将 MVAD 的标注数据转成 CSV(Youtube Clips 的数据格式)
Posted chenxp2311
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了将 MVAD 的标注数据转成 CSV(Youtube Clips 的数据格式)相关的知识,希望对你有一定的参考价值。
Preface
目前我正在处理几个 Video Caption 的数据集,一个是 YoutubeClips 数据集。其标注是微软发布的一个 Microsoft Research Video Description Corpus
,安装完成后,会得到一个 CSV 文件,这个文件如下:
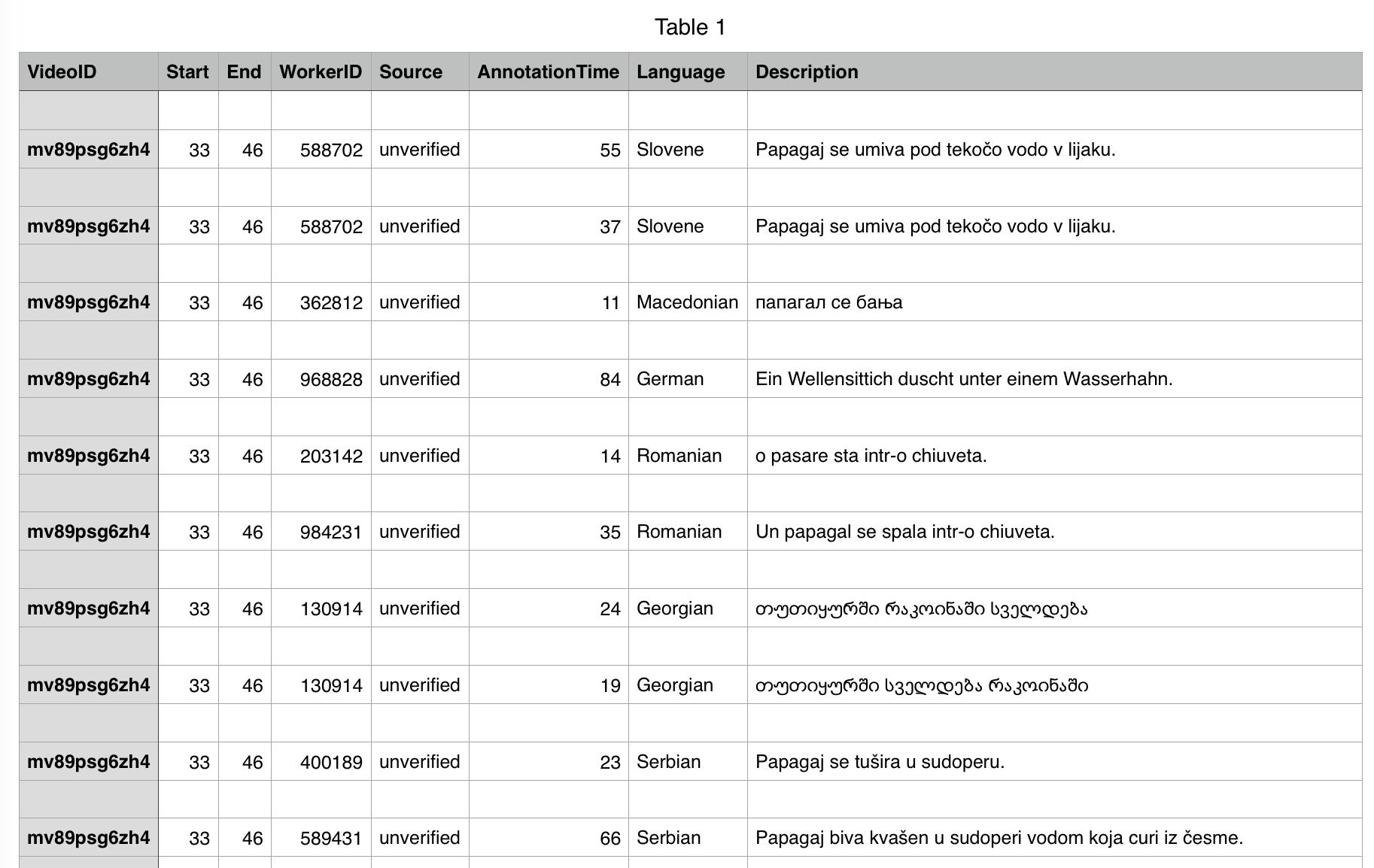
第一列是视频名称,第二列 Start 是标注的开始帧数,第三列 End 是标注的结束帧数,第七列 Language 是标注的语言,最后一列是标注文字内容。
但是,另一个数据集:MVAD: Montreal Video Annotation Dataset,其标注格式是 srt 格式的文件,形式如下:
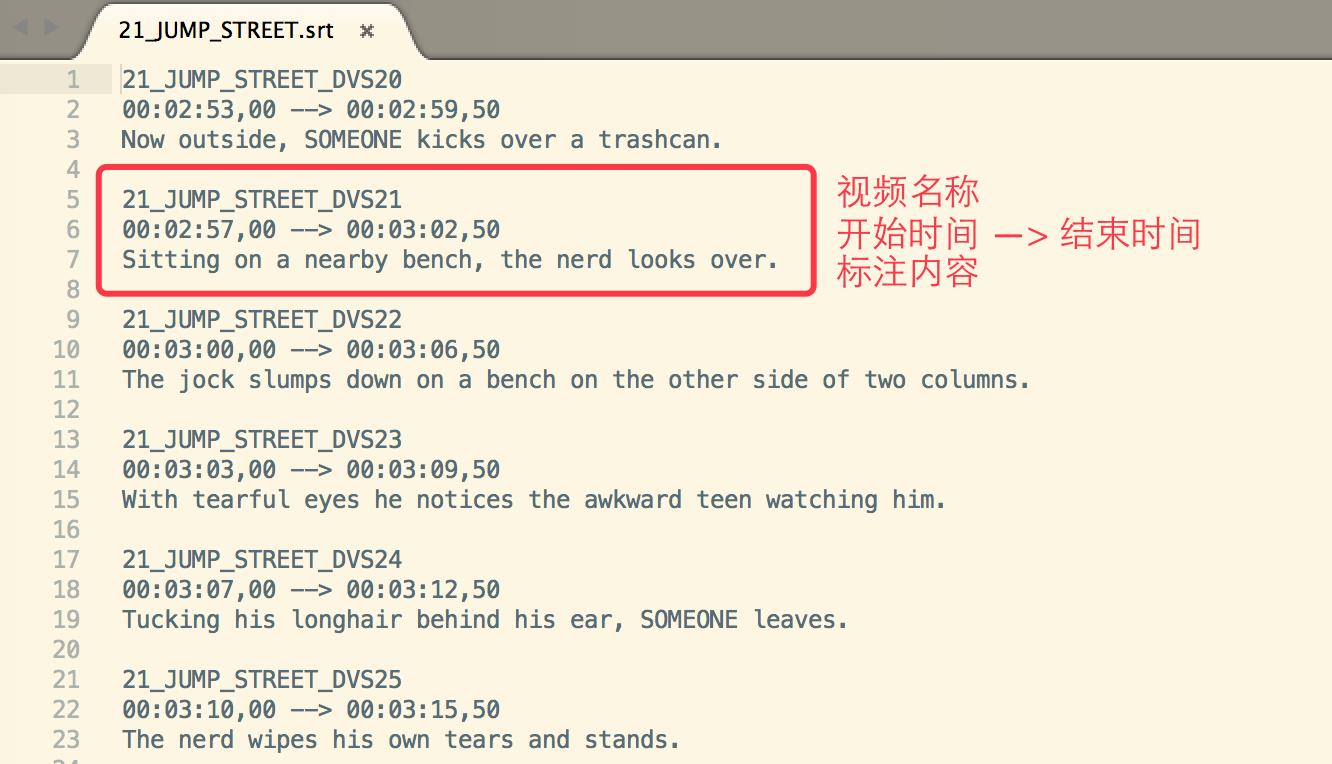
那么,要想用重复利用训练 YouTubeClips 的代码,就得讲 MVAD 的数据格式转化为 CSV 文件。
这个转化就得用上传说中的 pandas 模块了。我之前没接触到 pandas,这也是第一次使用吧。其实这个模块很方便很简单,我写了一段脚本进行转换,并保存为 CSV 文件,代码如下。
Code
#! encoding:UTF-8
import os
import glob
import cv2
import numpy as np
import pandas as pd
train_videos_path = '/home/ou-lc/chenxp/Downloads/MVAD/train_videos'
train_srt_txt_path = '/home/ou-lc/chenxp/Downloads/M-VAD_txtfiles/srt_files/train_srt'
train_txt_files = glob.glob(train_srt_txt_path + '/*.srt')
video_information = []
for each_train_srt in train_txt_files:
train_srts = open(each_train_srt, 'r').read().splitlines()
videos_ID = []
#videos_Time_Stamp = []; videos_Start = []; videos_End = []
videos_Language = []
videos_Descriptions = []
for idx_srt, video_srt in enumerate(train_srts):
if idx_srt % 4 == 0:
videos_ID.append(video_srt)
#if idx_srt % 4 == 1:
# videos_Time_Stamp.append(video_srt)
if idx_srt % 4 == 2:
videos_Language.append('English')
videos_Descriptions.append(video_srt)
for idx, each_video_name in enumerate(videos_ID):
video_information.append((each_video_name, videos_Language[idx], videos_Descriptions[idx]))
df = pd.DataFrame(video_information, columns=['VideoID', 'Language', 'Description'])
print df.shape
df.to_csv('convert_MVAD_train.csv', sep=',', encoding='utf-8')Reference
以上脚本的两处关键代码参考了如下资料:
1. http://stackoverflow.com/questions/16923281/pandas-writing-dataframe-to-csv-file
2. http://stackoverflow.com/questions/19961490/construct-pandas-dataframe-from-list-of-tuples
以上是关于将 MVAD 的标注数据转成 CSV(Youtube Clips 的数据格式)的主要内容,如果未能解决你的问题,请参考以下文章