小结
本章内容介绍了可视化的整体过程:数据、映射与图像,介绍了比例尺函数 Scale 的含义,并讲述了如何依据数据变量的类型,为其选择合适的视觉属性。
系列文章,欢迎关注:
以上是关于斯坦福大学数据可视化课程学习笔记:第二节 从数据到图像的主要内容,如果未能解决你的问题,请参考以下文章